标签:使用 mod 感受 网络学习 设计 proc war 分类 term
ThunderNet是旷视和国防科技大学合作提出的目标检测模型,目标是在计算力受限的平台进行实时目标检测。需要关注的地方主要就是提出的两个特征增强模块CEM和SAM,其设计理念和应用的方法都非常值得借鉴。
在移动端的实时目标检测是一个极为重要并且有挑战性的视觉问题。很多基于CNN的检测器都有巨大的计算量,所以在计算受限的场景下难以进行实时推理。论文提出了一个轻量级的两阶段的检测方法-ThunderNet。
最终ThunderNet可以在ARM设备上达到24.1fps的速度,精度和速度上超过了很多一阶段检测器。
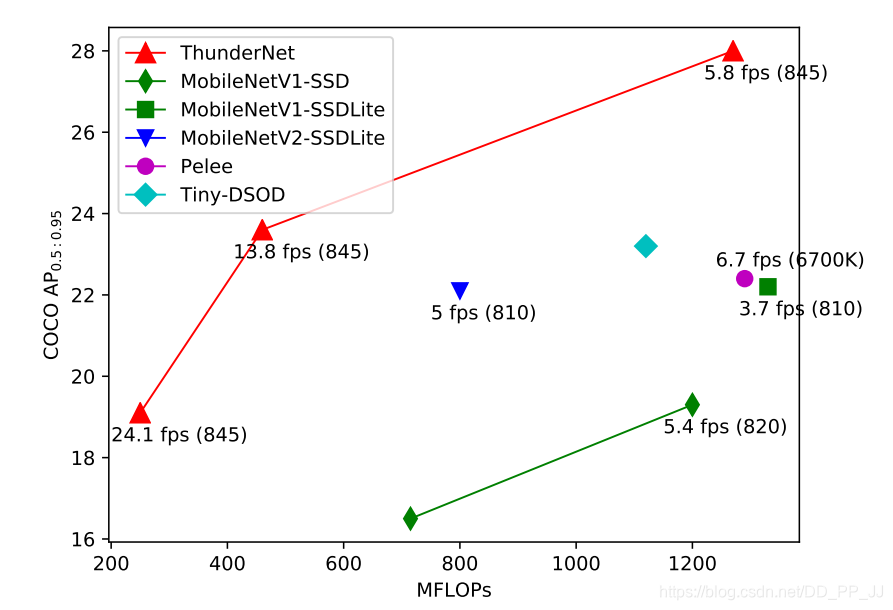
首先可以看一下在COCO数据集上轻量级目标检测网络的对比,可以看出来其效率和准确率都超过了Pelee,SSD等一阶段的检测器。
ThunderNet的Backbone是基于ShuffleNetv2改进得到的SNet。 由于输入的分辨率应该和backbone的容量相匹配,图片的输入分辨率调整为320x320,这极大的降低了模型的计算量。
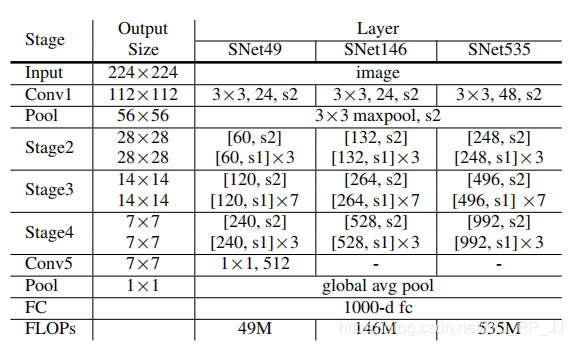
SNet与ShuffleNetV2区别在于SNet将ShuffleNet中所有的3x3的可分离卷积替换为5x5的可分离卷积。下图是shuffleNetv2中的网络结构:
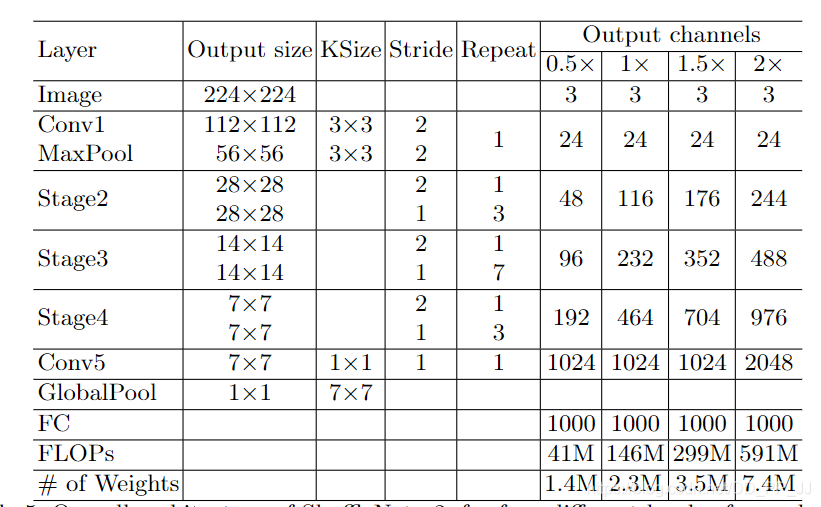
Backbone选取考虑到以下几个因素:
迁移学习: 目标检测需要的backbone一般都是在ImageNet上与训练得到的,但是目标检测的backbone和分类器所需要提取的特征是不一致的,简单地将分类模型迁移学习到目标检测中不是最佳选择。
感受野: CNN中感受野是非常重要的参数,CNN只能获取到感受野以内的信息,所以更大的感受野通常可以获取更多地语义信息,可以更好地编码长距离关系。
浅层和深层的特征: 浅层的feature map分辨率比较大,获取到的是描述空间细节的底层特征。深层的feature map分辨率比较小,但是保存的是更具有鉴别性的高级语义特征。
通常来讲,对于比较大的backbone来说,定位要比分类难得多,这样就证明了浅层特征对于定位的重要性。但是对于非常小的backbone来说,其特征表达能力比较差,这样就限制了准确率的特征。所以深层和浅层的特征都非常重要。
作者考虑到以上三个因素,并分析了先前轻量级backbone的缺点:
所以在设计SNet的时候,着重考虑以上的因素,并提出了三个模型:SNet49(speed)、SNet146(trade off)、SNet535(accuracy)。主要改进点如下:
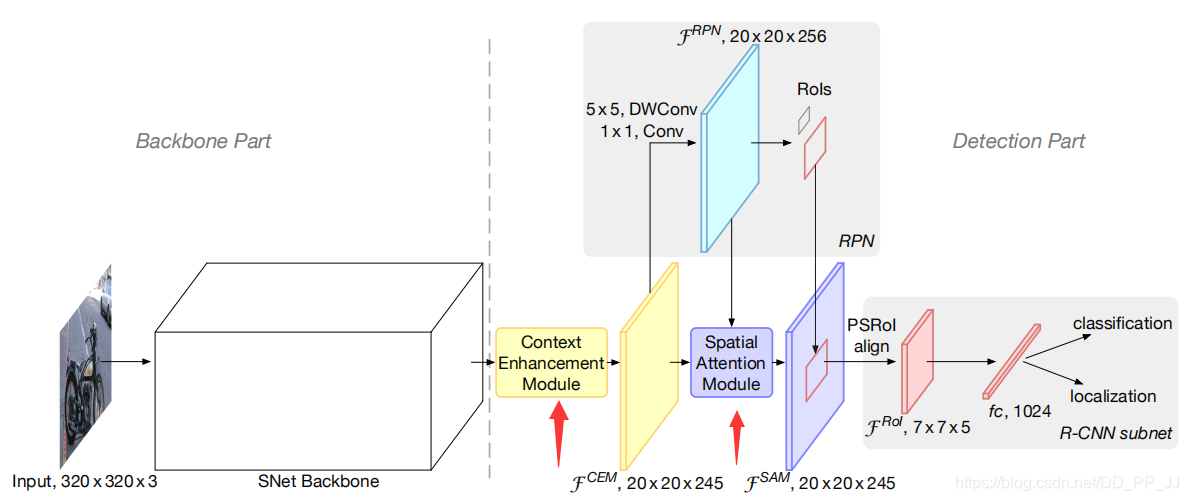
在以往的两阶段检测器中,RPN和Detection 头都太重了,为了和轻量级的网络进行配合以及降低计算量,ThunderNet沿用了Light-Head R-CNN中的大部分设置,并针对计算量比较大的部分进行改动:
还有很多细节部分的调整,大部分细节都和Light-Head R-CNN是一致的。
接下来就是两个重要的模块,CEM和SAM:
CEM
在Light-Head R-CNN中,使用了Global Convolutional Network来增大模型的感受野,但也带来了极大的计算量。为了解决这个问题,ThunderNet中提出了CEM来增大感受野,融合多尺度局部信息和全局信息来获取更有鉴别性的特征。
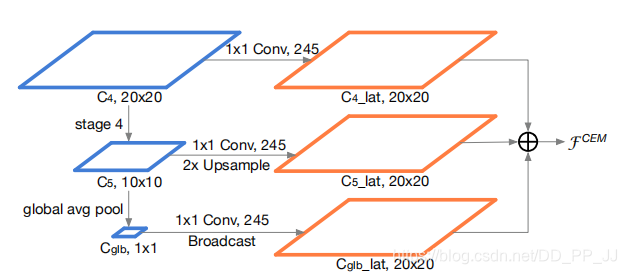
上图是CEM层的结构,其中C4来自backbone的Stage3,C5来自backbone的Stage4。具体操作过程上图很明显,构造了一个多尺度的特征金字塔,然后三个层相加,完成特征的优化。
接触过SENet的读者可能对这个结构有点熟悉,使用Global Avg pool以后实际上得到了一个通道的Attention,只不过SENet是相乘,而这里直接相加。总体来说这个模块构造的很好,以比较小的计算代价扩大了感受野,提供了多尺度特征。同时也有一些地方需要商量,比如是SENet中的乘法更适合呢?还是直接相加更适合?
SAM
SAM实际上就是利用RPN得到的feature map,然后用一个Attention机制对特征进行优化,具体实现方式见下图:
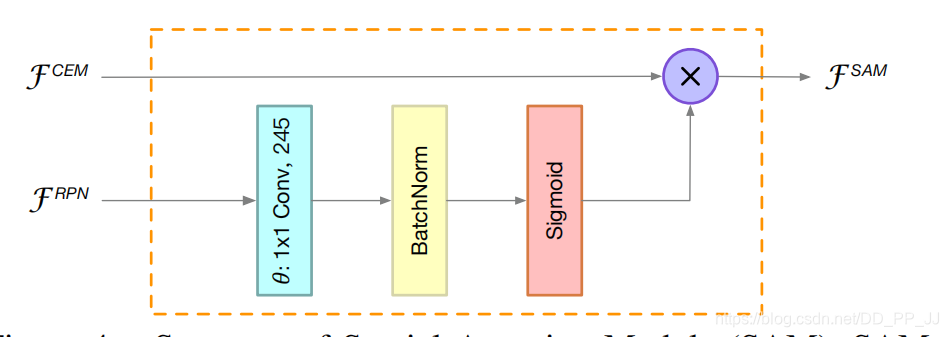
这个部分设计实际上是比较好的结合了两阶段模型的RPN网络。RPN网络是用来提出proposal的,在RPN中,我们期望背景区域特征不被关注,而更多地关注前景物体特征。RPN有较强的判别前景和背景的能力,所以这里的就用RPN的特征来指导原有特征,实际上是一个Spatial Attention,通过1x1卷积、BN、Sigmoid得到加权的特征图,引导网络学习到正确的前景背景特征分布。
这个模块也是非常精妙的结合了RPN以及空间Attention机制,非常insight,有效地对轻量级网络特征进行了优化,弥补了轻量网络特征比较弱的缺点。
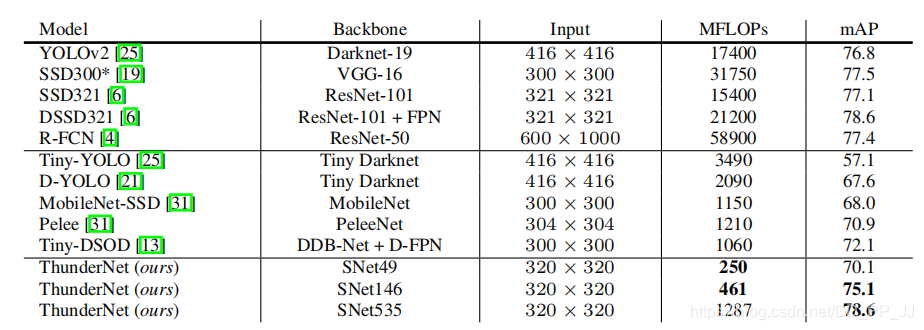
上表是在VOC2007数据集上的结果,可以看出,ThunderNet在比较好地做到了精度和计算量的权衡,并且证明了两阶段网络也有超越一阶段网络的潜力。
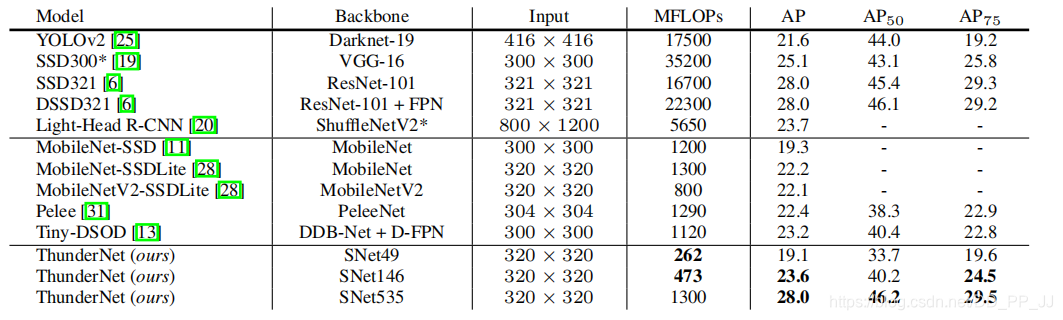
上表是在COCO数据集上的结果,可以看出效果依然非常出众。SNet49的ThunderNet在于MobileNet-SSD相近的精度下,速度快了5倍;SNet146的ThunderNet与one-stage相比,有更高的精度;SNet535的ThunderNet精度在和大型的一阶段网络(SSD,DSSD)一致的情况下,计算量显著降低。
ThunderNet作者非常善于思考,在将两阶段检测器进行轻量化设计的这个问题上有独特的想法,很多改进的点都是来自感受野的分析。主要提出了两个重要的模块:CEM 和SAM
CEM总的来说是融合了一个小型的FPN+通道注意力机制,以非常少的计算代价提高了模型的感受野,优化了backbone的特征。
SAM总的来说是用RPN的特征加强原有特征,本质上是一种空间注意力机制,这种方法或许可以扩展到所有的多阶段检测器中。
而SNet对ShuffleNetV2的改进也在消融实验中得到证明,所以或许其他轻量级网络也可以借鉴用5x5dwconv替换掉3x3conv的思路。
ThunderNet成功超越了很多一阶段的方法,也让我们改变了传统两阶段网络计算量大但精度高的印象。虽然很多论文中都用到了空间注意力机制和通道注意力机制,ThunderNet中通过自己独到的想法,比较完美地融合了这两个部分,有理有据,非常有力。
以上是笔者关于ThunderNet的解读和个人的思考,能力有限,如果有不同的看法,欢迎来交流。
https://arxiv.org/pdf/1903.11752.pdf
https://github.com/ouyanghuiyu/Thundernet_Pytorch
标签:使用 mod 感受 网络学习 设计 proc war 分类 term
原文地址:https://www.cnblogs.com/pprp/p/12432515.html