标签:广告 direct 安全 验证 bsp alt soup mic 百度链接
记录一下在用python爬取百度链接中遇到的坑:

1.获取百度搜索页面中的域名URL
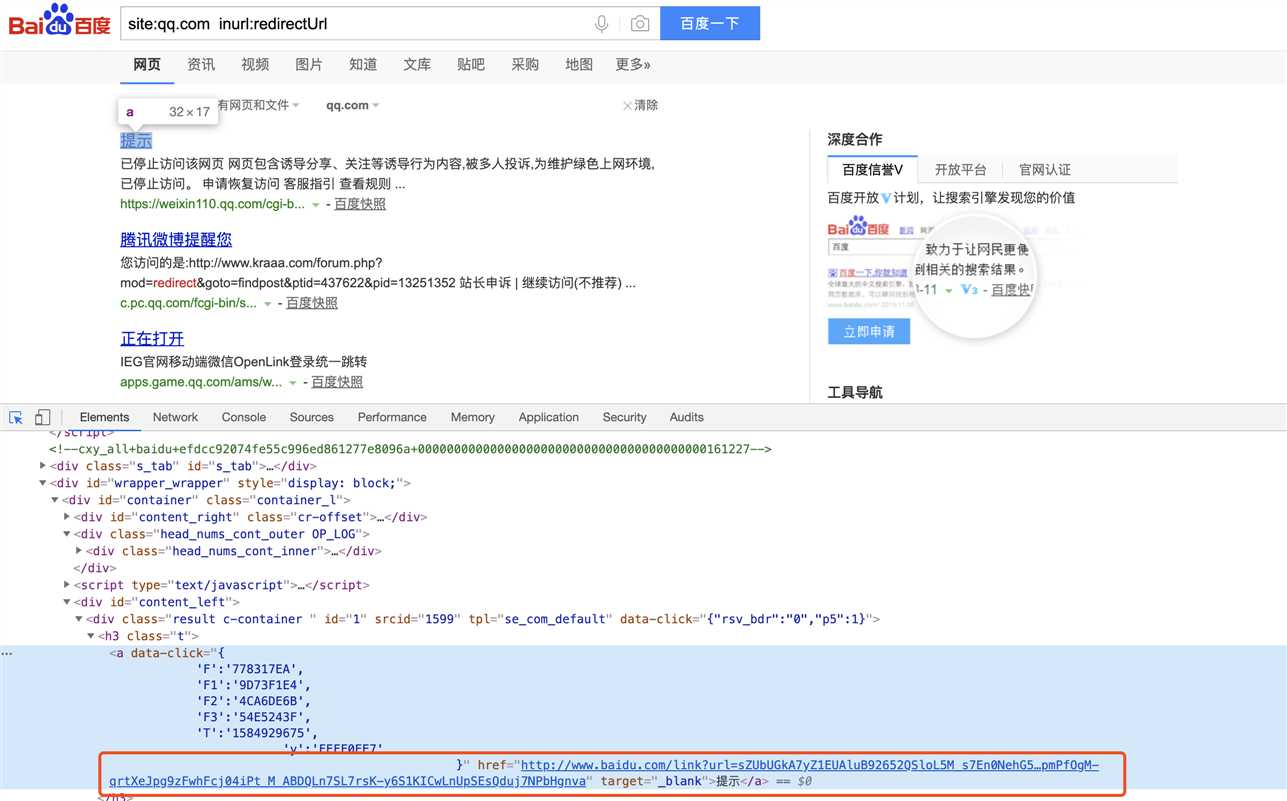
BeautifulSoup获取a标签中href属性后,链接为百度url,利用request直接访问默认会直接进行跳转,无法获取所需域名
此时需要将requests的allow_redirects属性设置为False,禁止进行跳转,requests默认会进行跳转
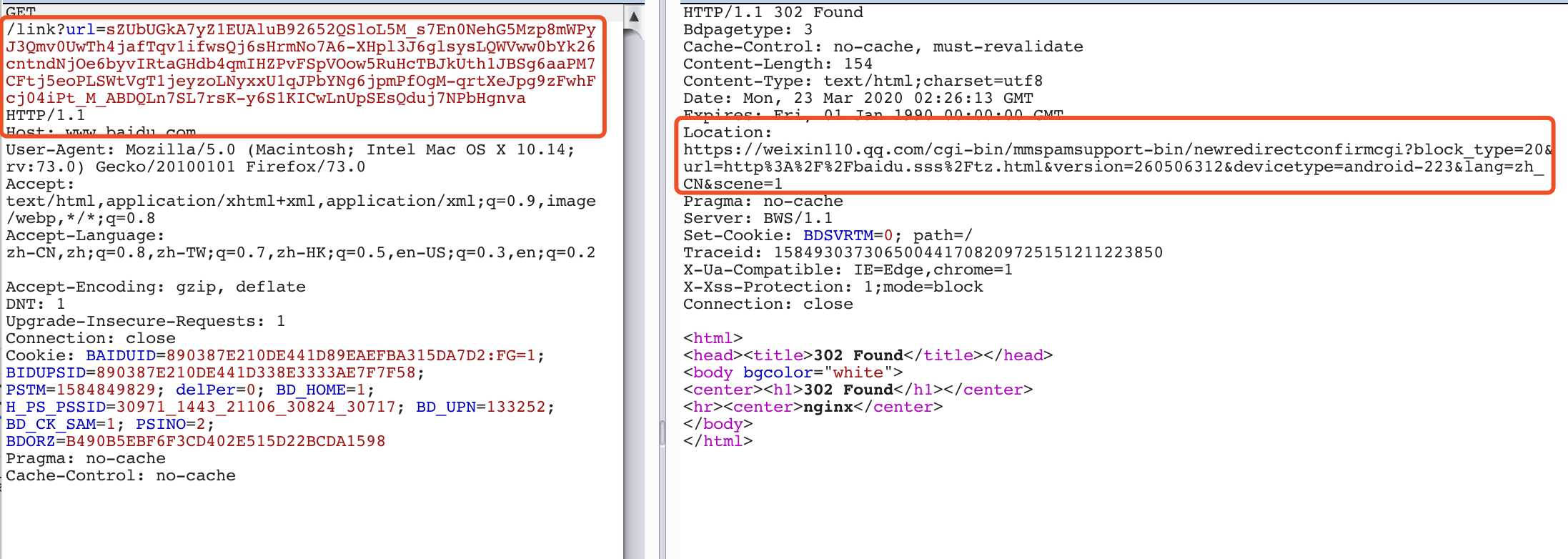
再使用.headers[‘Location‘]获取最后链接:final_url = baidu_url.headers[‘Location‘]
2.百度中的链接返回不统一
获取到实际域名链接后,发现还有一些奇怪的东西

访问后发现非site搜集域名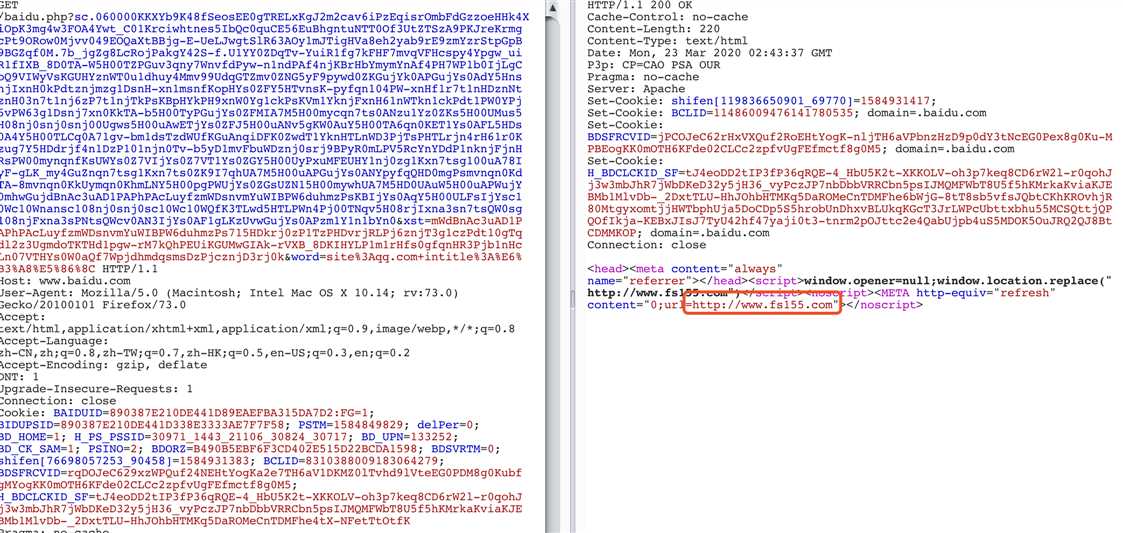
突然想到,很有可能是百度的广告

那就需要筛选出包含baidu.php?的链接去剔除掉
a="1"
b="123"
if a in b:来进行筛选
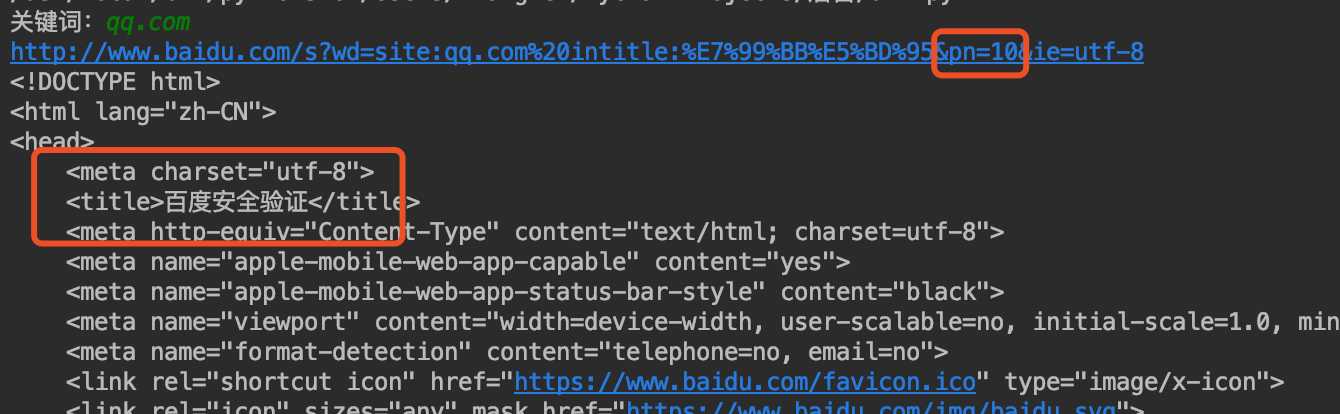
3.百度安全验证
当在百度搜索链接中加入pn页码参数时,便会出现百度安全验证

4.链接根域名的去重问题
Python+Google Hacking+百度搜索引擎进行信息搜集
标签:广告 direct 安全 验证 bsp alt soup mic 百度链接
原文地址:https://www.cnblogs.com/str1ve/p/12550571.html