标签:kernel 中间 平台 清理 布局 为我 像素 alt bat
VarGNet: Variable Group Convolutional Neural Network for Efficient Embedded Computing
Abstract
在本文中,我们提出了一种新的用于高效嵌入式计算的网络设计机制。受到有限的计算模式的启发,我们建议固定分组卷积中的通道数,而不是现有的固定总组数的做法。我们的基于解决方案的网络,称为可变分组卷积网络(VarGNet),可以在硬件方面更容易地优化,因为层之间的计算方案更加统一。在分类、检测、像素解析和人脸识别等各种视觉任务上的大量实验证明了VarGNet的实用价值。
1 Introduction
授权嵌入式系统运行众所周知的深度学习架构,如卷积神经网络(convolutional neural networks, CNNs),是近年来的一个热门话题。对于智能物联网应用而言,具有挑战性的部分是要求整个系统具有能量约束和体积小的特点。为了迎接挑战,提高整个计算过程的效率的工作大致可以分为两个方向:
上述工作都表明了它们在各种应用中的巨大实用价值。然而,由于两个不同的优化方向之间的差距,实际性能可能达不到设计者的期望。具体来说,对于使用小型madd精心调优的网络,总体延迟可能很高,而对于精心设计的编译器或加速器,实际网络可能很难处理。
在本论文中,我们打算通过系统地分析一个对嵌入式硬件和相应的编译器友好的轻量级网络的必要特性来弥补现有的差距。更准确地说,由于嵌入式系统中芯片的计算模式受到严格的限制,因此我们提出一个嵌入式系统友好的网络应该适合目标计算模式和理想的数据布局。通过拟合理想的数据布局,可以降低片内存储器与片外存储器之间的通信成本,从而充分利用计算吞吐量。
通过观察发现,如果网络中操作的计算强度更平衡,则网络计算图更容易优化。我们提出了基于depthwise可分卷积的可变分组卷积[25,8,47]。在可变分组卷积中,每个组的输入通道数是固定的,可以作为超参数进行调整,这与分组卷积中组数是固定的是不同的。这样做的好处有两方面:从编译器的角度来看,固定通道的数量更适合于优化,因为它具有更一致的计算模式和数据布局;与[20,38]中设置组数为通道数的depthwise卷积相比,可变分组卷积具有更大的网络容量[38],从而允许更小的通道数,这有助于减轻片外通信的时间消耗。
我们网络的另一个关键组件是更好地利用基于反向residual块[38]的片上存储器。然而在MobileNetV2[38]中,通道的数量是通过pointwise卷积来调整的,其与使用3×3 内核的depthwise卷积有着不同的计算模式,因此由于计算模式有限,很难进行优化。因此,我们提出先通过可变分组卷积将具有C通道的输入特征扩展到2C,然后通过pointwise卷积将其返回到C。通过这种方式,两种类型的层之间的计算成本更加平衡,因此对硬件和编译器更加友好。综上所述,我们的贡献可以总结如下:
2 Designing Efficient Networks on Embedded Systems
对于在嵌入式系统中使用的芯片,如FPGA或ASIC,较低的单价和较快的上市时间是整个系统设计的关键因素。这些关键点导致了一个相对简单的芯片配置。换句话说,与通用处理单元相比,计算方案受到了严格的限制。然而,SOTA网络中的操作非常复杂,有些层可以通过硬件设计来加速,而有些则不行。因此,为了在嵌入式系统上设计高效的网络,这里的第一直觉是,网络中的各个层在某种意义上应该是相似的。
另一个重要的直觉是基于CNNs中使用的卷积的两个属性。第一个属性是计算模式。在卷积中,几个过滤器(内核)在整个特征图上滑动,表示内核被重复使用,而来自特征图的值只使用一次。第二个属性是卷积核和特征映射的数据大小。通常情况下,卷积核的大小远远小于特征映射的大小,例如在2D卷积中,kernel的大小是k2C, 特征映射的大小是2HWC。根据上述两个特性,一个巧妙的解决方案是先加载内核的所有数据,然后依次进行提取和提取特征数据[48]的卷积。这种实用的解决方案是我们用于嵌入式系统上高效网络设计的如下两个指导方针的第二个直觉:
Small intermediate feature maps between blocks. 在SOTA网络中,通常的做法是先设计一个普通块和一个下采样块,然后将几个块叠加在一起,得到一个深度网络。此外,在这些块,residual连接[18]被广泛采用。因此,在最近的编译器端优化[48]中,块中的层通常被分组并一起计算。在这种方式下,片外存储器和片内存储器仅在启动或结束网络中一个块的计算时进行通信。因此,块之间更小的中间特征映射肯定有助于减少数据传输时间。
Balanced computational intensity inside a block. 如上面所述,在实践中,在执行卷积之前要加载多个层中的权值。如果加载的层在计算强度方面有很大的差异,则需要额外的片上内存来存储特征映射的中间片。在MobileNetV1[20]中,使用了一个depthwise卷积和一个pointwise卷积。与以前的定义不同,在我们的实现中,权重已经加载。因此,计算强度是根据MAdds划分特征图的大小来计算的。那么,如果特征映射的大小为28×28×256,则depthwise卷积和pointwise卷积的计算强度分别为9和256。因此,当运行这两个层时,我们必须增加芯片上的缓冲区来满足pointwise,或者不将这两个层的计算分组在一起。
3 Variable Group Network
在前面提到的两个准则的基础上,我们在本节中提出了一个新的网络。为了平衡计算强度,我们将网络中一个组中的通道数设置为常数,从而使得每个卷积层中的组数都是可变的。如果我们看一下卷积的MAdds,就会发现固定通道数的动机并不难理解:
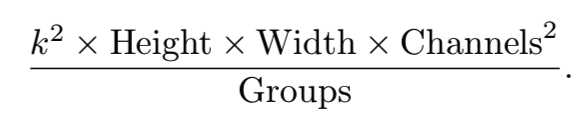
因此,如果特征映射的大小为常数,则通过固定G = Channels/Groups,块内的计算强度更加均衡。此外,可以设置组中的通道数量来满足处理元素的配置,每次处理一定数量的通道。
####### 额外添加的解释 - 开始 (可见VarGFaceNet)##########
在MobileNet等网络中使用的depthwise-pointwise结合网络中,depthwise卷积中的G = Channels/Groups = 1,因为将卷积中的groups数设置为与channels数相同的数量
这个提出的可变分组卷积怎么使用呢? 就是用它来替代depthwise-pointwise结合网络中的depthwise卷积部分,这样替代的好处是什么呢:
MobileNet和MobileNetV2提出了depthwise可分卷积,它是在分组卷积的基础上提出的,既节省了计算成本,又保持了卷积的判别能力。然而,depthwise可分离卷积在卷积1×1中花费了95%的计算时间,导致两个连续的层(Conv 1×1和Conv DW 3×3)之间存在较大的MAdds间隙(即两者的MAdds的差距较大)。这个缺口对那些加载所有网络权值来执行卷积[24]的嵌入式系统是不友好的:嵌入式系统需要额外的缓冲区来执行卷积1×1。
为了保持块内计算强度的平衡,VarGNet[26]将组内的信道数设为常数S,即上面的G。可变分组卷积的计算代价为:
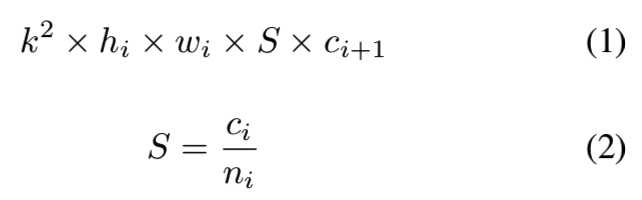
该层的输入为hi × wi × ci,输出为hi × wi × ci+1。k是核的大小。当MobileNet中使用可变分组卷积代替depthwise卷积时,pointwise卷积的计算成本为:
![]()
这样可变分组卷积和pointwise卷积的计算开销比例为 k2S / ci+2 ,而depthwise卷积和pointwise卷积的比例为k2 / ci+2。实际上,ci+2 >> k2, S > 1,所以 k2S / ci+2 > k2 / ci+2。因此,在pointwise卷积的基础上使用可变分组卷积而不是depthwise卷积,在块内的计算会更加均衡。
S > 1表示与depthwise卷积(核大小相同时)相比,可变分组卷积具有更高的MAdds和更大的网络容量,能够提取更多的信息。
####### 额外添加的解释 - 结束 ##########
与depthwise卷积相比,可变分组卷积增加了MAdds和增强了表达能力[38]。因此,现在我们能够减少网络中间特征映射的通道数量,同时保持与以前网络相同的泛化能力。具体而言,我们设计了如图1所示的新型网络块:
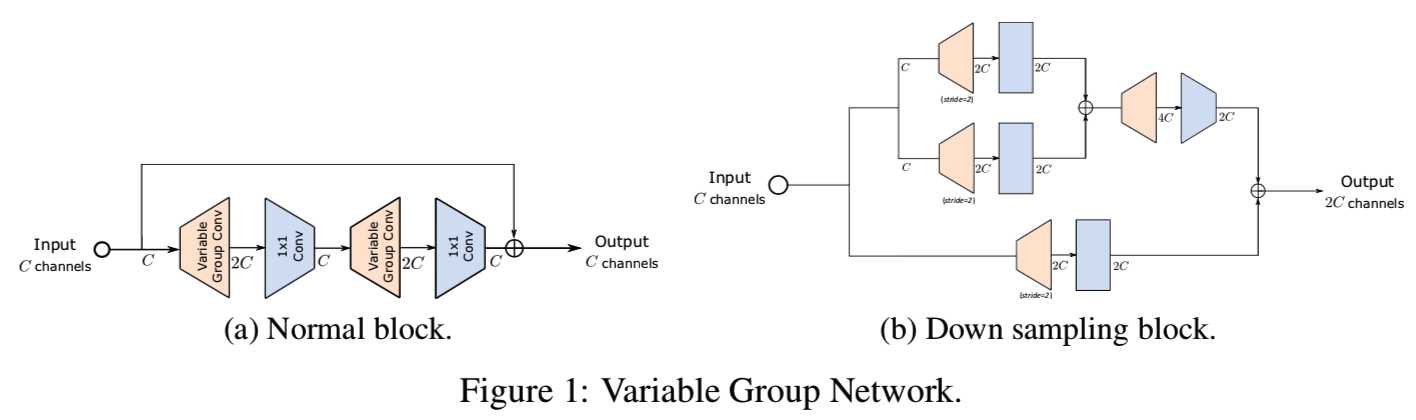
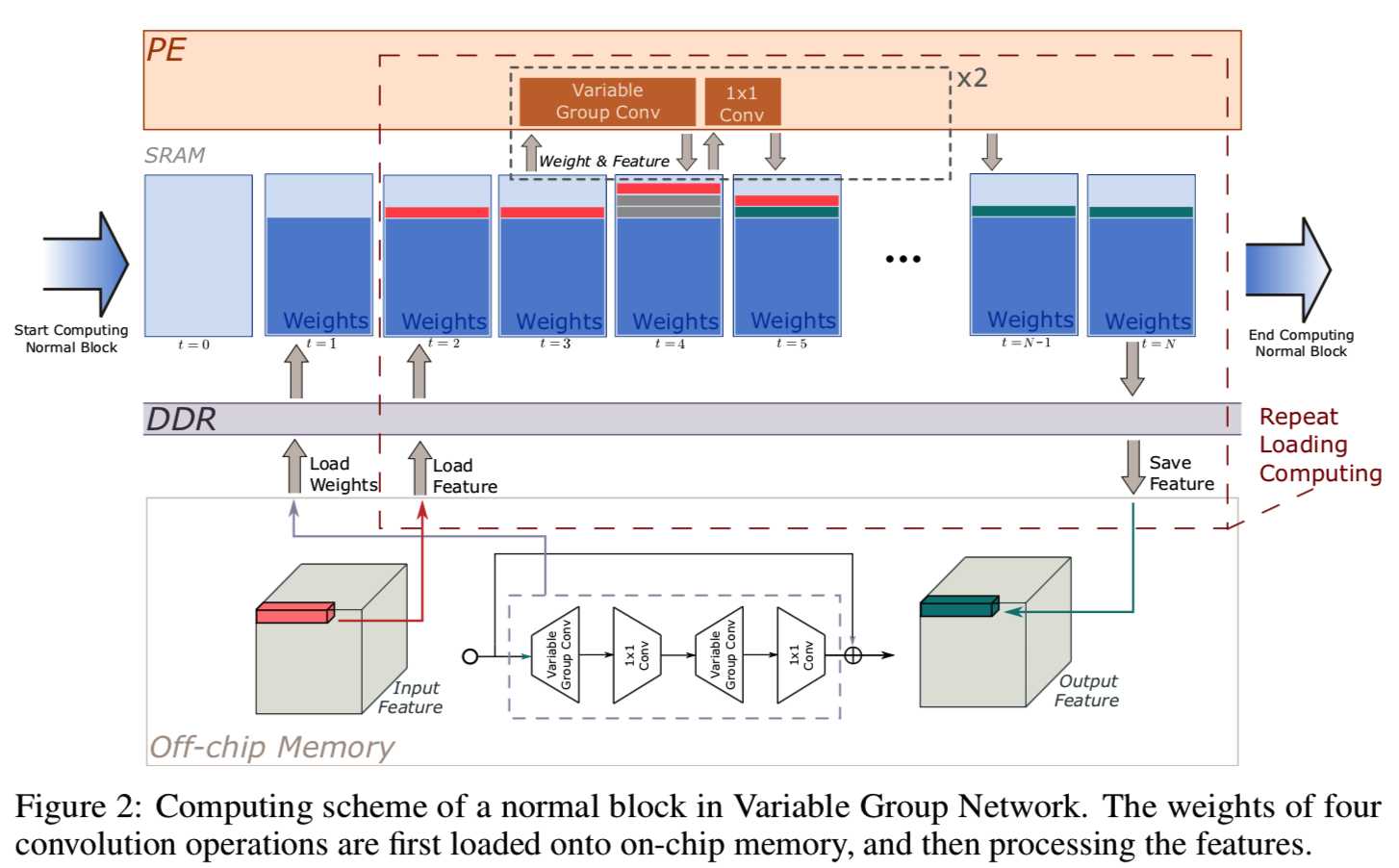
对于整个网络早期使用的normal块,由于此时权值的大小比较小,所以四层的权值都可以缓存到片上存储器中。当进入晚期,通道数增加和权重的大小增加,normal块也能够通过只加载一个可变分组卷积和pointwise卷积来优化。同样,下采样块的操作也对编译器方面和硬件方面的优化表现友好。一个normal块的整个计算过程如图2所示:
然后,基于MobileNetV1[20]的架构,我们将他们的basic块替换为我们的,整个详细的网络架构如表1所示:
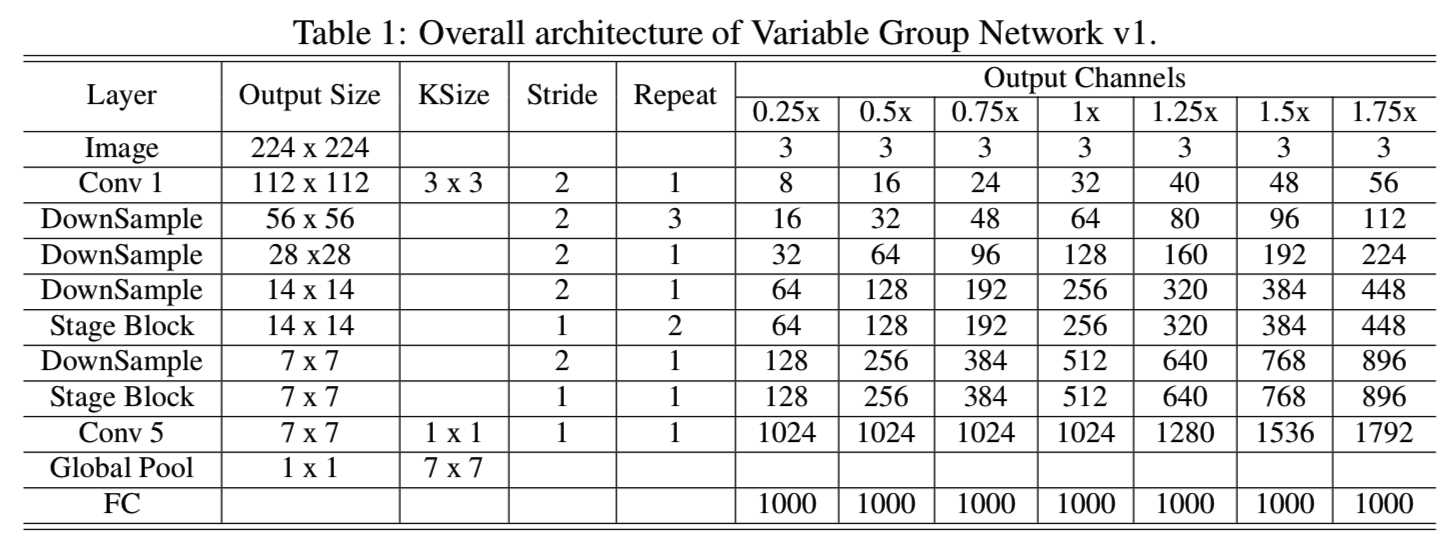
另外,另一个基于ShuffleNet v2的架构如表2所示:
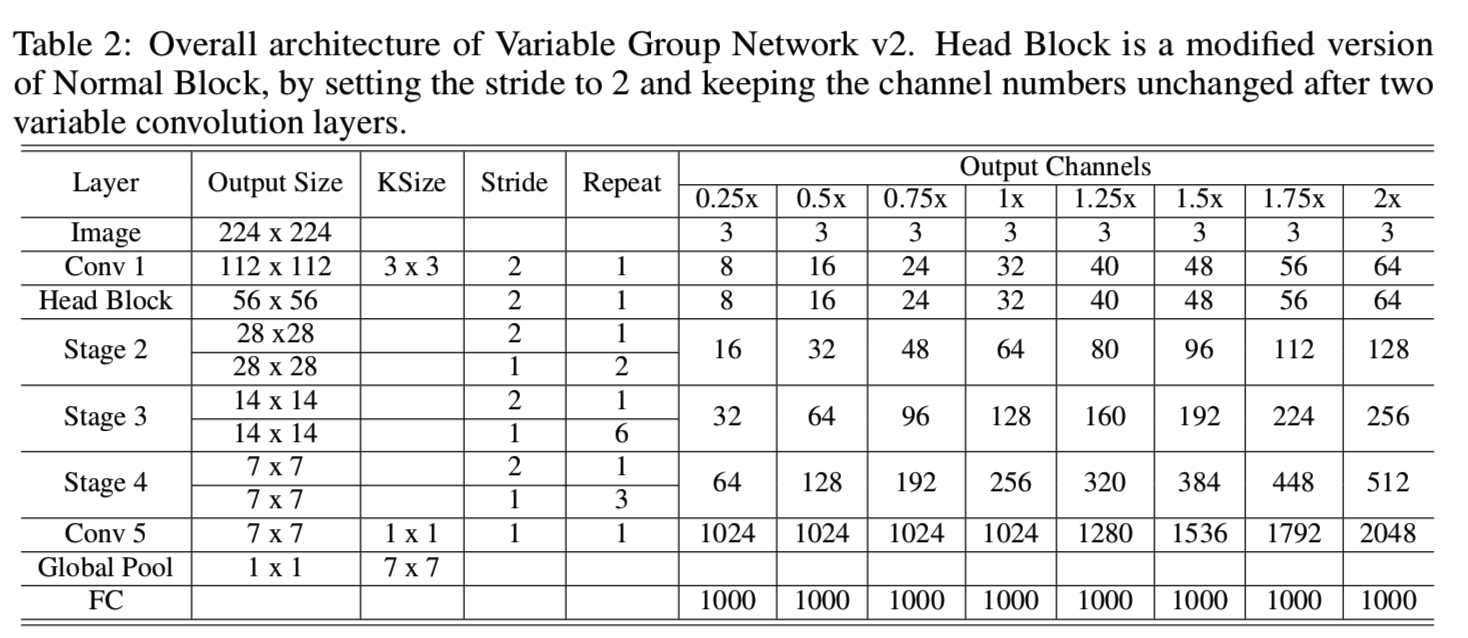
4 Experiments
4.1 ImageNet Classification
我们的模型在ImageNet上的结果如表3和表4所示:
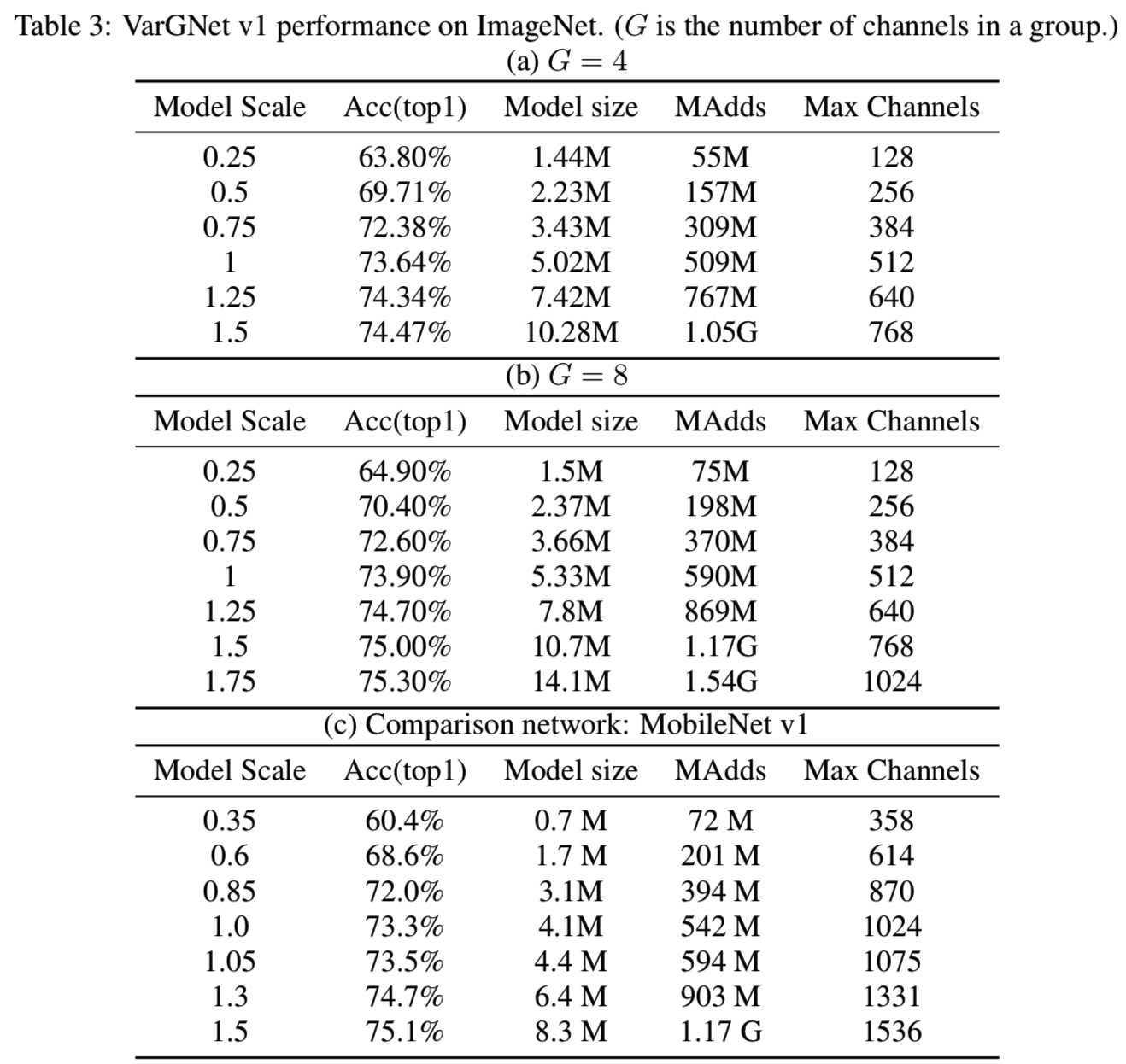
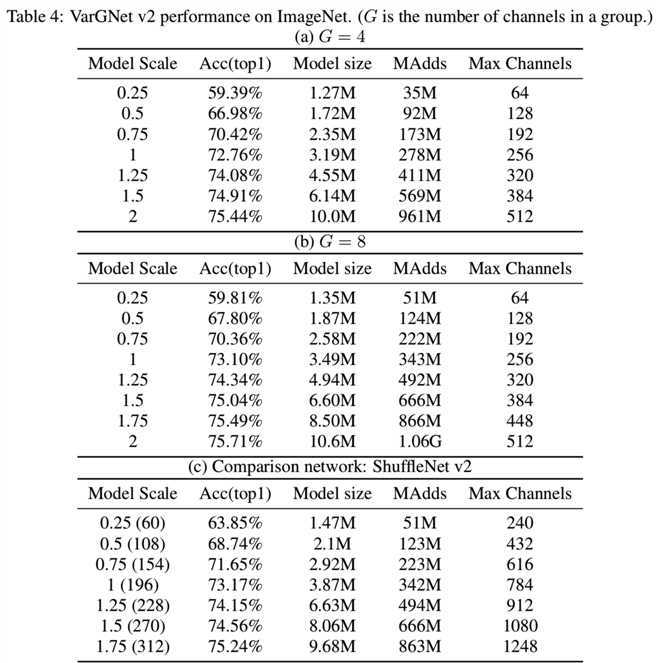
训练超参数设置为:batchsize为1024,crop ratio为0.875,学习率为0.4,使用余弦学习率调度,权重衰减为4e-5,训练周期为240。我们可以观察到VarGNet v1比MobileNet v1性能更好,如表3所示。从表4中的(c)可以看出,当模型规模较小时,VarGNet v2的性能要差于ShuffleNet v2,这是由于VarGNet v2中使用的通道较少造成的。然后,当模型规模较大时,我们的网络表现得更好。
4.2 Object Detection
在表5中,我们展示了我们提出的VarGNet的性能及与其比较的方法:
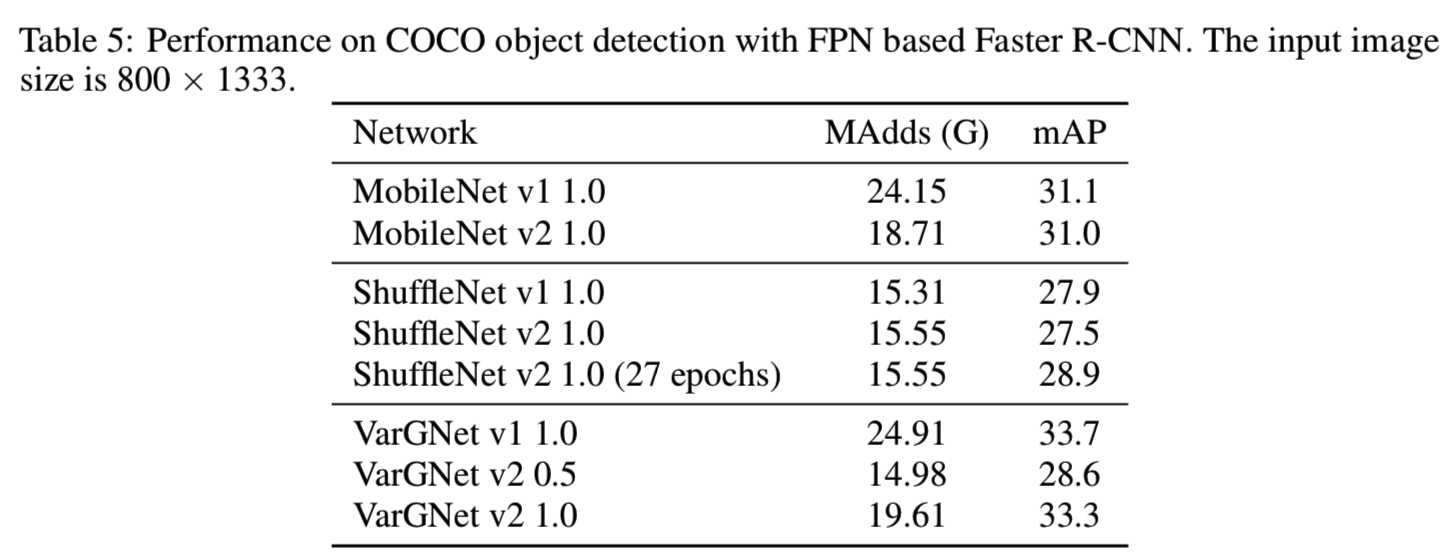
我们评估了我们提出的网络在COCO数据集[27]上的目标检测性能,并将其与其他最先进的轻量级架构进行了比较。我们选择基于FPN的Faster R-CNN[26]作为框架,所有实验都在相同的设置下进行,输入分辨率为800×1333,epochs为18。特别地是,我们发现如果使用更多的epoch来训练ShuffleNet v2可以获得更好的准确性,因此我们为ShuffleNet v2训练了一个拥有27个epoch的模型。在测试时,RPN阶段评估每幅图像的1000个proposals。除8000张最小图像外,我们使train+val集进行训练,最后在minival集上进行测试。
4.3 Pixel Level Parsing
4.3.1 Cityscapes
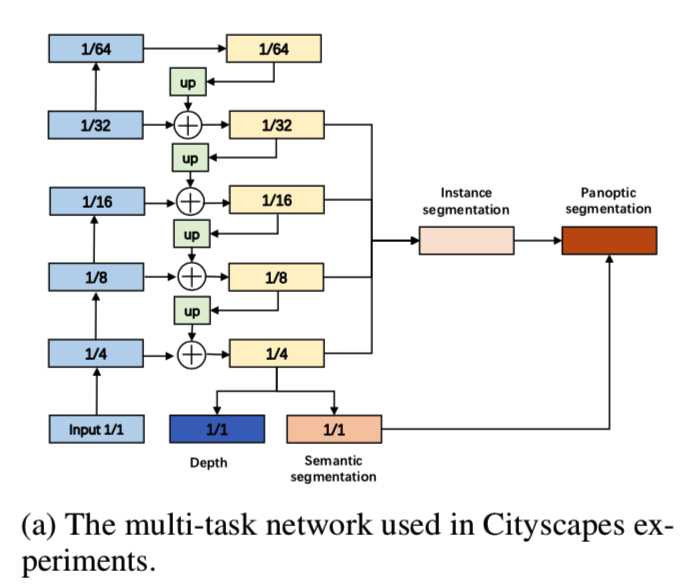
在Cityscapes数据集[9]上,我们设计了一个多任务结构(图3a)来进行两个重要的像素级解析任务:单图像深度预测和分割:
Training setup. 我们使用标准的Adam优化器,将权重衰减设置为1e-5,batchsize设置为16。初始化学习率为1e-4,多项式衰减为0.9。总训练时间设置为100。为了增加数据,使用了随机水平翻转,并从0.6-1.2中随机选择比例来调整图像的大小。对于多任务训练,我们将损失函数定义为:
![]()
当任务是全景分割是,设置λinstance=0.2, λsemantic=1.0。之后添加深度任务,设置λdepth=0.08
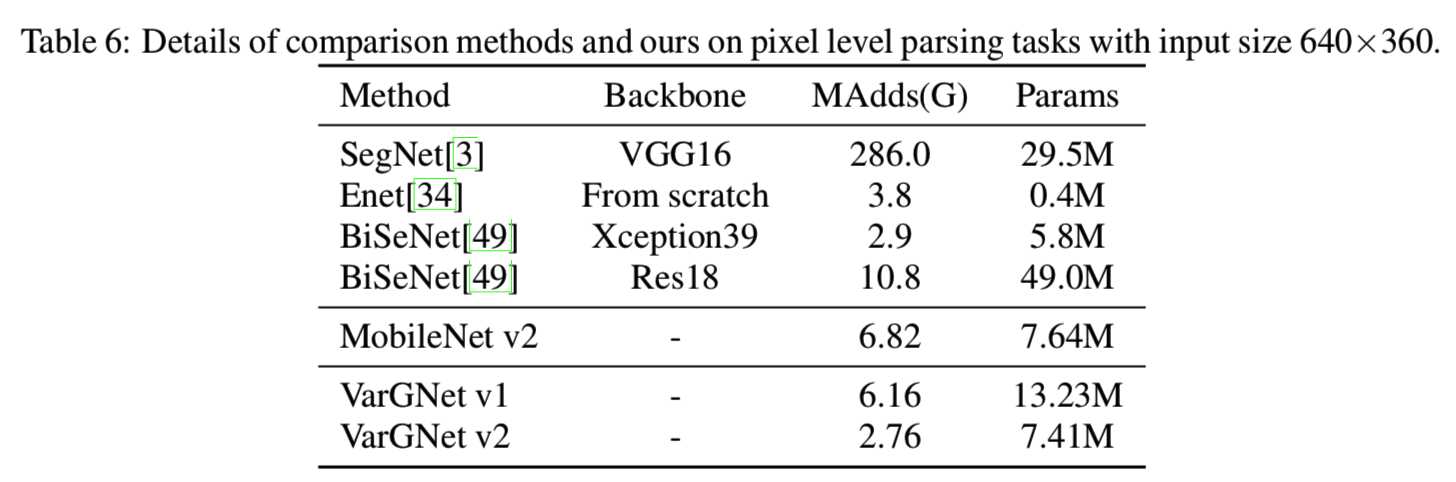
Results. 比较方法的参数和MAdds如表6所示:
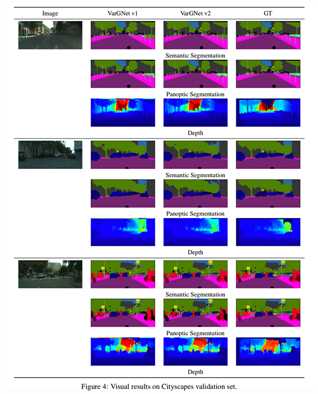
分割结果和深度预测的可视化示例分别见表7和图4:
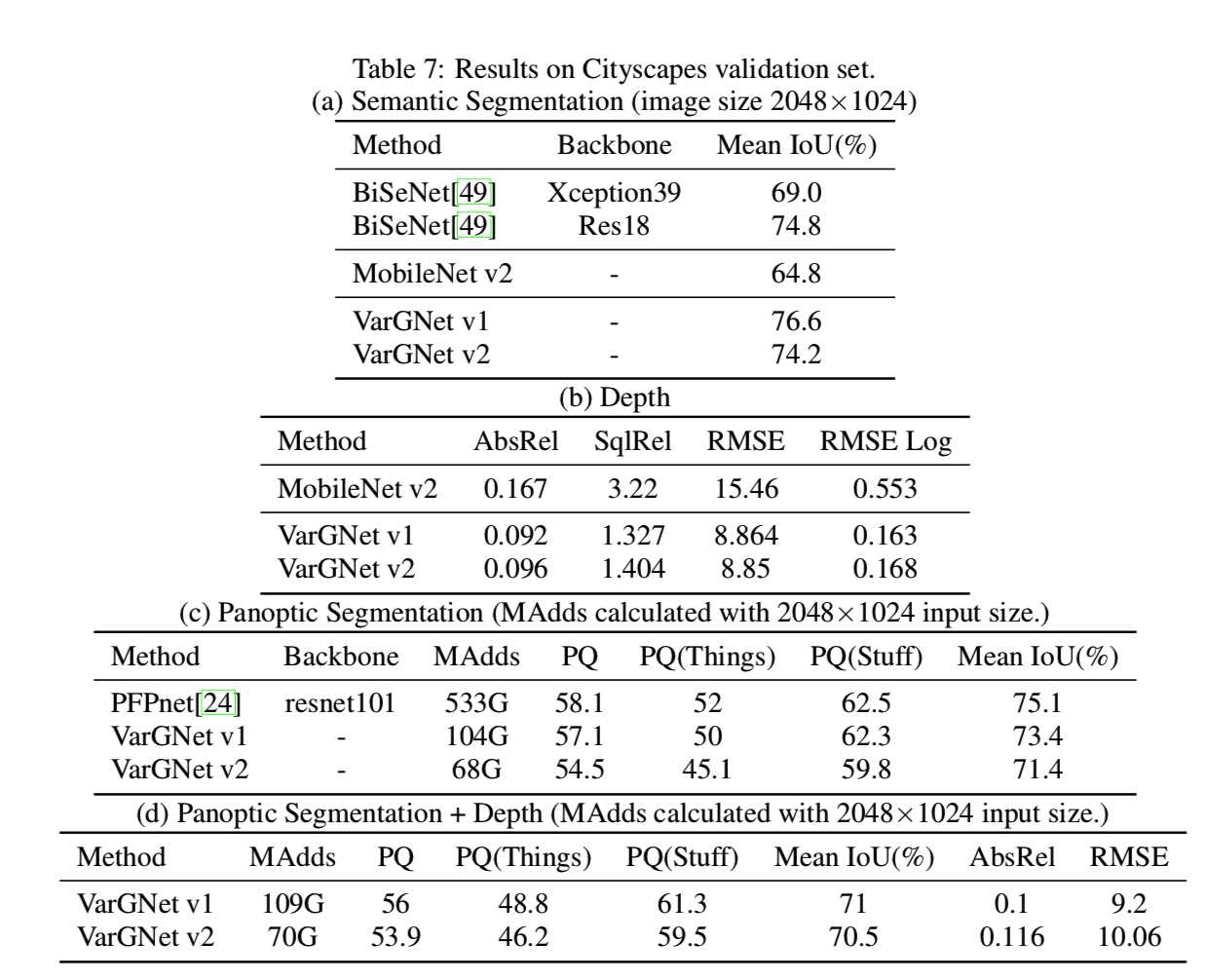
上述表格证明了VarGNet v1和v2的优异。与大型网络相比,VarGNet v1和v2是有效的,且可以表现得一样好。
4.4 KITTI
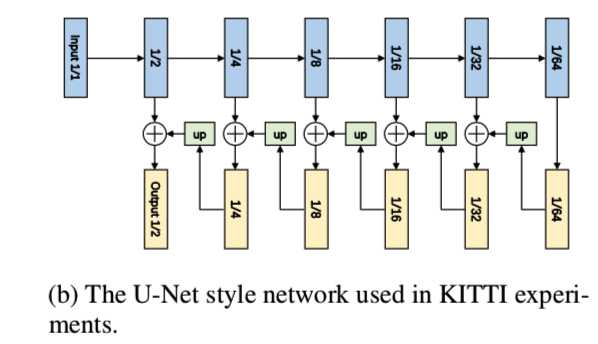
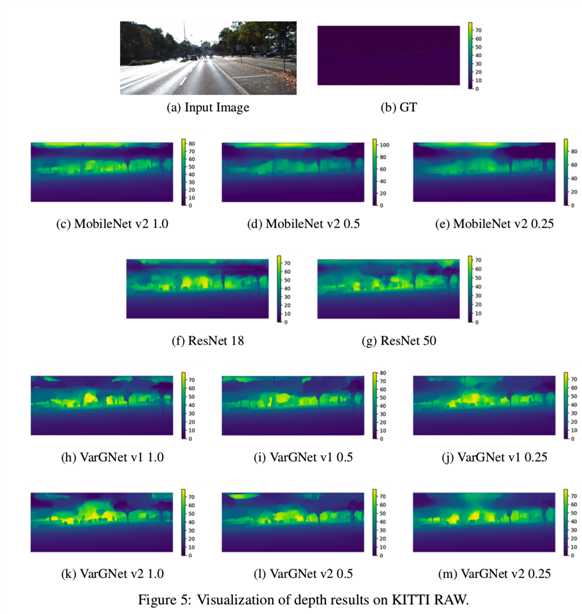
Trainning setup. 对于KITTI数据集[14]上的单幅图像的深度预测和立体任务,我们给出了基于VarGNet的模型的性能。实验采用了一个U-Net风格的体系结构(3b):
所有的深度模型都是在KITTI RAW数据集上训练的,我们测试了来自Eigen等人[12]分割的29个场景中的697张图像,并对其余32个场景中的23488张图像进行了训练。所有实验结果均在0m ~ 80m、0m ~ 50m深度范围内进行评价。评价指标与以往工作相同。所有的立体模型都是在KITTI RAW数据集上训练的,我们测试了Eigen等人分割的测试集[12],以及KITTI15的训练集。stereo的评价指标为EPE和D1。在训练期间,使用标准的SGD优化器,momentum设置为0.9。resnet18和resnet50的标准权重衰减设置为0.0001,其他设置为0.00004。迭代次数设置为300个epoch。初始学习率为0.001,学习率在[120,180,240]的epoch处衰减0.1。我们使用4个GPU来训练模型,batchsize设置为24。
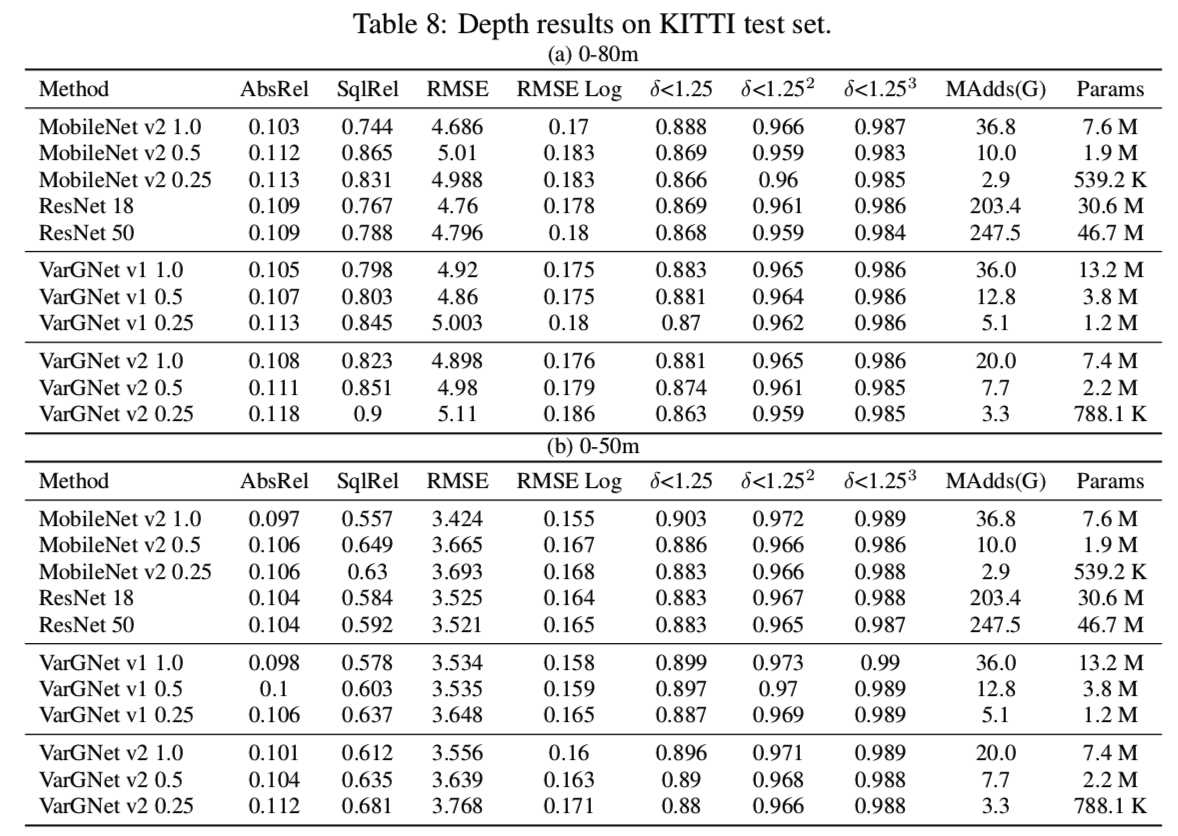
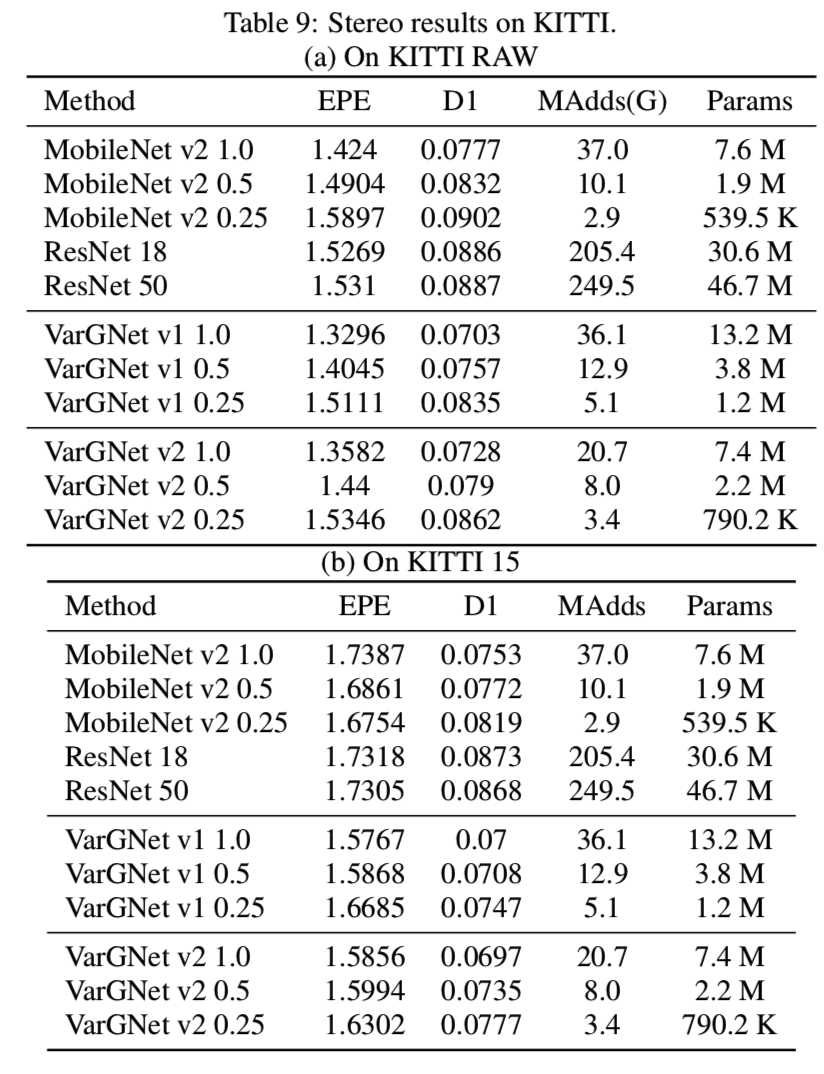
Results. 在表8和表9中,我们展示了我们在各种评价指标下的深度结果和立体结果。同时,我们报告了将我们实现的MobileNet和ResNet作为比较方法的结果:
此外,视觉效果如图5和图6所示:

4.5 Face Recognition
所有的网络都在MS-Celeb-1M-v1c数据集[1]上进行训练,该数据集从MS-Celeb-1M-[16]中清理而成。有来自86,876个id的3,923,399个对齐的人脸图像。验证数据集使用LFW[21]、CFP-FP[39]和AgeDB-30[32]。最后,在MegaFace Challenge 1[33]上对所有网络模型进行评估。表10列出了验证数据集的最佳人脸识别准确率,以及MegaFace数据集[11]的改进版本在1e-6错误接受率下的人脸验证真实接受率:
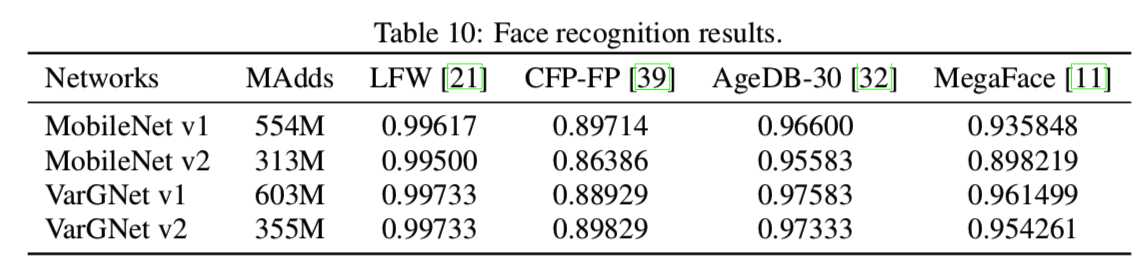
我们使用MobileNet v1和MobileNet v2作为基线模型。为了适应输入图像大小为112x112,对于每个基线和vargnet网络,将第一卷积层的stride设置为1。为了获得更好的性能,我们进一步将池化层替换为“BN-Dropout-FC-BN”结构,即InsightFace[11],然后跟着的是ArcFace loss[11]。标准的SGD优化器与momentum为0.9一起使用,batchsize设置为512,配置8个gpu。学习率从0.1开始,在100K、140K和160K迭代时除以10。我们设权重衰减为5e-4。嵌入特征维数为256,dropout率为0.4。归一化比例为64,ArcFace margin设置为0.5。所有的训练都基于InsightFace toolbox[11]。
VarGNet: Variable Group Convolutional Neural Network for Efficient Embedded Computing - 1 -论文学习
标签:kernel 中间 平台 清理 布局 为我 像素 alt bat
原文地址:https://www.cnblogs.com/wanghui-garcia/p/12558633.html