标签:裁剪 目录 username asi 内容 下划线 字母 title tor
一、通用操作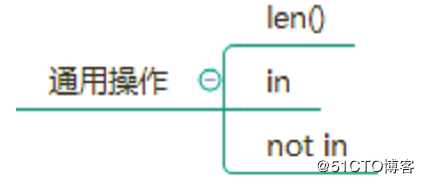
方法返回对象(字符、列表、元组等)长度或项目个数。
len()方法语法:
len( q )返回对象长度。
以下实例展示了 len() 的使用方法:
>>>str = "runoob"
>>> len(str) # 字符串长度
6
>>> l = [1,2,3,4,5]
>>> len(l) # 列表元素个数
5Python成员运算符测试给定值是否为序列中的成员,例如字符串,列表或元组。 有两个成员运算符,如下所述 -
in 如果在指定的序列中找到一个变量的值,则返回true,否则返回false。
not in 如果在指定序列中找不到变量的值,则返回true,否则返回false。
| in | 如果在指定的序列中找到值返回 True,否则返回 False。 | x 在 y 序列中 , 如果 x 在 y 序列中返回 True。 |
|---|---|---|
| not in | 如果在指定的序列中没有找到值返回 True,否则返回 False。 | x 不在 y 序列中 , 如果 x 不在 y 序列中返回 True。 |
#!/usr/bin/python3
a = 10
b = 20
list = [1, 2, 3, 4, 5 ];
if ( a in list ):
print ("1 - 变量 a 在给定的列表中 list 中")
else:
print ("1 - 变量 a 不在给定的列表中 list 中")
if ( b not in list ):
print ("2 - 变量 b 不在给定的列表中 list 中")
else:
print ("2 - 变量 b 在给定的列表中 list 中")
# 修改变量 a 的值
a = 2
if ( a in list ):
print ("3 - 变量 a 在给定的列表中 list 中")
else:
print ("3 - 变量 a 不在给定的列表中 list 中")1 - 变量 a 不在给定的列表中 list 中 2 - 变量 b 不在给定的列表中 list 中 3 - 变量 a 在给定的列表中 list 中
身份运算符用于比较两个对象的存储单元
| is | is 是判断两个标识符是不是引用自一个对象 | x is y, 类似 id(x) == id(y) , 如果引用的是同一个对象则返回 True,否则返回 False |
|---|---|---|
| is not | is not 是判断两个标识符是不是引用自不同对象 | x is not y , 类似 id(a) != id(b)。如果引用的不是同一个对象则返回结果 True,否则返回 False。 |
注: id() 函数用于获取对象内存地址。
#!/usr/bin/python3
a = 20
b = 20
if ( a is b ):
print ("1 - a 和 b 有相同的标识")
else:
print ("1 - a 和 b 没有相同的标识")
if ( id(a) == id(b) ):
print ("2 - a 和 b 有相同的标识")
else:
print ("2 - a 和 b 没有相同的标识")
# 修改变量 b 的值
b = 30
if ( a is b ):
print ("3 - a 和 b 有相同的标识")
else:
print ("3 - a 和 b 没有相同的标识")
if ( a is not b ):
print ("4 - a 和 b 没有相同的标识")
else:
print ("4 - a 和 b 有相同的标识")1 - a 和 b 有相同的标识 2 - a 和 b 有相同的标识 3 - a 和 b 没有相同的标识 4 - a 和 b 没有相同的标识
is 与 == 区别:
is 用于判断两个变量引用对象是否为同一个, == 用于判断引用变量的值是否相等。
>>>a = [1, 2, 3]
>>> b = a
>>> b is a
True
>>> b == a
True
>>> b = a[:]
>>> b is a
False
>>> b == a
True以下表格列出了从最高到最低优先级的所有运算符:
| 运算符 | 描述 |
|---|---|
| ** | 指数 (最高优先级) |
| ~ + - | 按位翻转, 一元加号和减号 (最后两个的方法名为 +@ 和 -@) |
| * / % // | 乘,除,求余数和取整除 |
| + - | 加法减法 |
| >> << | 右移,左移运算符 |
| & | 位 ‘AND‘ |
| ^ | | 位运算符 |
| <= < > >= | 比较运算符 |
| == != | 等于运算符 |
| = %= /= //= -= += *= **= | 赋值运算符 |
| is is not | 身份运算符 |
| in not in | 成员运算符 |
| not and or | 逻辑运算符 |
#!/usr/bin/python3
a = 20
b = 10
c = 15
d = 5
e = 0
e = (a + b) * c / d #( 30 * 15 ) / 5
print ("(a + b) * c / d 运算结果为:", e)
e = ((a + b) * c) / d # (30 * 15 ) / 5
print ("((a + b) * c) / d 运算结果为:", e)
e = (a + b) * (c / d); # (30) * (15/5)
print ("(a + b) * (c / d) 运算结果为:", e)
e = a + (b * c) / d; # 20 + (150/5)
print ("a + (b * c) / d 运算结果为:", e)(a + b) * c / d 运算结果为: 90.0 ((a + b) * c) / d 运算结果为: 90.0 (a + b) * (c / d) 运算结果为: 90.0 a + (b * c) / d 运算结果为: 50.0
x = True
y = False
z = False
if x or y and z:
print("yes")
else:
print("no")yes
注意:Pyhton3 已不支持 <> 运算符,可以使用 != 代替,如果你一定要使用这种比较运算符,可以使用以下的方式:
>>> from __future__ import barry_as_FLUFL
>>> 1 <> 2
True
xgp = ‘hello,wsd‘
print(xgp)
# upper():将字符串转换为大写
xgp1 = xgp.upper()
print(xgp1)
# isupper():判断字符串是否都为大写
print(xgp1.isupper())
# lower():将字符串转换为小写
xgp2 = xgp1.lower()
print(xgp2)
# islower():判断字符串是否都为小写
print(xgp2.islower())
# title():将字符串中的单词转换为标题格式,每个单词首字母大写,其余小写
xgp3 = xgp2.title()
print(xgp3)
# istitle():判断字符事是不是一个标题
print(xgp3.istitle())
# swapcase():小写转大写,大写转小写
xgp4 = xgp3.swapcase()
print(xgp4)
xgp5 = xgp4.swapcase()
print(xgp5)
# capitalize():将首字母转换为大写
xgp6 = xgp5.capitalize()
print(xgp6)# 原始输出 hello,wsd # 将字符串转换为大写 HELLO,WSD # 判断字符串是否都为大写 True # 将字符串转换为小写 hello,wsd # 判断字符串是否都为小写 True # 将字符串中的单词转换为标题格式,每个单词首字母大写,其余小写 Hello,Wsd # 判断字符事是不是一个标题 True # 小写转大写,大写转小写 hELLO,wSD Hello,Wsd # 将首字母转换为大写 Hello,wsd
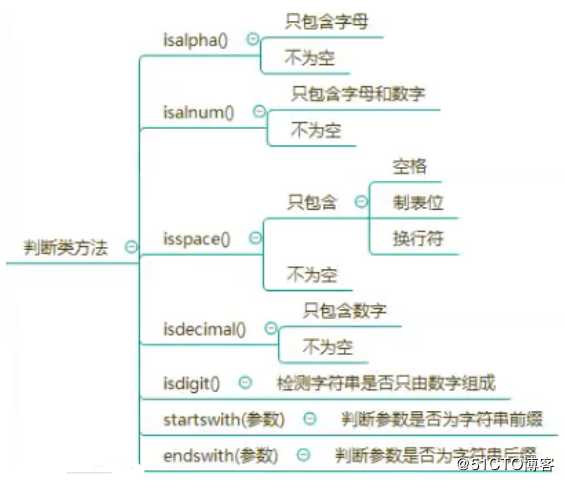
Python isalpha() 方法检测字符串是否只由字母组成。
isalpha()方法语法:
str.isalpha()如果字符串至少有一个字符并且所有字符都是字母则返回 True,否则返回 False。
str = "runoob";
print str.isalpha();
str = "runoob小钢炮";
print str.isalpha();
str = "this is string example....wow!!!";
print str.isalpha();True False False
Python isalnum() 方法检测字符串是否由字母和数字组成。
isalnum()方法语法:
str.isalnum()如果 string 至少有一个字符并且所有字符都是字母或数字则返回 True,否则返回 False
以下实例展示了isalnum()方法的实例:
str = "this2009"; # 字符中没有空格
print str.isalnum();
str = "this is string example....wow!!!";
print str.isalnum();True False
Python isspace() 方法检测字符串是否只由空白字符组成。
isspace() 方法语法:
str.isspace()如果字符串中只包含空格/指标位/换行符,则返回 True,否则返回 False.
以下实例展示了isspace()方法的实例:
str = " \n \t"
print (str.isspace())
str = "Runoob example....wow!!!"
print (str.isspace())True False
Python isdecimal() 方法检查字符串是否只包含十进制字符。这种方法只存在于unicode对象。
注意:定义一个十进制字符串,只需要在字符串前添加 ‘u‘ 前缀即可。
isdecimal()方法语法:
str.isdecimal()如果字符串是否只包含十进制字符返回True,否则返回False。
以下实例展示了 isdecimal()函数的使用方法:
str = "runoob2016"
print (str.isdecimal())
str = "23443434"
print (str.isdecimal())False True
Python isdigit() 方法检测字符串是否只由数字组成。
isdigit()方法语法:
str.isdigit()如果字符串只包含数字则返回 True 否则返回 False。
以下实例展示了isdigit()方法的实例:
str = "123456";
print (str.isdigit())
str = "Runoob example....wow!!!"
print (str.isdigit())True False
startswith() 方法用于检查字符串是否是以指定子字符串开头,如果是则返回 True,否则返回 False。如果参数 beg 和 end 指定值,则在指定范围内检查。
startswith()方法语法:
str.startswith(substr, beg=0,end=len(string));如果检测到字符串则返回True,否则返回False。
以下实例展示了startswith()函数的使用方法:
str = "this is string example....wow!!!"
print (str.startswith( ‘this‘ )) # 字符串是否以 this 开头
print (str.startswith( ‘string‘, 8 )) # 从第八个字符开始的字符串是否以 string 开头
print (str.startswith( ‘this‘, 2, 4 )) # 从第2个字符开始到第四个字符结束的字符串是否以 this 开头True True False
endswith() 方法用于判断字符串是否以指定后缀结尾,如果以指定后缀结尾返回 True,否则返回 False。可选参数 "start" 与 "end" 为检索字符串的开始与结束位置。
endswith()方法语法:
str.endswith(suffix[, start[, end]])如果字符串含有指定的后缀返回 True,否则返回 False。
以下实例展示了endswith()方法的实例:
Str=‘Runoob example....wow!!!‘
suffix=‘!!‘
print (Str.endswith(suffix))
print (Str.endswith(suffix,20))
suffix=‘run‘
print (Str.endswith(suffix))
print (Str.endswith(suffix, 0, 19))True
True
False
False1、用户名不能是纯数字,不能以数字开头,必须包含数字、字母或者下划线其中两项。
2、用户密码长度在6-12位之间,不能是纯数字或纯字母,必须包含数字、字母大写或小写两项。
3、符合以上要求,程序提示注册成功;否则在输入内容之后立即给出错误提示。
def user():
while True:
username = input(‘请输入要注册的账号(不能是纯数字,不能以数字开头,必须包含数字、字母或者下划线其中两项‘)
if username == ‘‘ :
print(‘用户名不能为空‘)
continue
elif username .isdecimal() or username[0].isdecimal() == True:
print(‘用户名首字母不能为数字或不能为纯数字用户名‘ )
continue
elif username.isalpha() == True:
print(‘必须包含数字字母下 划线其中两项‘ )
continue
else:
return username
break
def password():
while True:
passwd = input(‘ 请输入密码: ‘)
if len(passwd) < 6 or len(passwd) > 12:
print( ‘用户密码长度在6 -12位之间‘)
continue
elif passwd. isdecimal() or passwd. isalpha():
print(‘用户密码不能是纯数字或纯字母,必须包含数字、字母大写或小写两项:‘)
continue
else:
return passwd
break
def xgp():
user()
password()
print(‘注册成功‘)
xgp()请输入要注册的账号(不能是纯数字,不能以数字开头,必须包含数字、字母或者下划线其中两项f123 请输入密码: sdf456!weq. 注册成功
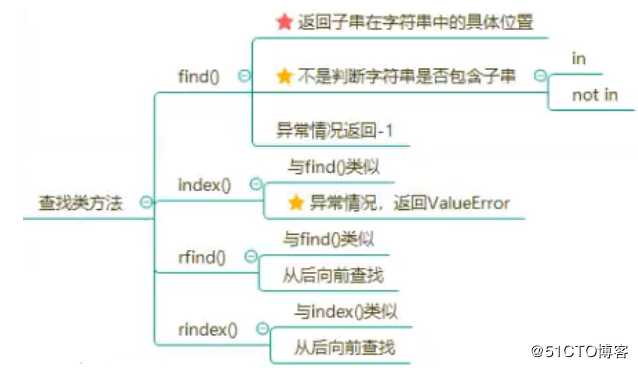
str = ‘hello,python‘
print(str.find(‘p‘))
print(str.index(‘e‘))
print(str.rindex(‘o‘))
print(str.rfind(‘h‘))6 1 10 9
find() 方法检测字符串中是否包含子字符串 str ,如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,如果指定范围内如果包含指定索引值,返回的是索引值在字符串中的起始位置。如果不包含索引值,返回-1。
find()方法语法:
str.find(str, beg=0, end=len(string))如果包含子字符串返回开始的索引值,否则返回-1。
以下实例展示了find()方法的实例:
str1 = "Runoob example....wow!!!"
str2 = "exam";
print (str1.find(str2))
print (str1.find(str2, 5))
print (str1.find(str2, 10))7
7
-1>>>info = ‘abca‘
>>> print(info.find(‘a‘)) # 从下标0开始,查找在字符串里第一个出现的子串,返回结果:0
0
>>> print(info.find(‘a‘, 1)) # 从下标1开始,查找在字符串里第一个出现的子串:返回结果3
3
>>> print(info.find(‘3‘)) # 查找不到返回-1
-1index() 方法检测字符串中是否包含子字符串 str ,如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,该方法与 python find()方法一样,只不过如果str不在 string中会报一个异常。
index()方法语法:
str.index(str, beg=0, end=len(string))如果包含子字符串返回开始的索引值,否则抛出异常。
以下实例展示了index()方法的实例:
str1 = "Runoob example....wow!!!"
str2 = "exam";
print (str1.index(str2))
print (str1.index(str2, 5))
print (str1.index(str2, 10))7
7
Traceback (most recent call last):
File "test.py", line 8, in <module>
print (str1.index(str2, 10))
ValueError: substring not foundPython rfind() 返回字符串最后一次出现的位置,如果没有匹配项则返回-1。
rfind()方法语法:
str.rfind(str, beg=0 end=len(string))返回字符串最后一次出现的位置,如果没有匹配项则返回-1。
以下实例展示了rfind()函数的使用方法:
str1 = "this is really a string example....wow!!!"
str2 = "is"
print (str1.rfind(str2))
print (str1.rfind(str2, 0, 10))
print (str1.rfind(str2, 10, 0))
print (str1.find(str2))
print (str1.find(str2, 0, 10))
print (str1.find(str2, 10, 0))5 5 -1 2 2 -1
rindex() 返回子字符串 str 在字符串中最后出现的位置,如果没有匹配的字符串会报异常,你可以指定可选参数[beg:end]设置查找的区间。
rindex()方法语法:
str.rindex(str, beg=0 end=len(string))返回子字符串 str 在字符串中最后出现的位置,如果没有匹配的字符串会报异常。
以下实例展示了rindex()函数的使用方法:
str1 = "this is really a string example....wow!!!"
str2 = "is"
print (str1.rindex(str2))
print (str1.rindex(str2,10))5 Traceback (most recent call last): File "test.py", line 6, in <module> print (str1.rindex(str2,10)) ValueError: substring not found
验证规则:
正确格式:abc@163.com.cn
1、邮箱必须包含“@”和“.”
2、“@”在邮箱字符串中不能是第一个位置
3、“.”右侧至少应该有2-3个字符
4、“.”左侧不能是“@”
def vanzheng():
youxiang = input(‘ 输入您的邮箱:‘)
num = youxiang.index(‘.‘)
qiepian = youxiang[num:-1]
if youxiang[0] ==‘@‘ or youxiang[0] == ‘.‘ :
print(‘邮箱第一位不能是@或者“.” ‘)
elif ‘.‘ not in youxiang or ‘@‘ not in youxiang:
print(‘邮箱必须包含“@”和“”‘)
elif len(qiepian) <= 2:
print(‘“.”右侧至少应该有2-3个字符‘)
elif youxiang[-1] == ‘@‘ or youxiang[-1] == ‘.‘:
print(‘邮箱最后一位不能是@或者.‘)
else:
print(‘邮箱正确‘)
vanzheng()
yx=input(‘请输入您的邮箱‘)
at = yx.find(‘@‘ )
dian = yx. find(‘.‘)
if (at <= 0 or dian <=0) or yx[-1]== ‘.‘ or (dian - at) <=1 :
print(‘邮箱格式有误‘ )输入您的邮箱:123@qq.com 邮箱正确
1、提取passwd文件最后5个用户的记录
2、把每个用户的信息按“:”分别提取用户名、所属组、家目录、登录的shell类型
user_info = ‘‘‘postfix:x:89:89::/var/spool/postfix:/sbin/nologin
tcpdump:x:72:72::/:/sbin/nologin
test-07:x:1000:1000:test-07:/home/test-07:/bin/bash
chou:x:1003:1003::/home/chouchou:/bin/bash
test02:x:1002:1007::/home/test001:/bin/bash
try:x:1004:1004::/home/try:/bin/bash
laoyu:x:1005:1009::/home/laoyu:/bin/bash‘‘‘
new_info = user_info.split(‘\n‘)
for i in new_info:
print(‘用户名:‘+i.split(‘:‘)[0]+‘所属组:‘+i.split(‘:‘)[4]+‘家目录:‘+i.split(‘:‘)[5]+‘登录环境:‘+i.split(‘:‘)[6])用户名:postfix所属组:家目录:/var/spool/postfix登录环境:/sbin/nologin
用户名:tcpdump所属组:家目录:/登录环境:/sbin/nologin
用户名:test-07所属组:test-07家目录:/home/test-07登录环境:/bin/bash
用户名:chou所属组:家目录:/home/chouchou登录环境:/bin/bash
用户名:test02所属组:家目录:/home/test001登录环境:/bin/bash
用户名:try所属组:家目录:/home/try登录环境:/bin/bash
用户名:laoyu所属组:家目录:/home/laoyu登录环境:/bin/bash
split() 通过指定分隔符对字符串进行切片,如果第二个参数 num 有指定值,则分割为 num+1 个子字符串。
split() 方法语法:
str.split(str="", num=string.count(str))返回分割后的字符串列表。
以下实例展示了 split() 函数的使用方法:
str = "this is string example....wow!!!"
print (str.split( )) # 以空格为分隔符
print (str.split(‘i‘,1)) # 以 i 为分隔符
print (str.split(‘w‘)) # 以 w 为分隔符txt = "Google#Runoob#Taobao#Facebook"
# 第二个参数为 1,返回两个参数列表
x = txt.split("#", 1)
print(x)[‘Google‘, ‘Runoob#Taobao#Facebook‘]Python join() 方法用于将序列中的元素以指定的字符连接生成一个新的字符串。
join()方法语法:
str.join(sequence)返回通过指定字符连接序列中元素后生成的新字符串。
以下实例展示了join()的使用方法:
s1 = "-"
s2 = ""
seq = ("r", "u", "n", "o", "o", "b") # 字符串序列
print (s1.join( seq ))
print (s2.join( seq ))r-u-n-o-o-b
runoob简单来说,三种方法是为了删除字符串中不同位置的指定字符。其中,strip()用于去除字符串的首尾字符,同理,lstrip()用于去除左边的字符,rstrip()用于去除右边的字符
Python strip() 方法用于移除字符串头尾指定的字符(默认为空格)。
若传入的是一个字符数组,编译器将去除字符串两端所有相应的字符,直到没有匹配的字符。
str.strip([chars])string1 = ‘ Kobe Bryant ‘
print(string1.strip()) Kobe Bryant 默认删除字符串前后的空格。
string2 = ‘uuuussssaaaa china aaaassssuuu‘
print(string2.strip(‘usa‘))china 其中, ‘u‘、‘s‘、‘a‘ 的个数可以为任意,不影响最后输出 > china
Python lstrip() 方法用于截掉字符串左边的空格或指定字符,默认为空格。
string1 = ‘ Kobe Bryant ‘
string1.lstrip()‘Kobe Bryant ‘ 默认删除字符串前的空格。
string2 = ‘uuuussssaaaa china aaaassssuuu‘
print(string2.strip(‘usa‘))china aaaassssuuu
Python lstrip() 方法用于截掉字符串右边的空格或指定字符,默认为空格。
string1 = ‘ Kobe Bryant ‘
string1.lstrip()Kobe Bryant‘ 默认删除字符串后的空格。
string2 = ‘uuuussssaaaa china aaaassssuuu‘
print(string2.strip(‘usa‘))uuuussssaaaa china
replace() 方法把字符串中的 old(旧字符串) 替换成 new(新字符串),如果指定第三个参数max,则替换不超过 max 次。
replace()方法语法:
str.replace(old, new[, max])返回字符串中的 old(旧字符串) 替换成 new(新字符串)后生成的新字符串,如果指定第三个参数max,则替换不超过 max 次。
以下实例展示了replace()函数的使用方法:
str = "wsdixgp.top"
print ("xgp旧地址:", str)
print ("xgp新地址:", str.replace("wsdixgp.top", "wsdlxgp.top"))
str = "this is string example....wow!!!"
print (str.replace("is", "was", 3))xgp旧地址: wsdixgp.top
xgp新地址: wsdlxgp.top
thwas was string example....wow!!!from __future__ import print_function
ips = []
with open(‘access.log‘) as f:
for line in f:
ips.append(line.split()[0])
print(‘网站请求数[PV]:‘+ str(len(ips)))
print(‘网站独立的访客数[UV]:‘+ str(len(set(ips))))网站请求数[PV]:120 网站独立的访客数[UV]:6
from __future__ import print_function
d = {}
with open(‘access.log‘) as f:
for line in f:
key = line.split()[8]
d.setdefault(key,0)
d[key] += 1
print(d)
# 出错的页面数量
error_requests = 0
# 页面总访问量
sum_requests = 0
# 遍历字典
for key, value in d.items():
if int(key) >= 400:
error_requests += value
sum_requests += value
print(‘页面出错率:{0:2f}%‘.format(error_requests * 100.0/sum_requests)){‘200‘: 115, ‘500‘: 1, ‘248‘: 1, ‘210‘: 1, ‘203‘: 1, ‘400‘: 1} 页面出错率:1.666667%

Python 支持格式化字符串的输出 。尽管这样可能会用到非常复杂的表达式,但最基本的用法是将一个值插入到一个有字符串格式符 %s 的字符串中。
在 Python 中,字符串格式化使用与 C 中 sprintf 函数一样的语法。
print ("我叫 %s 今年 %d 岁!" % (‘小名‘, 10))我叫 小名 今年 10 岁!
| 符 号 | 描述 |
|---|---|
| %c | 格式化字符及其ASCII码 |
| %s | 格式化字符串 |
| %d | 格式化整数 |
| %u | 格式化无符号整型 |
| %o | 格式化无符号八进制数 |
| %x | 格式化无符号十六进制数 |
| %X | 格式化无符号十六进制数(大写) |
| %f | 格式化浮点数字,可指定小数点后的精度 |
| %e | 用科学计数法格式化浮点数 |
| %E | 作用同%e,用科学计数法格式化浮点数 |
| %g | %f和%e的简写 |
| %G | %f 和 %E 的简写 |
| %p | 用十六进制数格式化变量的地址 |
格式化操作符辅助指令:
| 符号 | 功能 |
|---|---|
| * | 定义宽度或者小数点精度 |
| - | 用做左对齐 |
| + | 在正数前面显示加号( + ) |
| <sp> | 在正数前面显示空格 |
| # | 在八进制数前面显示零(‘0‘),在十六进制前面显示‘0x‘或者‘0X‘(取决于用的是‘x‘还是‘X‘) |
| 0 | 显示的数字前面填充‘0‘而不是默认的空格 |
| % | ‘%%‘输出一个单一的‘%‘ |
| (var) | 映射变量(字典参数) |
| m.n. | m 是显示的最小总宽度,n 是小数点后的位数(如果可用的话) |
Python2.6 开始,新增了一种格式化字符串的函数 str.format(),它增强了字符串格式化的功能。
rint( ‘%d‘ % 3)
print( ‘%09f‘ % 3.14)
print(‘%s‘ % ‘hello‘)3 03.140000 hello
Python2.6 开始,新增了一种格式化字符串的函数 str.format(),它增强了字符串格式化的功能。
基本语法是通过 {} 和 : 来代替以前的 % 。
format 函数可以接受不限个参数,位置可以不按顺序。
>>>"{} {}".format("hello", "world") # 不设置指定位置,按默认顺序
‘hello world‘
>>> "{0} {1}".format("hello", "world") # 设置指定位置
‘hello world‘
>>> "{1} {0} {1}".format("hello", "world") # 设置指定位置
‘world hello world‘也可以设置参数:
print("网站名:{name}, 地址 {url}".format(name="xgp", url="wsdlxgp.top"))
# 通过字典设置参数
site = {"name": "xgp", "url": "wsdlxgp.top"}
print("网站名:{name}, 地址 {url}".format(**site))
# 通过列表索引设置参数
my_list = [‘xgp‘, ‘wsdlxgp.top‘]
print("网站名:{0[0]}, 地址 {0[1]}".format(my_list)) # "0" 是必须的网站名:xgp, 地址 wsdlxgp.top 网站名:xgp, 地址 wsdlxgp.top 网站名:xgp, 地址 wsdlxgp.top
也可以向 str.format() 传入对象:
class AssignValue(object):
def __init__(self, value):
self.value = value
my_value = AssignValue(6)
print(‘value 为: {0.value}‘.format(my_value)) # "0" 是可选的value 为: 6
下表展示了 str.format() 格式化数字的多种方法:
| 数字 | 格式 | 输出 | 描述 |
|---|---|---|---|
| 3.1415926 | {:.2f} | 3.14 | 保留小数点后两位 |
| 3.1415926 | {:+.2f} | +3.14 | 带符号保留小数点后两位 |
| -1 | {:+.2f} | -1.00 | 带符号保留小数点后两位 |
| 2.71828 | {:.0f} | 3 | 不带小数 |
| 5 | {:0>2d} | 05 | 数字补零 (填充左边, 宽度为2) |
| 5 | {:x<4d} | 5xxx | 数字补x (填充右边, 宽度为4) |
| 10 | {:x<4d} | 10xx | 数字补x (填充右边, 宽度为4) |
| 1000000 | {:,} | 1,000,000 | 以逗号分隔的数字格式 |
| 0.25 | {:.2%} | 25.00% | 百分比格式 |
| 1000000000 | {:.2e} | 1.00e+09 | 指数记法 |
| 13 | {:>10d} | 13 | 右对齐 (默认, 宽度为10) |
| 13 | {:<10d} | 13 | 左对齐 (宽度为10) |
| 13 | {:^10d} | 13 | 中间对齐 (宽度为10) |
| 11 | ‘{:b}‘.format(11) ‘{:d}‘.format(11) ‘{:o}‘.format(11) ‘{:x}‘.format(11) ‘{:#x}‘.format(11) ‘{:#X}‘.format(11) |
1011 11 13 b 0xb 0XB |
^, <, > 分别是居中、左对齐、右对齐,后面带宽度, : 号后面带填充的字符,只能是一个字符,不指定则默认是用空格填充。
+ 表示在正数前显示 +,负数前显示 -; (空格)表示在正数前加空格
b、d、o、x 分别是二进制、十进制、八进制、十六进制。
# 精度
print(‘{: .2f}‘.format(3.141592656535897))
# 符号
print(‘{: .2f}‘.format(3.141592656535897))
# 宽度
print( ‘{:10.2f}‘.format(3.141592656535897))
# 对齐方式
print(‘{:^10.2f}‘.format(3.141592656535897))
# 逗号分隔
print(‘{:,}‘.format(23421424231))3.14 3.14 3.14 3.14 23,421,424,231
print ("{} 对应的位置是 {{0}}".format("runoob"))runoob 对应的位置是 {0}python字符串(大小写、判断、查找、分割、拼接、裁剪、替换、格式化)
标签:裁剪 目录 username asi 内容 下划线 字母 title tor
原文地址:https://blog.51cto.com/14320361/2484344