标签:art 主机名 异常 重启 let sel 特性 fail 逻辑判断
在Kubernetes上,我们很少会直接创建一个Pod,在大多数情况下,
会通过RC、Deployment、DaemonSet、Job等控制器完成对一组Pod副本的创建、调度和整个生命周期的自动化控制。
在早期的Kubernetes版本上,是没有这么多Pod副本控制器的,只有一个Pod副本控制器RC(Replication Controller)。
RC独立于所控制的Pod,并通过label标签关联控制目标Pod的创建和销毁等动作。
随着Kubernetes的发展,RC也出现了新的继承者——Deployment,用于更加自动的完成对Pod副本的部署、版本更新、回滚等功能
严格说来,RC的继承者并不是Deployment,而是ReplicaSet,它与RC的最大升级在于支持基于集合的select lable。
这样相对于RC来说,ReplicaSet的标签选择更加的灵活。
Deployment相对于RC的最大不同之处就在于可以知道Pod创建的过程。
这种特性对于服务的滚动升级等场景非常有效。
在大多数情况下,我们希望Deployment创建的Pod副本被调度到集群的任何一个可用节点,而不是某一个节点。
但是在某些情况下,我们希望某个Pod副本全部在指定的一个或一些节点上运行,
比如我们希望MySQL数据库全部被调度到一个具有SSD磁盘的目标节点上。
我们只需要使用Pod模板中的NodeSelector属性就可以了。操作步骤如下:
(1)把具有SSD磁盘的Node打上标签“disk=ssd”
(2)在Pod模板中设定NodeSelector的值为“disk:ssd”
这样Kubernetes在调度Pod副本的时候,就会先按照Node的标签过滤出合适的目标节点。
上述解决方案貌似可行,但是在生产环境中会有更加复杂的需求,比如:
A.比如NodeSelector选择的Node不存在或者不符合条件,比如目标节点宕机或者资源不足该怎么做了?
B.如果要选择多种合适的目标节点
针对上述需求,Kubernetes引入了NodeAffinity(节点亲和性设置)来解决该需求。
真实环境下可能还有如下需求:
A.不同Pod之间的亲和性(Affinity)。
比如mysql和redis不能够调度到一个Node上,这就是PodAffinity需要解决的问题。
B.有状态集群的调度
对于MongoDB、Etcd等有状态的服务需要持久化的保存数据,而Pod是短暂的,StatefulSet可以解决此类问题。
C.在每个节点上并且仅仅创建一个Pod副本。
常用于系统监控相关的Pod,这是DaemonSet需要解决的问题。
D.对于批处理作业,需要创建多个Pod副本来协同工作,当这些Pod副本都完成自己的任务时,整个批处理作业就结束了。
这种只需要有且只运行一次的Pod,可以使用CronJob来解决。
与单独的Pod实例不同,由RC、ReplicaSet、Deployment、DaemonSet等这些控制器创建的Pod副本都归属于这些控制器。
那就产生了一个问题,如果控制器被删除,这些控制器下面的Pod会怎样了?
在1.9版本之前,删除控制器,控制器下面的Pod不会被删除;
在1.9版本之后,删除控制器,控制器下面的Pod也会被删除,
可以在使用kubectl创建的时候指定--cascade=false来取消这一特性。
Deployment和RC在很多时候可以任意使用,其功能性基本一致。
二者主要用来自动部署一个容器应用的多个副本,以及持续监控副本的数量,使其持续保持在一个期望状态。
下面是一个简单实例:
apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment spec: replicas: 3 #deployment下一层级是pod,这是pod副本的数量 selector: matchLabels: app: nginx template: #创建pod的模板 metadata: #pod副本的元数据 labels: app: nginx #Pod的标签 spec: containers: #pod的下一层级时容器 - name: niginx #容器名称,会随机命名 image: nginx #镜像名称 imagePullPolicy: Never ports: #容器的端口号 - containerPort: 80
相关操作:
#创建deployment资源 root@console:/k8s-script/chapter02# kubectl create -f nginx-deployment.yaml deployment.apps "nginx-deployment" created #查看已经创建的deployment,通过UP-TO-DATE就可以知道Pod的创建进度 root@console:/k8s-script/chapter02# kubectl get deployment NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE nginx-deployment 3 3 3 3 15s #查看deploy创建的Pod root@console:/k8s-script/chapter02# kubectl get pods NAME READY STATUS RESTARTS AGE nginx-deployment-5999675b6d-25l6r 1/1 Running 0 24s nginx-deployment-5999675b6d-2nwrh 1/1 Running 0 24s nginx-deployment-5999675b6d-l7qmh 1/1 Running 0 24s
你在创建一个控制器的时候,你是不能给控制器下面的Pod命名的,kubernetes会在控制器名称的基础上随机命名。
因为Pod是短暂性的,控制器维护的pod可能随时被删除然后创建一个新的Pod。
当然,如果你直接创建Pod资源对象,那就必须给它命名了。
从调度策略上来说,这三个Nginx Pod由系统全自动完成调度,他最终运行在那个节点上,
完全由Master的Scheduler经过一系列算法计算得出,用户无法干预调度过程和结果。
当然,除了系统自动调度算法完成调度和部署,Kubernetes也提供了多种丰富的调度策略。
只需要在Pod的定义中使用NodeSelector、NodeAffinity、PodAffinity等策略。
master上面的Scheduler组件专门用来负责Pod的调度。
Scheduler会经过一系列复杂的算法,最终为每个Pod计算出一个最终的目标节点,这是系统默认的调度策略。
通常情况下,我们是不可能知道那个Pod最终会部署在那个节点上了,
但是无独有偶,某个时候某个pod就是需要部署到某个特定的服务器上,这种情况是存在的。
这种情况我们就可以通过Node节点的label属性和pod节点上的nodeSelector属性来达到目的。
具体的操作分为如下两步:
root@console:/k8s-script/chapter02# kubectl label nodes centos02 zone=north root@console:/k8s-script/chapter02# kubectl get nodes/centos02 --show-labels NAME STATUS ROLES AGE VERSION LABELS centos02 Ready <none> 2d v1.10.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/hostname=centos02,zone=north
apiVersion: v1 kind: ReplicationController metadata: name: redis-master spec: replicas: 1 selector: #必须要有slector,不然无法识别目标pod name: redis-master template: #在控制器中创建Pod必须要使用模板 metadata: labels: name: redis-master spec: containers: - name: redis-master image: kubeguide/redis-master:latest ports: - containerPort: 6379 nodeSelector: zone: north
#创建资源对象 root@console:/k8s-script/chapter02# kubectl create -f redis-master.yaml replicationcontroller "redis-master" created #已经定向调度到了centos02上面 root@console:~# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE redis-master-wxcgf 1/1 Running 0 15h 10.40.0.1 centos02
如果我们给多个Node都定义了相同的标签,则scheduler会根据调度算法从这组Node中挑选一个可用的Node进行Pod调度。
通过基于Node标签的调度方式,我们可以把集群中具有不同特点的Node都贴上不同的标签。
在部署应用时就可以根据应用的需求设置NodeSelector来进行指定Node范围的调度。
如果我们指定了Pod的nodeSelector条件,且在集群中不存在包含相应标签的Node,
则即使在集群中还有其它可供使用的Node,这个Pod也无法被调度成功。
root@console:~# kubectl get nodes --show-labels=true NAME STATUS ROLES AGE VERSION LABELS centos01 Ready <none> 3d v1.10.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/hostname=centos01 centos02 Ready <none> 3d v1.10.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/hostname=centos02,zone=north centos03 Ready <none> 3d v1.10.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/hostname=centos03 console Ready master 3d v1.10.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/hostname=console,node-role.kubernetes.io/master=
除了用户可以自行给Node添加标签,Kubernetes也会给Node预定义一些标签:
kubernetes.io/hostname:Node主机名称
beta.kubernetes.io:Node节点的系统
beta.kubernetes.io/arch:Node节点的处理器类型
这些系统标签有时候也可以实现Pod的定向调度。
通过NodeSelector定向调度的方式,可以非常简单的限制Pod所在的节点,但是这种方式依旧非常粗糙。
亲和性调度机制则极大的扩展了Pod的调度能力,主要的增强功能如下:
更具表达力(nodeSelector只能实现是否的判断)
可以使用软限制、优先采用等限制,这样不会出现nodeSelector如果没有出现匹配的Node则Pod无法被调度成功的情况。
可以依据节点上正在运行的其它Pod的标签来进行限制,而非节点本身的标签,这样就可以定义一种规则来描述Pod之间的亲和或互斥关系。
亲和性调节功能包括节点亲和性(NodeAffinity)和Pod亲和性(PodAffinity)两个维度的设置。
NodeSelector将会继续使用,随着NodeAffinity功能性的增强,最终NodeSelector将可能被废弃。
NodeAffinity是用来进行Node亲和性调度策略的,是用来替换NodeSelector的全新调度策略。目前有两种节点亲和性表达。
RequiredDuringSchedulingIgnoredDuringExecution:必须满足指定的规则才可以调度Pod到Node上,相当于硬限制。
PreferreDuringSchedulingIgnoredDuringExecution: 强调优先满足指定规则,调度器会尝试调度Pod到Node上,但并不请求,相当于软限制。
多个优先级规则还可以设置权重(weight)值,以定义执行的先后顺序。
IgnoredDuringExecution的意思是:如果一个Pod所在的节点在Pod运行期间标签发生了变更,不再符合该Pod的节点亲和性需求,
则系统将忽略Node上Label的变化,该Pod能继续在节点上运行。
下面是一个简单实例:
apiVersion: v1 kind: Pod metadata: #Pod元数据 name: nodeaffinity-test spec: affinity: #亲和度配置 nodeAffinity: #节点亲和度 requireDuringSchedulingIgnoreDuringExecution: #硬配置 nodeSelectorTerms: - mathExpressions: - key: beta.kubernetes.io/arch operator: In #支持包括:In、NotIn、Exists、DoesNotExist、Gt、Lt values: - amd64 preferredDuringSchedulingIgnoreDuringExecution: #软配置 - weight: 1 preference: matchExpressions: - key: disk-type operator: In values: - ssd containers: - name: nodeaffinity-test image: nginx:1.7.9
虽然没有节点排斥功能,但是用NotIn和DoesNotExist就可以实现排斥的功能了。
NodeAffinity规则设置如下:
如果同时定义了nodeSelector和nodeAffinity,那么必须两个条件都满足,Pod才能最终运行在指定的Node上。
如果nodeAffinity制定了多个nodeSelectorTerms,那么其中一个能够匹配成功即可。
如果在nodeSelectorTerms中有多个matchExpressions,则一个节点必须满足所有matchExpressions。
Pod间的亲和与互斥从kubernetes1.4版本开始引入,
它从另一个角度来限制Pod所能运行的节点,即根据节点上正在运行的Pod的标签而不是节点的标签来判断和调度。
apiVersion: v1 kind: Pod metadata: name: pod-flag labels: security: "S1" app: "nginx" spec: containers: - name: nginx image: nginx
我们希望启动的pod与pod-flag运行在同一个节点上
apiVersion: v1 kind: Pod metadata: name: pod-affinity spec: affinity: #亲和性设置 podAffinity: #pod亲和设置 requiredDuringSchedulingIgnoredDuringExecution: #硬性设置 - labelSelector: matchExpressions: #匹配条件 - key: security operator: In values: - S1 topologyKey: kubernetes.io/hostname containers: - name: pod-affinity image: waychan23/google-containers_pause:2.0
相关操作:
root@console:/k8s-script/chapter02/affinity# kubectl create -f af-test.yaml pod "pod-affinity" created #查看pod资源,发现两个pod都运行在centos03节点上。 root@console:/k8s-script/chapter02/affinity# kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE pod-affinity 1/1 Running 0 28s 10.38.0.2 centos03 pod-flag 1/1 Running 0 9m 10.38.0.1 centos03
现在我们不想和pod-flag这个pod运行在一个节点上
apiVersion: v1 kind: Pod metadata: name: pod-mutually spec: affinity: podAntiAffinity: #互斥性设置 requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - nginx topologyKey: kubernetes.io/hostname containers: - name: anti-affinity image: waychan23/google-containers_pause:2.0
相关操作:
root@console:/k8s-script/chapter02/affinity# kubectl create -f mx-test.yaml pod "pod-mutually" created #创建pod后,pod-mutually这个pod确实并没有运行在centos03这个节点上 root@console:/k8s-script/chapter02/affinity# kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE pod-affinity 1/1 Running 0 19m 10.38.0.2 centos03 pod-flag 1/1 Running 0 27m 10.38.0.1 centos03 pod-mutually 1/1 Running 0 6m 10.46.0.0 centos01
PodAffinity是Pod定义的一种属性,用来限制Pod运行的节点。
NodeSelector、NodeAffinity、PodAffinity都是在Pod中定义的。
NodeSelector是Pod在部署的时候用来选择符合条件的某些特殊Node。NodeSelector是一种硬性限制。
NodeAffinity相对NodeSelector来说是一种软限制,可以说操作的范围更大。
NodeSelector与NodeAffinity参草的对象都是Node,而PodAffinity参考的对象是Node上运行的Pod,
这样在某些情况下,针对性会更加准确。
上面几种有关定向调度的方式,都是在Pod中定义,从Pod的角度来筛选。
而Taint是从Node的角度定义,从而主动拒绝某些pod在其上部署运行。
Taint需要配合Toleration来使用,让Pod避开那些不合适的Node。
在Node上设置一个或多个Taint之后,除非在你的Pod的定义中显式的声明可以容忍这个Taint,否则该Pod就不会在该Node上运行。
Toleration是Pod的属性,让Pod能够运行在设置了Taint的Node上。
下面命令就在centos01节点上了设置了Taint,键为key,值为value,策略为NoSchedule(不被调度)。
kubectl taint nodes centos01 key=value:NoSchedule
设置这个Taint之后,如果Pod中没有声明容忍这个Taint那么Pod就不会被调度到该Node上运行。
如果你需要声明容忍某个Taint,你可以有以下两种方式:
tolerations: - key: “key” operator: “Equal” value: “value” effect: “NoSchedule” #方式二: tolerations: - key: “key” operator: “Exists” effect: “NoSchedule”
Pod中声明的Tolerarion必须与Node上定义的Taint保持一致,否则容忍就会失败。
在定义Toleration的定义中,如果operator使用“Exists”选项,那么无需指定value。
需要注意的是,空的key配置“Exists”可以匹配所有的Taint,这样Pod将无视所有的Taint。
空的effect可以匹配所有的值,这样可以省略具体的值。
Taint的effect策略一般有三种:
NoSchedule:Pod不能被调度到本节点上
PreferNoSchedule:优先不被调度,就是就是尽量避免将Pod调度到本节点上,这是一个软限制。
NoExecute:与NoSchedule类似,不能被调度,更厉害的是,如果这个Pod已经在该节点上运行则会立即被驱逐,也就是被转移到其它节点。
一般来说,如果给Node添加了effect为NoExecute的Taint之后,Node上的所有Pod都会被马上驱逐,除了设置了Toleration的Pod之外。
此外,kubernetes还给Toleration提供了tolerationSeconds字段,意思是在Node设置了Taint之后,那些不合法的Pod还能运行多久。
下面是一个简单实例:
tolerations: - key: “key” operator: “Exists” effect: “NoExecute” tolerationSeconds: 3600
意思就是,在加入了Taint之后,不合法的马上被驱逐,合法的在运行了3600s后也会被强制驱逐。
但是如果在这个过程中Taint被删除,那么并不会被驱逐。
系统允许在一个Node设置多个Taint,同样,在一个Pod上也可以设置多个Toleration。
Kubernetes的处理器在处理多Taint和多Toleration时的逻辑时:
首先需要明确的是这个逻辑判断的过程发生在Pod的创建过程中。
处理器会列出所有节点的Taint,然后忽略掉Toleration中能够匹配的那部分,剩下的就是对Pod真实有效的Taint了。
以下是几种情况实例:
A.剩余的Taint中存在NoSchedule策略的,那么这个Pod就不会被调度到对应的节点上。
B.剩余的Taint中存在PreferNoSchedule策略的,那么这个Pod尽量不被调度对应的节点上。
C.剩余的Taint中存在NoExecute策略的,如果该Pod已经在上面运行,那么立即驱逐,如果没有也不会被调度到这些节点上。
Taint和Toleration是一种处理节点并且让Pod进行规避或者驱逐Pod的弹性处理方式。
比如一台拥有大存储的机器更希望被耗内存的应用部署,比如redis。
很多公司的架构设计这一环节上,特别应对高并发的架构设计,可能会有服务降级的配套方案。
比如说淘宝为了满足双11的高并发,在机器负载已经达到最大的时候可能会关闭评论这一块的服务,以此满足订单服务的资源需求。
而决定服务是否可能被降级的关键是——优先级配置。
另一方面,在互联网领域,硬件资源其实是非常昂贵的,
如果你单纯为了保证服务的可用性,而给服务留下了太多的资源可用空间,可能是一笔不小的开销。
在保证硬件资源利用率之后,可能又会出现另外的一个更大的问题——由于资源不足,导致核心服务不可用。
常见的做法是给不同服务设置不同的优先级,同时允许集群负载所需的资源总量大于集群可提供的资源总量,
只要永远保证核心服务可用就行,这样整个服务就可以说整体可用。
在Kubernetes1.8之前了,当系统资源不足的时候,用户提交新的Pod请求后,该Pod可能一直处于pending状态,
只有等到其它Pod被删除并释放资源之后,才可能被调度成功。
在kubernetes1.8版本中引入了基于Pod的优先级抢占的调度策略。
当资源不足的时候,Kubernetes会释放目标节点上低优先级的Pod,以腾出资源去安置高优先级的Pod。
这种调度策略被称为“抢占式调度”,在kubernetes1.11版本中,该特性升级为beta(公测)版本,默认开启。
在后继的Kubernetes1.14中升级为Release(发布)版本。
那么我们如何衡量一个负载相对于另一个负载更重要了?一般会有如下几个维度:
Priority,优先级
QoS,服务质量等级
系统定义的其它度量指标
优先级抢占调度策略的核心行为分别是驱逐(Eviction)与抢占(Preemption)。
Eviction是kubelet进程的行为,即当一个Node发生资源不足的情况时,该节点上的kubelet进程会执行驱逐动作。
此时kubelet会去综合考虑Pod的优先级、资源申请量与实际使用量等信息来计算那些Pod需要被驱逐。
当同优先级的Pod需要被驱逐的时候,实际资源使用量超过资源申请量倍数最大的高耗能Pod会被首先驱逐。
对于QoS等级为“Best Effort”的Pod来说,由于没有定义资源申请,实际使用的资源可能非常大。
Preemption则是Scheduler执行的行为,当一个新的Pod因为资源无法满足而不能被调度时,
Scheduler可能(有权决定)选择驱逐部分低优先级的Pod实例来满足此Pod的调度目标,这就是Preemption机制。
需要注意的是,一旦你进行了优先级配置,可能会间接的导致未知节点的未知服务被驱逐或者停止。
比如,A和B属于同一个区域,B的优先级更高,AB二者设置了互斥性,如果此时B等待调度,资源又不足,
那么此区域内某个节点上的某个或多个A类型的Pod可能被驱逐。所以驱逐和抢占动作操作对象可能并不是一个Pod、一个Node。
优先级抢占的调度方式可能导致调度陷入“死循环”。
比如ScheduleA为了调度一个或一批Pod,特地驱逐了一批Pod来腾出资源,
但是在ScheduleA准备部署运行的时候,ScheduleB已经抢先一步调度了另一批Pod,
这样导致ScheduleA又没有可用资源了,这样就导致“驱逐与被驱逐”的死循环。
使用优先级抢占资源的调度策略可能会导致某些Pod永远无法被成功调度。
优先级调度不但增加了系统的复杂性,还可能带来额外的不稳定因素。
DaemonSet是Kubernetes1.2版本新增的一种资源对象,用于管理在集群中每个Node上仅运行一份Pod的副本实例。
比如以下场景:
在每个Node上都运行一个GlusterFS存储或者Ceph存储的Daemon进程。
在每个Node上都运行一个日志采集程序,例如Fluentd或者Logstach。
在每个Node上都运行一个性能监控程序,采集该Node的运行性能数据。
DaemonSet的Pod调度策略与RC类似,除了使用系统内置的算法在每个Node上进行调度,
也可以在Pod的定义中使用NodeSelector或NodeAffinity来满足条件的Node范围进行调度。
在Kubernetes1.6以后的版本中,DaemonSet也能执行回滚动升级,即在更新一个DaemonSet模板的时候,
旧的Pod副本会被自动删除,同时新的Pod副本会被自动创建。
Kubernetes从1.2版本开始支持批处理类型的应用,
我们可以通过kubernetes Job资源对象来定义并启动一个批处理任务。
批处理任务通常并行(或者串行)启动多个计算进程去处理一批工作项(work item),处理完成后,整个批处理任务结束。
按照批处理任务实现方式的不同,批处理任务可以有如下几种模式:
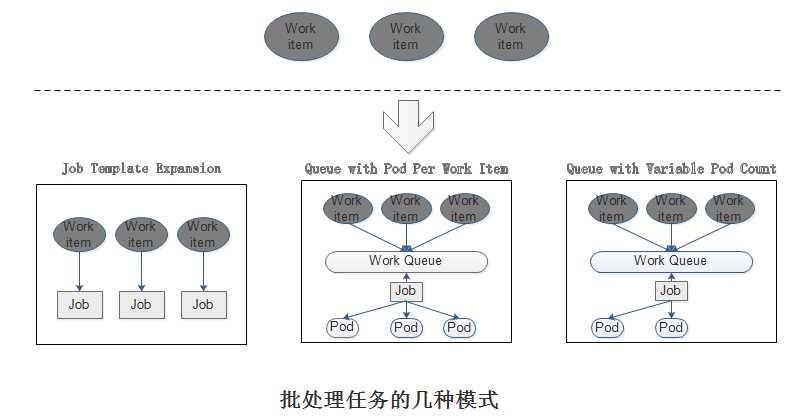
(1)Job Template Expansion
一个Job对象对应一个待处理的Work item,有几个Work item就产生几个独立的Job,
通常适合Work item数量少、每个Work item要处理的数据量比较大的场景。
(2)Queue with Pod Per work Item
采用一个任务队列存放Work item,一个Job对象作为消费者去完成这些Work item,
这种模式下,Job会启动N个Pod,每个Pod都对应一个Work item。
(3)Queue with Variable Pod Count
采用一个任务队列存放Work item,一个Job对象作为消费者去完成这些Work item,
但与上面模式不同的是,Job启动的Pod数量是可变的。
(4)Single Job with Static Work Assignment
一个Job产生多个Pod,采用程序静态方式分配任务项,而不是采用队列模式进行动态分配。
考虑到批处理的并行问题,Kubernetes将Job分为以下三种类型。
(1)Non-parallel Jobs
通常一个Job只启动一个Pod,除非Pod异常,才会重启该Pod,一旦此Pod正常结束,Job将结束。
(2)Parallel Jobs with a fixed completion count
并行Job会启动多个Pod,此时需要设定Job的spec.completions参数为一个正数,当正常结束的Pod数量达到此参数设定的值后,Job结束。
此外,Job的spec.parallelism参数用来控制并行度,即同时启动几个Job来处理Work Item。
(3)Parallel Job with a work queue
任务队列方式的并行Job需要一个独立的Queue,Work item都在一个Queue中存放,不能设置Job的spec.completions参数,
此时Job有以下特性:
每个Pod都能独立判断和决定是否还有任务项需要处理。
如果某个Pod正常结束,则Job不会再启动新的Pod。
如果一个Pod成功结束,则此时应该不存在其它Pod还在工作的情况,它们应该都处于即将结束、退出的状态。
模式一的简单实例:
apiVersion: batch/v1 kind: Job metadata: name: process-item-$ITEM labels: jobgroup: jobexample spec: template: metadata: name: jobexample labels: jobgroup: jobexample spec: containers: - name: c image: busybox:latest command: ["sh","-c","echo Processing item $ITEM && sleep 5"] restartPolicy: Never
相关操作:
root@console:/k8s-script/chapter02# for i in apple banana cherry; do cat job.yaml.txt | sed "s/\$ITEM/$i/" > ./jobs/job-$i.yaml; done root@console:/k8s-script/chapter02# kubectl create -f jobs job.batch "process-item-apple" created job.batch "process-item-banana" created job.batch "process-item-cherry" created root@console:/k8s-script/chapter02# kubectl get jobs NAME DESIRED SUCCESSFUL AGE process-item-apple 1 0 20s process-item-banana 1 1 20s process-item-cherry 1 0 20s
Kubernetes从1.5版本开始增加了一种新型的Job,即类似Linux Cron的定时任务Cron Job。
如果你要使用CronJob需要确保Kubernetes的版本为1.8以上。
CronJob的表达式基本与Linux中的Cron表达式完全一致。
# Example of job definition: # .---------------- minute (0 - 59) # | .------------- hour (0 - 23) # | | .---------- day of month (1 - 31) # | | | .------- month (1 - 12) OR jan,feb,mar,apr ... # | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat # | | | | | # * * * * * user-name command to be executed
简单示例:
apiVersion: batch/v1beta1 kind: CronJob metadata: name: hello spec: schedule: "*/1 * * * *" jobTemplate: spec: template: spec: containers: - name: hello image: busybox:latest args: - /bin/sh - -c - date;echo Hello from the Kubernetes cluster restartPolicy: OnFailure
上面定义了一个名为hello的Cron Job,每隔一分钟执行一次。
#查看CronJob的运行现状: root@console:/k8s-script/chapter02# kubectl get jobs --watch NAME DESIRED SUCCESSFUL AGE hello-1562846460 1 0 9m hello-1562846520 1 0 8m hello-1562846580 1 0 7m hello-1562846700 1 0 5m hello-1562846880 1 1 2m hello-1562846940 1 1 1m hello-1562847000 1 1 35s #然后可以查看对应日志: root@console:/k8s-script/chapter02# kubectl get pods NAME READY STATUS RESTARTS AGE hello-1562846460-vlndj 1/1 Running 0 10m hello-1562846520-j4wcs 1/1 Running 0 9m hello-1562846580-ctvwv 1/1 Running 3 8m hello-1562846700-pv96p 1/1 Running 0 6m hello-1562846880-dhvrp 0/1 Completed 0 3m hello-1562846940-4r2l5 0/1 Completed 0 2m hello-1562847000-7ncbm 0/1 Completed 0 1m hello-1562847060-494tj 0/1 ContainerCreating 0 7s root@console:/k8s-script/chapter02# kubectl logs hello-1562846520-j4wcs Thu Jul 11 12:02:12 UTC 2019 Hello from the Kubernetes cluster
标签:art 主机名 异常 重启 let sel 特性 fail 逻辑判断
原文地址:https://www.cnblogs.com/yangmingxianshen/p/12639061.html