标签:官方 file serve 解决办法 failed 引用 查看系统 arch map函数
2018年xx月xx日 下午4点20分左右 xxx无意中看到xxx正在排查线上Kafka集群遇到的问题,随后问明情况,有一台机器上Kafka进程挂了,当时他正在lark平台上查看错误日志信息,随后我一起加入排查问题。
事故起止时间:2018年xx月xx日 16时30分~2018年9月13日 17时25分
业务影响:理论上无影响,业务自动容错,生产和消费读写失败重试路由到其他Kafka节点上。
参与处理人:xxx、xxx
2018年xx月xx日 16时42分 xxx查看lark日志,分析错误日志
2018年xx月xx日 16时48分 xxx登录Kafka机器10.136.40.2 查看系统参数
2018年xx月xx日 16时55分 xxx整理系统优化参数列表
2018年xx月xx日 17时12分 xxx修改系统参数
2018年xx月xx日 17时25分 xxx通过开源cloudera平台重启Kafka服务,观察日志,启动正常
1.查看lark错误日志

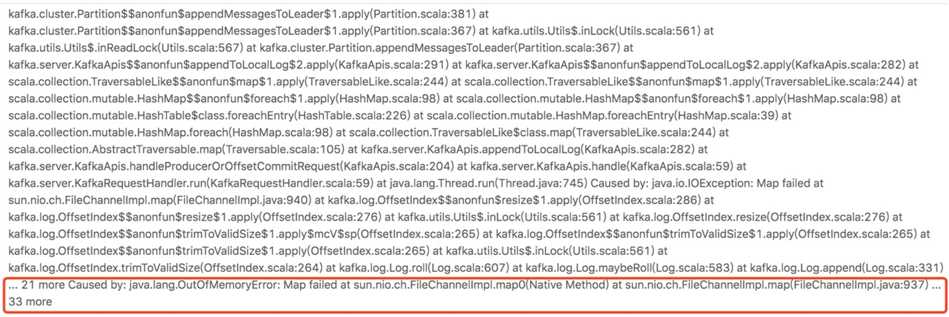
看到 more Caused by: java.lang.OutOfMemoryError: Map failed at sun.nio.ch.FileChannelImpl.map0(Native Method) 错误
登录上机器(ssh 10.136.40.2)查看:
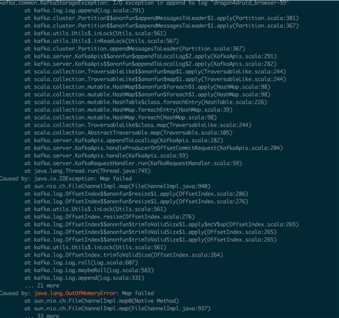
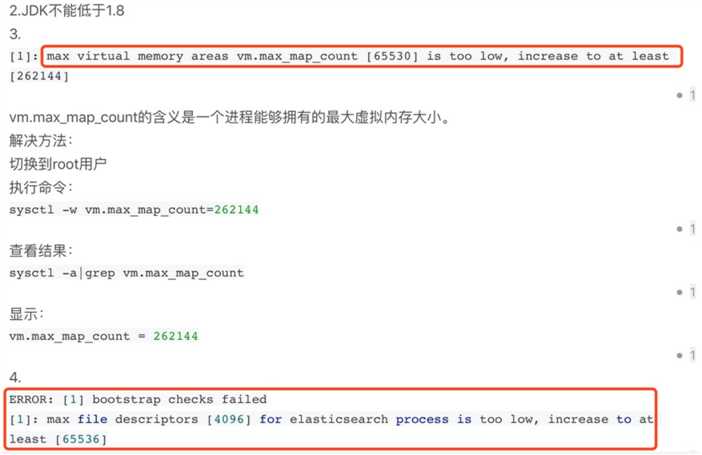
如上图不是jvm heap OutofMemoryError报错,是新创建索引文件做mmap内存映射时报错,通过判断分析,很可能是max_map_count数量不足导致的。
google搜索问题原因:https://stackoverflow.com/questions/43042144/kafka-server-failed-to-start-java-io-ioexception-map-failed

基本确定是max_map_count配置过低导致的
查看系统参数配置
[worker@c3-d13-136-40-2 kafka]$ sudo sysctl -a | grep "max_map_count"
vm.max_map_count = 65530
通过Kafka系统参数配置,想到了elastic search启动前强制配置系统参数,否则启动报错
es中vm.max_map_count参数配置
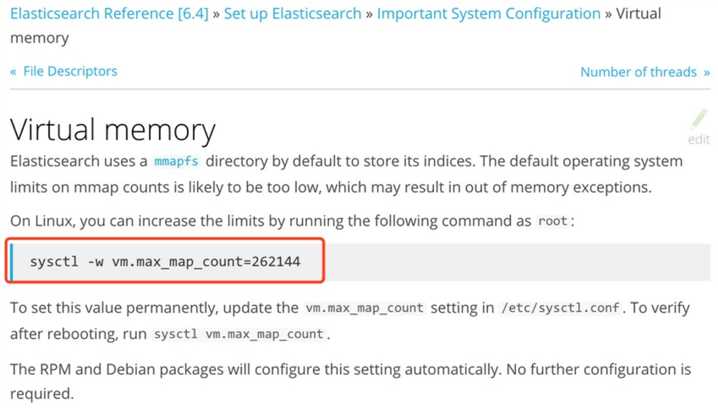
es启动强制优化的做法,值得借鉴
为什么会出现此次故障
为什么缺乏监控报警系统
为什么Kafka集群线上运行情况不掌握,不了解
为什么系统未做参数优化
名词解释:进程中虚拟内存映射区域的最大数量。
官方解释:https://www.oschina.net/translate/understanding-virtual-memory?print
max_map_count文件包含限制一个进程可以拥有的VMA(虚拟内存区域)的数量。虚拟内存区域是一个连续的虚拟地址空间区域。在进程的生命周期中,每当程序尝试在内存中映射文件,链接到共享内存段,或者分配堆空间的时候,这些区域将被创建。调优这个值将限制进程可拥有VMA的数量。限制一个进程拥有VMA的总数可能导致应用程序出错,因为当进程达到了VMA上线但又只能释放少量的内存给其他的内核进程使用时,操作系统会抛出内存不足的错误。如果你的操作系统在NORMAL区域仅占用少量的内存,那么调低这个值可以帮助释放内存给内核用。
百度质量部分析参考:http://www.10tiao.com/html/473/201606/2651473114/1.html

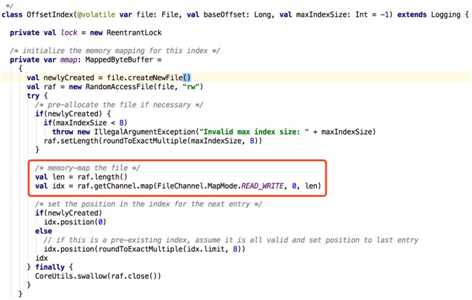
程序底层调研malloc、直接调用mmap和mprotect和加载共享库时、java中类FileChannel.map方法都会产生内存映射区域。
Kafka服务使用scala语言开发,运行与jvm平台上,因为jvm heap是预分配的内存,所以占用虚拟虚拟内存区域很少。在Kafka程序中占用最大是做文件映射(调用mmap函数),Kafka中存储分为数据文件和索引文件,数据文件直接读写不进行mmap映射,而索引文件为了加快读写速度就实现了mmap映射机制,每创建一个索引文件做一次虚拟内存映射,map_count数量就加1,直到当前map_count > 系统 max_map_count,就会抛出OutofMemoryError,接着java进程退出了。下面是索引文件做映射的代码
Kafka集群面临的风险
如果其他节点不进行系统参数优化,Kafka节点可能因为请求高峰或数据倾斜,也有挡掉的风险,所以Kafka集群所有的节点都要进行调整,防患于未然。下面TODO工作。
梳理系统参数列表 列出所有系统优化参数 xxx xx月xx日 DONE
编写脚本上线执行 提交工单,运维负责执行 xxx xx月xx日 DONE
博客地址引用:https://www.cnblogs.com/lizherui/p/12650254.html
caseStudy-20180913-Kafka进程挂掉&解决办法
标签:官方 file serve 解决办法 failed 引用 查看系统 arch map函数
原文地址:https://www.cnblogs.com/lizherui/p/12650254.html