标签:stream row connector 模式 env cer ora return red
下载地址: https://github.com/erdemcer/kafka-connect-oracle
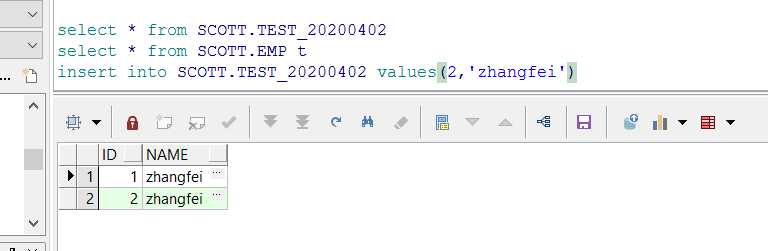
sqlplus / as sysdba SQL> shutdown immediate SQL> startup mount SQL> alter database archivelog; SQL> alter database open; SQL> alter database add supplemental log data (all) columns; SQL> conn username/password
1. 从https://github.com/erdemcer/kafka-connect-oracle下载整个项目,把整个项目mvn clean package成kafa-connect-oracle-1.0.jar 2. 下载一个oracle的jdbc驱动jar—ojdbc7.jar 3. 将kafa-connect-oracle-1.0.jar and ojdbc7.jar放在kafka的安装包下的lib目录下 4. 将github项目里面的config/OracleSourceConnector.properties文件拷贝到kafak/config
4. 配置相关文件
# vi /opt/cloudera/parcels/KAFKA/lib/kafka/config/OracleSourceConnector.properties
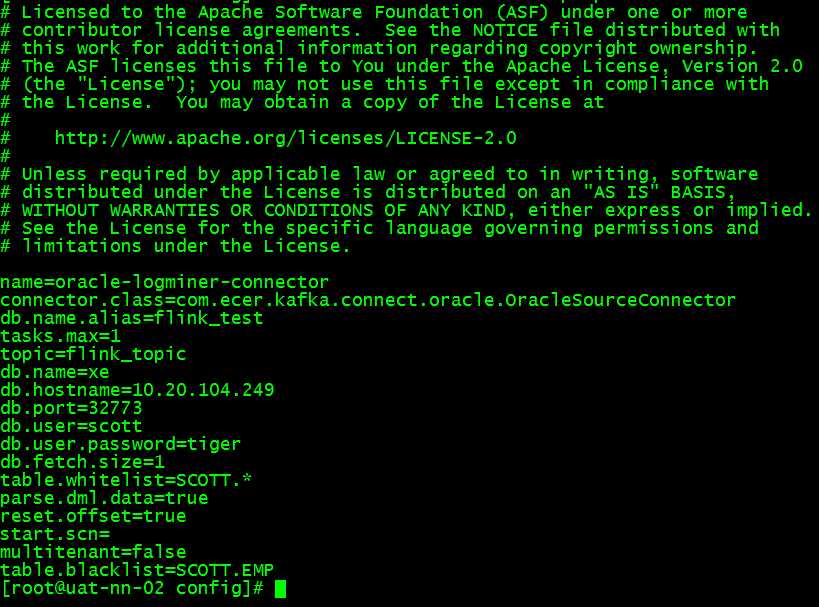
# vi /opt/cloudera/parcels/KAFKA/lib/kafka/config/connect-standalone.properties
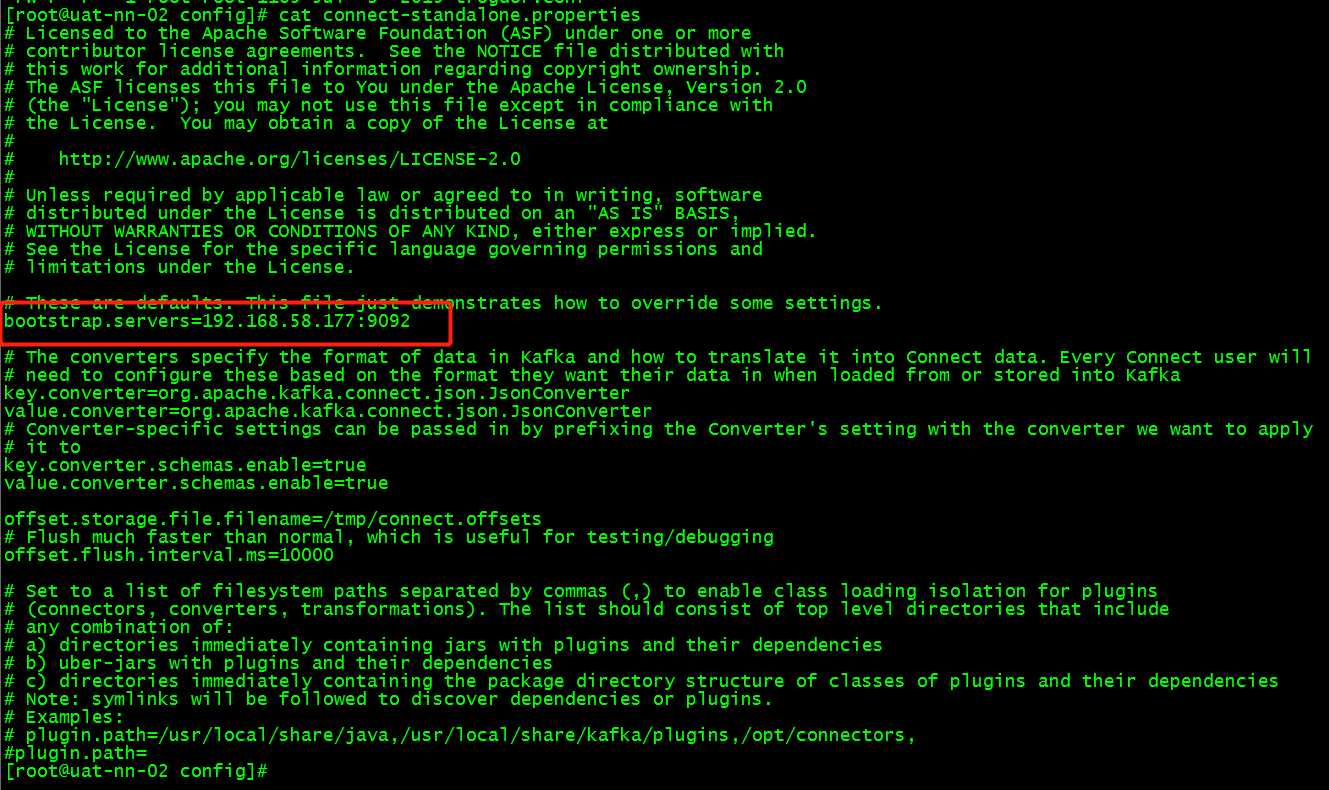
bin/connect-standalone.sh config/connect-standalone.properties config/OracleSourceConnector.properties
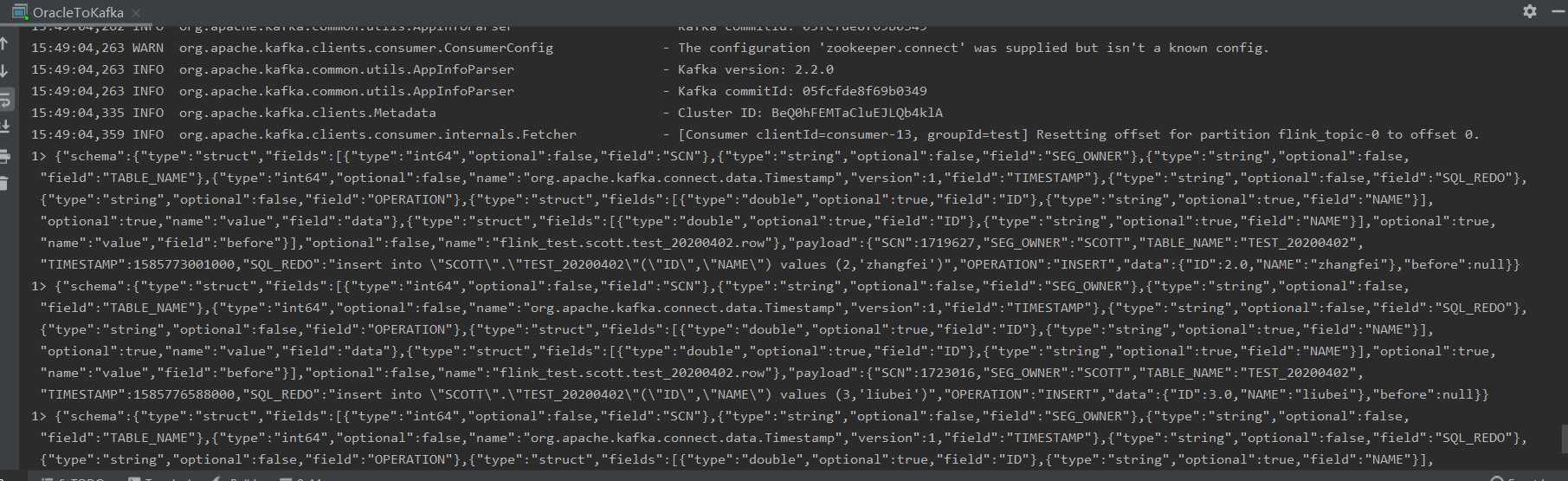
bin/kafka-console-consumer.sh --bootstrap-server 192.168.58.177:9092 --from-beginning --topic flink_topic

{"schema":{"type":"struct","fields":
[
{"type":"int64","optional":false,"field":"SCN"},
{"type":"string","optional":false,"field":"SEG_OWNER"},
{"type":"string","optional":false,"field":"TABLE_NAME"},
{"type":"int64","optional":false,"name":"org.apache.kafka.connect.data.Timestamp","version":1,"field":"TIMESTAMP"},
{"type":"string","optional":false,"field":"SQL_REDO"},
{"type":"string","optional":false,"field":"OPERATION"},
{"type":"struct","fields":
[
{"type":"double","optional":true,"field":"ID"},
{"type":"string","optional":true,"field":"NAME"}
],"optional":true,"name":"value","field":"data"},
{"type":"struct","fields":
[
{"type":"double","optional":true,"field":"ID"},
{"type":"string","optional":true,"field":"NAME"}
],"optional":true,"name":"value","field":"before"}
],"optional":false,"name":"flink_test.scott.test_20200402.row"},
"payload":
{
"SCN":1719627,
"SEG_OWNER":"SCOTT",
"TABLE_NAME":"TEST_20200402",
"TIMESTAMP":1585773001000,
"SQL_REDO":"insert into \"SCOTT\".\"TEST_20200402\"(\"ID\",\"NAME\") values (2,‘zhangfei‘)",
"OPERATION":"INSERT",
"data":{"ID":2.0,"NAME":"zhangfei"},
"before":null
}
}
public static void main(String[] args) throws Exception { StreamExecutionEnvironment Env = StreamExecutionEnvironment.getExecutionEnvironment(); Properties properties = new Properties(); properties.setProperty("bootstrap.servers", "192.168.58.177:9092"); properties.setProperty("zookeeper.connect", "192.168.58.171:2181,192.168.58.177:2181"); properties.setProperty("group.id", "test"); FlinkKafkaConsumer myConsumer = new FlinkKafkaConsumer("flink_topic",new SimpleStringSchema(),properties); //设置并行度 myConsumer.setStartFromEarliest(); //添加数据源,json格式 DataStreamSource<ObjectNode> stream = Env.addSource(myConsumer); stream.print(); Env.execute("flink_topic"); } public static class DataS{ public Integer id; public String name; public Integer getId() { return id; } public void setId(Integer id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } }
ORACLE的DDL日志 推送到Kafka,并接入Flink,进行统计
标签:stream row connector 模式 env cer ora return red
原文地址:https://www.cnblogs.com/yaowentao/p/12625956.html