标签:sklearn split 链接 取值 切割 show 色值 tail datasets
1. 应用K-means算法进行图片压缩
读取一张图片
观察图片文件大小,占内存大小,图片数据结构,线性化
用kmeans对图片像素颜色进行聚类
获取每个像素的颜色类别,每个类别的颜色
压缩图片生成:以聚类中收替代原像素颜色,还原为二维
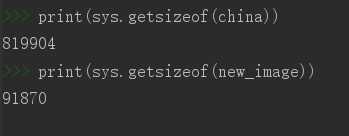
观察压缩图片的文件大小,占内存大小
from sklearn.datasets import load_sample_image from sklearn.cluster import KMeans import matplotlib.pyplot as plt import numpy as np import matplotlib.image as img import sys # 读取一张图片,观察图片存放数据特点 # 读取 datasets 库 中存在的图片china.jpg china = load_sample_image(‘china.jpg‘) # 显示图片 plt.imshow(china) plt.show() # 根据图片的分辨率,可适当降低分辨率 image = china[::3, ::3] # 减低尺寸/降低分辨率 ([::3] 意思就是从开始到结束,每三个取一个值。) x = image.reshape(-1, 3) # 生成行数未知,列数为3,如果维数发生改变,颜色就会混乱。 print(china.shape, image.shape, x.shape) # china.shape得到的是(横向上有多少的像素点,纵向上有多少的像素点,像素点的取值) plt.imshow(image) plt.show() # 再用k均值聚类算法,将图片中所有的颜色值做聚类。 # 得到的数据图china是一个三维的数组 :三维数组的最里面的第三个维度(也就是最里面的“[ ]”)代表的是一个像素点的RGB值:[红,黄,蓝], # 第二个维度代表的是这张图片的每一行的5个像素点的RGB值,第三个维度代表的就是这个图片。 # 文章的链接:https://blog.csdn.net/gaifuxi9518/article/details/88364167 # [红(共有255种),黄(共有255种),蓝(共有255种)] 因此共有255*255*255种取法。 n_colors = 64 # (256,256,256) # 定义聚类中心为64, 对像素点进行压缩 model = KMeans(n_colors) label = model.fit_predict(x) # 每个点颜色分类,0-63 对x先fit训练,再predict测试。 colors = model.cluster_centers_ # 二维(64,3)聚类中心 64种颜色,3个通道 new_image = colors[label].reshape(image.shape) # 然后用聚类中心的颜色代替原来的颜色值。 new_image = new_image.astype(np.uint8) # 类型转换,小数点转化为8位整形 plt.imshow(new_image) # 形成新的图片 plt.show() # 观察原始图片与新图片所占用内存的大小。 # sys.getsizeof()函数 查看占用空间的大小 sys.getsizeof(china) sys.getsizeof(new_image) # 将原始图片与新图片保存成文件,观察文件的大小。 # img.imsave()函数 保存在本地 存储图片文件 img.imsave(‘china.jpg‘,china) img.imsave(‘new_china.jpg‘,new_image)
原始图片:

压缩后的图片:

占用的空间大小:
2. 观察学习与生活中可以用K均值解决的问题。
从数据-模型训练-测试-预测完整地完成一个应用案例。
这个案例会作为课程成果之一,单独进行评分
预测天气的情况会对人们出行心情(想出去 和 不想出去)的影响:
from sklearn.cluster import KMeans
import numpy as np
from sklearn.model_selection import train_test_split
# 测试数据
data = np.array([[‘Sunny‘, ‘Hot‘, ‘High‘, ‘Weak‘],
[‘Sunny‘, ‘Hot‘, ‘High‘, ‘Strong‘],
[‘Overcast‘, ‘Hot‘, ‘High‘, ‘Weak‘],
[‘Rain‘, ‘Mild‘, ‘High‘, ‘Weak‘],
[‘Rain‘, ‘Cool‘, ‘Normal‘, ‘Weak‘],
[‘Rain‘, ‘Cool‘, ‘Normal‘, ‘Strong‘],
[‘Overcast‘, ‘Cool‘, ‘Normal‘, ‘Strong‘],
[‘Sunny‘, ‘Mild‘, ‘High‘, ‘Weak‘],
[‘Sunny‘, ‘Cool‘, ‘Normal‘, ‘Weak‘],
[‘Rain‘, ‘Mild‘, ‘Normal‘, ‘Weak‘],
[‘Sunny‘, ‘Mild‘, ‘Normal‘, ‘Strong‘],
[‘Overcast‘, ‘Mild‘, ‘High‘, ‘Strong‘],
[‘Overcast‘, ‘Hot‘, ‘Normal‘, ‘Weak‘],
[‘Rain‘, ‘Mild‘, ‘High‘, ‘Strong‘]])
Y = np.array([‘No‘, ‘No‘, ‘Yes‘, ‘Yes‘, ‘Yes‘, ‘No‘, ‘Yes‘, ‘No‘, ‘Yes‘, ‘Yes‘, ‘Yes‘, ‘Yes‘, ‘Yes‘, ‘No‘])
# 预测数据
X = np.array([[‘Sunny‘, ‘Cool‘, ‘High‘, ‘Strong‘]])
#对数据进行处理
# 对测试数据的处理
data[data == ‘Sunny‘] = 1
data[data == ‘Overcast‘] = 2
data[data == ‘Rain‘] = 3
data[data == ‘Hot‘] = 1
data[data == ‘Mild‘] = 2
data[data == ‘Cool‘] = 3
data[data == ‘High‘] = 1
data[data == ‘Normal‘] = 2
data[data == ‘Weak‘] = 1
data[data == ‘Strong‘] = 2
# 对预测数据的处理
Y[Y == ‘No‘] = 1
Y[Y == ‘Yes‘] = 2
X [X == ‘Sunny‘] = 1
X [X == ‘Cool‘] = 3
X [X == ‘High‘] = 1
# X [X == ‘Normal‘] = 2
# X [X == ‘Weak‘] = 1
X [X == ‘Strong‘] = 2
# 切割
Xtr,Xte,y_tr,y_te=train_test_split(data, Y, test_size=0.2)
#K-Mean算法
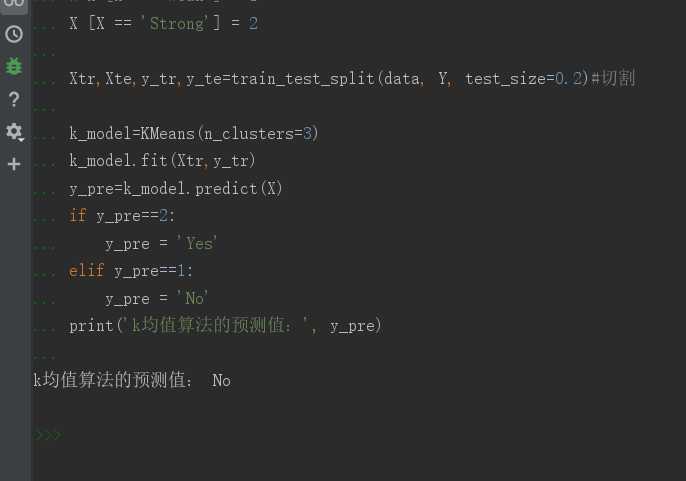
k_model=KMeans(n_clusters=3) # 3个聚类中心
k_model.fit(Xtr,y_tr) # 模型训练
y_pre=k_model.predict(X) #模型预测
if y_pre==2:
y_pre = ‘Yes‘
elif y_pre==1:
y_pre = ‘No‘
print(‘k均值算法的预测值:‘, y_pre)
展示的效果:
标签:sklearn split 链接 取值 切割 show 色值 tail datasets
原文地址:https://www.cnblogs.com/a131452/p/12719659.html