标签:ima 案例 lob 分词 数据集 sample obs 完成 transform
1. 应用K-means算法进行图片压缩
读取一张图片
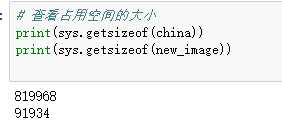
观察图片文件大小,占内存大小,图片数据结构,线性化
用kmeans对图片像素颜色进行聚类
获取每个像素的颜色类别,每个类别的颜色
压缩图片生成:以聚类中收替代原像素颜色,还原为二维
观察压缩图片的文件大小,占内存大小
from sklearn.datasets import load_sample_image from sklearn.cluster import KMeans import matplotlib.pyplot as plt import numpy as np import matplotlib.image as img import sys # 从库中读取一张照片 china = load_sample_image(‘china.jpg‘) # 显示原图片 plt.imshow(china) plt.show() # 压缩图片 image = china[::3, ::3] x = image.reshape(-1, 3) plt.imshow(image) plt.show() #使用机器学习K-Means算法压缩 # 定义聚类中心 n_colors = 64 model = KMeans(n_colors) #预测 label = model.fit_predict(x) colors = model.cluster_centers_ # 然后用聚类中心的颜色代替原来的颜色值。 new_image = colors[label].reshape(image.shape) # 图片转换为 8位无符号整型 new_image = new_image.astype(np.uint8) plt.imshow(new_image) plt.show()
第一张原图

第二张压缩图

第三张使用KMeans算法压缩图片

保存图片

查看原图和压缩图所占内存大小
2. 观察学习与生活中可以用K均值解决的问题。
从数据-模型训练-测试-预测完整地完成一个应用案例。
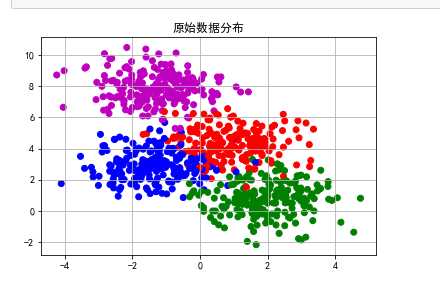
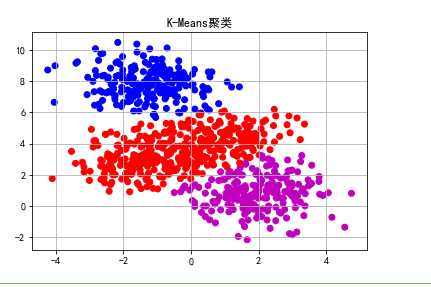
import matplotlib.pyplot as plt import sklearn.datasets as ds import matplotlib.colors #造数据 N=800 centers=4 # 生成2000个(默认)2维样本点集合,中心点5个 data,y=ds.make_blobs(N,centers=centers,random_state=0) #原始数据分布 #pylot使用rc配置文件来自定义图形的各种默认属性,包括窗体大小、每英寸的点数、线条宽度、颜色、样式、坐标轴、坐标和网络属性、文本、字体等。 matplotlib.rcParams[‘font.sans-serif‘] = [u‘SimHei‘] matplotlib.rcParams[‘axes.unicode_minus‘] = False cm = matplotlib.colors.ListedColormap(list(‘rgbm‘)) plt.scatter(data[:,0],data[:,1],c=y,cmap=cm) plt.title(u‘原始数据分布‘) plt.grid() plt.show() #使用K-Means算法 from sklearn.cluster import KMeans # n_clusters=k model=KMeans(n_clusters=3,init=‘k-means++‘) #聚类预测 y_pre=model.fit_predict(data) plt.scatter(data[:,0],data[:,1],c=y_pre,cmap=cm) plt.title(u‘K-Means聚类‘) plt.grid() plt.show()
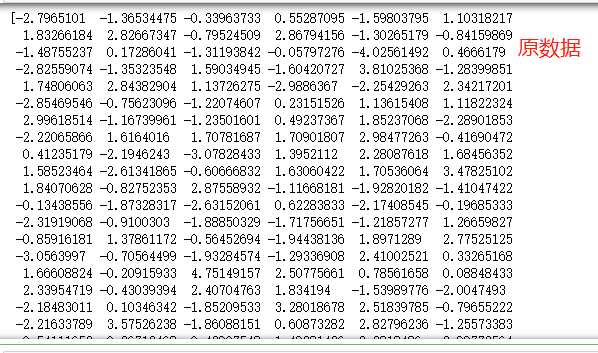
#查看原数据 print(data[:,0],data[:,1]) # 查看预测后数据 print(y_pre)

文本聚类
# -*- coding: utf-8 -*-
import os
import re
from os import listdir
import jieba
from sklearn import feature_extraction
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.cluster import KMeans
all_file=listdir(‘E:/201706120017赖志豪.txt‘) #获取文件夹中所有文件名#数据集地址
outputDir="E:/output.txt" #结果输出地址
labels=[] #用以存储名称
corpus=[] #空语料库
size=200#测试集容量
def buildSW():
‘‘‘停用词的过滤‘‘‘
typetxt=open(‘word.txt‘) #停用词文档地址
texts=[‘\u3000‘,‘\n‘,‘ ‘] #爬取的文本中未处理的特殊字符
‘‘‘停用词库的建立‘‘‘
for word in typetxt:
word=word.strip()
texts.append(word)
return texts
def buildWB(texts):
‘‘‘语料库的建立‘‘‘
for i in range(0,len(all_file)):
filename=all_file[i]
filelabel=filename.split(‘.‘)[0]
labels.append(filelabel) #名称列表
file_add=‘***‘+ filename #数据集地址
doc=open(file_add,encoding=‘utf-8‘).read()
data=jieba.cut(doc) #文本分词
data_adj=‘‘
delete_word=[]
for item in data:
if item not in texts: #停用词过滤
# value=re.compile(r‘^[0-9]+$‘)#去除数字
value = re.compile(r‘^[\u4e00-\u9fa5]{2,}$‘)#只匹配中文2字词以上
if value.match(item):
data_adj+=item+‘ ‘
else:
delete_word.append(item)
corpus.append(data_adj) #语料库建立完成
# print(corpus)
return corpus
def countIdf(corpus):
vectorizer=CountVectorizer()#该类会将文本中的词语转换为词频矩阵,矩阵元素a[i][j] 表示j词在i类文本下的词频
transformer=TfidfTransformer()#该类会统计每个词语的tf-idf权值
tfidf=transformer.fit_transform(vectorizer.fit_transform(corpus))#第一个fit_transform是计算tf-idf,第二个fit_transform是将文本转为词频矩阵
weight=tfidf.toarray()#将tf-idf矩阵抽取出来,元素a[i][j]表示j词在i类文本中的tf-idf权重
return weight
def Kmeans(weight,clusters,correct):
mykms=KMeans(n_clusters=clusters)
y=mykms.fit_predict(weight)
result=[]
for i in range(0,clusters):
label_i=[]
gp=0
jy=0
xz=0
ty=0
for j in range(0,len(y)):
if y[j]==i:
label_i.append(labels[j])
type=labels[j][0:2]
if(type==‘gp‘):
gp+=1
elif(type==‘jy‘):
jy+=1
elif(type==‘xz‘):
xz+=1
elif(type==‘ty‘):
ty+=1
max=jy
type=‘教育‘
if(gp>jy):
max=gp
type=‘股票‘
if(max<xz):
max=xz
type=‘星座‘
if(max<ty):
max=ty
type=‘体育‘
correct[0]+=max
result.append(‘类别‘+‘(‘+type+‘)‘+‘:‘+str(label_i))
return result
def output(result,outputDir,clusters):
outputFile=‘out‘
type=‘.txt‘
count=0
while(os.path.exists(outputDir+outputFile+type)):
count+=1
outputFile=‘out‘+str(count)
doc = open(outputDir+outputFile+type, ‘w‘)
for i in range(0,clusters):
print(result[i], file=doc)
print(‘本次分类总样本数目为:‘+str(size)+‘ 其中正确分类数目为:‘+str(correct[0])+‘ 正确率为:‘+str(correct[0]/size), file=doc)
doc.close()
texts=buildSW()
corpus=buildWB(texts)
weight=countIdf(corpus)
clusters=4
correct=[0]#正确量
result=Kmeans(weight,clusters,correct)
output(result,outputDir,clusters)
print(‘finish‘)
词频统计结果

标签:ima 案例 lob 分词 数据集 sample obs 完成 transform
原文地址:https://www.cnblogs.com/lzhdonald/p/12728449.html