标签:传统 nal 忽略 成长 相关 c中 任务 text 结构
1.序列数据:
自然语言
连续视频帧
股票走势
机器翻译
2.循环神经网络与传统神经网络的区别:
传统神经网络如多层感知机,每个隐藏层的节点之间是无连接的,而RNN则不然。有连接意味着有信息的流入,因此循环神经网络可以对序列数据进行预测和分类。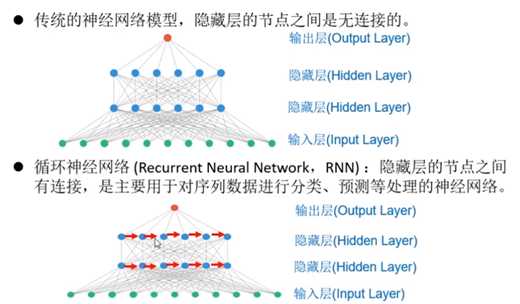
3.RNN序列处理
many 2 many :机器翻译
many 2 one: 情感分类
one 2 many : 图像标题生成
4.最基本的RNN计算过程
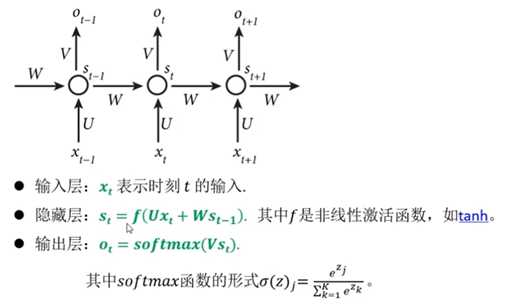
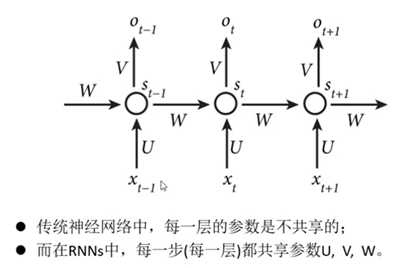
5.RNN的参数共享:
前后时间片的运算V W U参数完全一致,表明RNN中每一步做的都是相同的事,只是时间片输入不同。
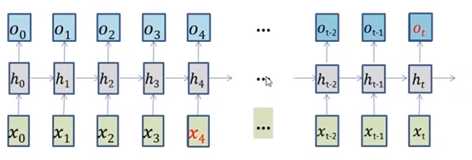
6.标准RNN的特点:(短期记忆,STM)
可以处理短期依赖: the clouds are in the ___.
难以应对长期依赖(更长的上下文间隔): I grew uo in France........... I speak ___.
7.RNN的扩展变体-------LSTM(Long-Short Term Memory),长短期记忆网络。(所谓的记忆其实就是一个向量)
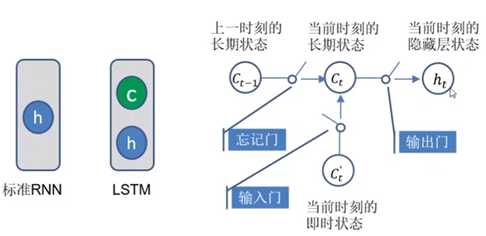
为形成长期记忆,网络结构中增加一个长期状态(单元/细胞状态)C。C中记录了过去直到现在所有经过的状态汇总。
因此,C需要继承上一时刻的长期状态Ct-1(忘记门),还需要针对当前时间片的输入(输入门)进行长期状态的更新。但是对两部分都不是完全照单接收,而是用门的方式控制实现信息的选择性流通。
输出门:控制如何使用当前时刻的长期状态Ct来更新当前时刻的隐层输出ht. 实现了ht对长期状态的保存,且后续利用ht计算 符合标准RNN的计算。
输入门:根据上一状态的输出值ht-1,对当前输入序列 xt 进行选择性的接收。
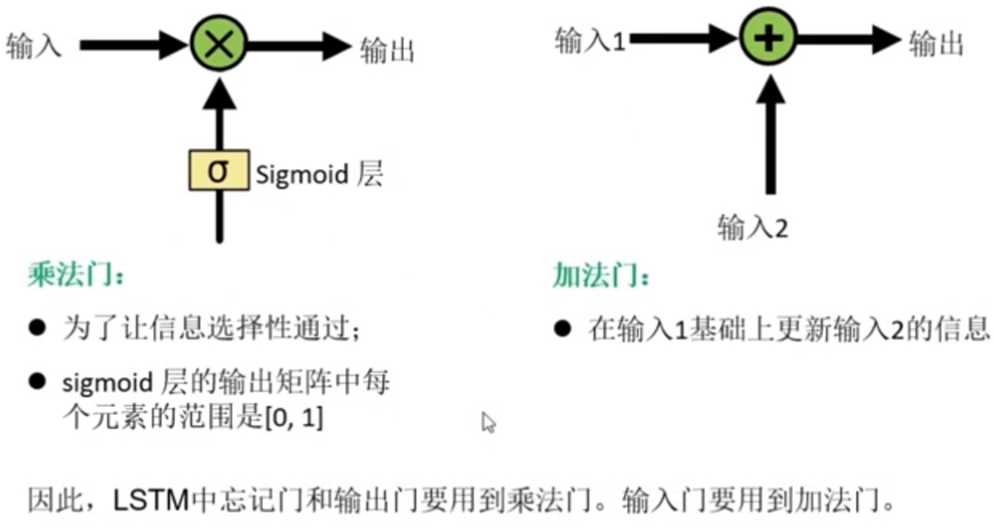
8.神经网络中的门
特点:逐点操作--对应位置直接相加或相乘,因此输入和输出之间的尺寸都是相同的。(对应点直接相乘得到新的点,即A11 = a11*b11,称为哈德马乘积)
sigmoid层的输出矩阵中为0的元素代表让输入中对应位置的元素信息完全不流通进来,而为1的元素则表示让输入中的对应位置元素信息完全流进来。
9.LSTM的整体框架图
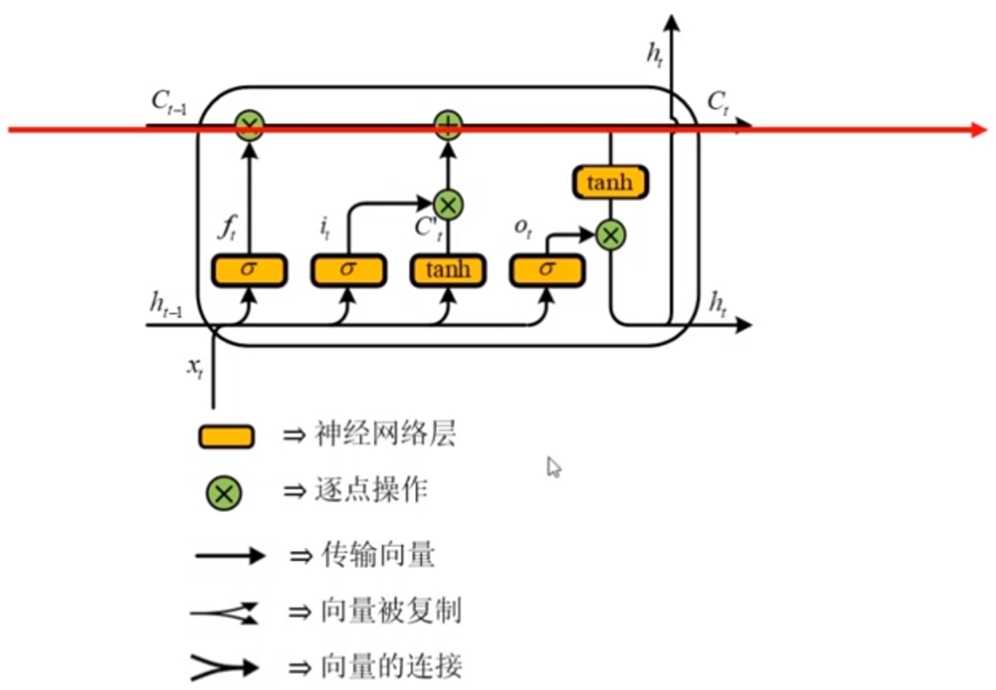
10.LSTM的计算过程
(1)忘记门 ft
信息的选择流通:实质是乘上一个(0,1)之间的数,通常是乘上一个被sigmoid激活后的隐层,sigmoid可以很方便将数值正规化到(0,1)
此处即根据对当前输入xt(France)和前一个隐层输出ht-1的内容,通过sigmoid激活输出(0,1)的矩阵 ft 前一个长期状态Ct-1选择性地过滤掉Germany信息

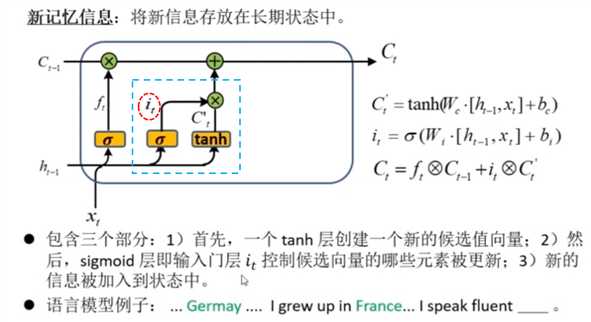
(2)输入门 it
通过与 输入门 it 的乘积,控制当前输入信息 Ct‘ 的流通。此时的当前输入信息包括了当前时间片输入 xt 和前一个隐层输出值ht-1
得到的新记忆信息,与前一个长期状态 Ct-1 相加,得到当前的长期状态Ct
此时更新的重要信息就是France
(3) 输出门 Ot
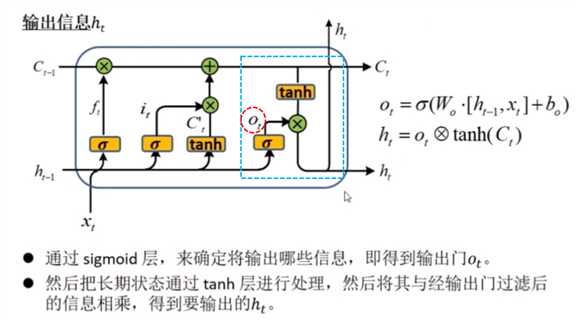
可见,门的共同特征都是利用上一个隐层输出 ht-1 和 当前输入序列 xt 拼接后的矩阵进行 sigmoid激活正规化之后得到的元素在(0,1)之间的矩阵, 对相关信息如Ct-1 ,Ct‘ , Ct进行哈德马乘 积实现选择性过滤。
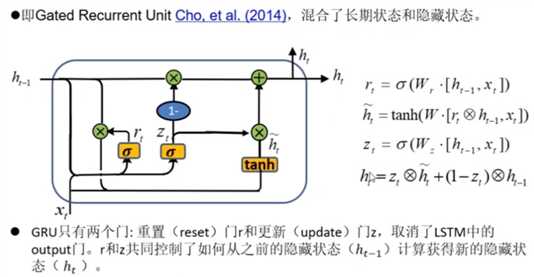
11.LSTM变体-GRU
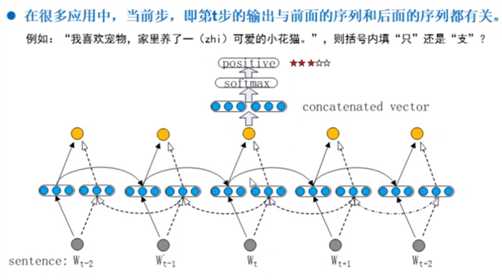
12.双向循环神经网络——Bidirectional RNN
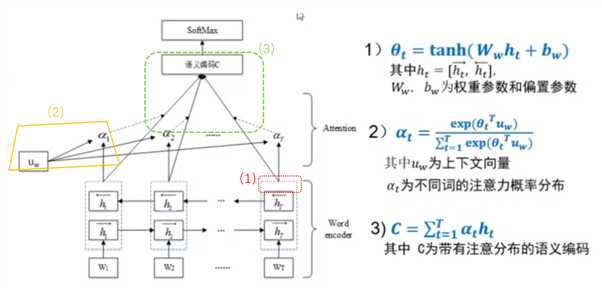
13.基于上下文的注意力模型的基本原理
起初应用在图像分类任务中,指人眼先天能够忽略图片背景,专注于前景。
所谓的attention其实就是根据中间隐层节点的输出值,乘上一个可学习的上下文向量uw,然后归一化后,作为不同词的注意力概率分布(每个词对应的权重)。然后用此概率分布与该词对应的节点向量加权作为整个语句的语义编码C。后续,还会 用一个参数矩阵乘以语义编码C,再进行softmax分类。
加入attention机制后,可以更直观的解释每个词对整体分类类别的重要性。
14.上下文向量 context vec:编码器和解码器之间的中间表示向量,比如输入一句话有n个词,经过RNN编码器编码后,得到的蕴涵语句中单词间前后文关系的表示向量。
循环神经网络-Recurrent neural network
标签:传统 nal 忽略 成长 相关 c中 任务 text 结构
原文地址:https://www.cnblogs.com/Henry-ZHAO/p/12854297.html