标签:shape sdi namespace ids 图片 NPU clu with import
数据分析与建模,本次尝试使用C++进行处理,数据在excel中,遂考虑使用Python进行excel转txt操作,代码如下:
1 # -*- coding: UTF-8 -*- 2 import sys 3 import json 4 5 import pandas as pd 6 import numpy as np 7 8 filename=r‘C:\Users\lenovo\Desktop\that.txt‘ 9 raw_score = r‘C:\Users\lenovo\Desktop\data1.xlsx‘ 10 #读取excel保存成txt格式 11 excel_file = pd.read_excel(raw_score) 12 excel_file.to_csv(filename, sep=‘ ‘, index=False)
Python聚类分析代码:
1 import numpy as np 2 import matplotlib.pyplot as plt 3 4 # 加载数据 5 def loadDataSet(fileName): 6 data = np.loadtxt(fileName,delimiter=‘ ‘) 7 return data 8 9 # 欧氏距离计算 10 def distEclud(x,y): 11 return np.sqrt(np.sum((x-y)**2)) # 计算欧氏距离 12 13 # 为给定数据集构建一个包含K个随机质心的集合 14 def randCent(dataSet,k): 15 m,n = dataSet.shape 16 centroids = np.zeros((k,n)) 17 for i in range(k): 18 index = int(np.random.uniform(0,m)) # 19 centroids[i,:] = dataSet[index,:] 20 return centroids 21 22 # k均值聚类 23 def KMeans(dataSet,k): 24 25 m = np.shape(dataSet)[0] #行的数目 26 # 第一列存样本属于哪一簇 27 # 第二列存样本的到簇的中心点的误差 28 clusterAssment = np.mat(np.zeros((m,2))) 29 clusterChange = True 30 31 # 第1步 初始化centroids 32 centroids = randCent(dataSet,k) 33 while clusterChange: 34 clusterChange = False 35 36 # 遍历所有的样本(行数) 37 for i in range(m): 38 minDist = 100000.0 39 minIndex = -1 40 41 # 遍历所有的质心 42 #第2步 找出最近的质心 43 for j in range(k): 44 # 计算该样本到质心的欧式距离 45 distance = distEclud(centroids[j,:],dataSet[i,:]) 46 if distance < minDist: 47 minDist = distance 48 minIndex = j 49 # 第 3 步:更新每一行样本所属的簇 50 if clusterAssment[i,0] != minIndex: 51 clusterChange = True 52 clusterAssment[i,:] = minIndex,minDist**2 53 #第 4 步:更新质心 54 for j in range(k): 55 pointsInCluster = dataSet[np.nonzero(clusterAssment[:,0].A == j)[0]] # 获取簇类所有的点 56 centroids[j,:] = np.mean(pointsInCluster,axis=0) # 对矩阵的行求均值 57 58 print("Congratulations,cluster complete!") 59 return centroids,clusterAssment 60 61 def showCluster(dataSet,k,centroids,clusterAssment): 62 m,n = dataSet.shape 63 if n != 2: 64 print("数据不是二维的") 65 return 1 66 67 mark = [‘or‘, ‘ob‘, ‘og‘, ‘ok‘, ‘^r‘, ‘+r‘, ‘sr‘, ‘dr‘, ‘<r‘, ‘pr‘] 68 if k > len(mark): 69 print("k值太大了") 70 return 1 71 72 # 绘制所有的样本 73 for i in range(m): 74 markIndex = int(clusterAssment[i,0]) 75 plt.plot(dataSet[i,0],dataSet[i,1],mark[markIndex]) 76 plt.annotate(i+1,(dataSet[i,0],dataSet[i,1])) 77 78 mark = [‘Dr‘, ‘Db‘, ‘Dg‘, ‘Dk‘, ‘^b‘, ‘+b‘, ‘sb‘, ‘db‘, ‘<b‘, ‘pb‘] 79 # 绘制质心 80 for i in range(k): 81 print(‘质心:‘,str(centroids[i,0])+‘ ‘+str(centroids[i,1])) 82 plt.plot(centroids[i,0],centroids[i,1],mark[i]) 83 plt.title(‘Clustering map of specialists‘) 84 plt.show() 85 86 87 dataSet = loadDataSet(r‘C:\Users\lenovo\Desktop\normal.txt‘) 88 k = 3 89 centroids,clusterAssment = KMeans(dataSet,k) 90 91 showCluster(dataSet,k,centroids,clusterAssment)
聚类结果:
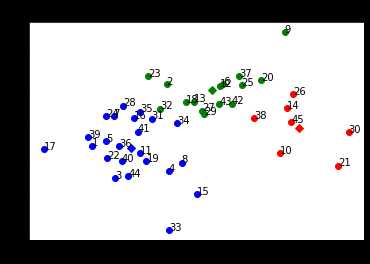
话说,c++建模也还可,就是需要自己编写相关指标的算法,但是也挺有意
代码如下:
1 /* 2 *language:c++ 3 *version:11 4 *encoding:GBK 5 *made by Luo Wenshui 6 *last modified:2020/5/10 7 *data file:input.txt 8 */ 9 #include<iostream> 10 #include<map> 11 #include<math.h> 12 #include<string.h> 13 #include<algorithm> 14 #include<cstdio> 15 using namespace std; 16 inline int read(){ 17 int ans=0,w=1; 18 char ch=getchar(); 19 while(!isdigit(ch)){if(ch==‘-‘)w=-1;ch=getchar();} 20 while(isdigit(ch))ans=(ans<<3)+(ans<<1)+ch-‘0‘,ch=getchar(); 21 return ans*w; 22 } 23 int n,m,t; 24 const int maxn=1200; 25 const int maxm=50; 26 struct node{//每一件参赛作品 27 double final_score; 28 double raw_score[4]; 29 int score_givener[4]; 30 double std_score[4]; 31 int rank;//该作品在所有参赛作品中的排序 32 }a[maxn]; 33 struct specialist{ 34 double raw_score[100]; 35 double std_score[100]; 36 int num_of_work[100];//每次评阅的作品编号 37 int count;//表示专家批阅的项目数量; 38 double std;//该专家打分的标准差 39 double mean;//该专家打分的均值 40 int rank[maxn];//该专家对相应编号作品的打分在该专家所有分数中的排名 41 double delta0i,delta1i; 42 double P0i,P1i;//定义为P0i=1-delta0i,P1i=1-delta1i 43 double P0T,P1T;//专家多次比赛获得的平均可行度水平,本论文中不涉及 44 int kide;//专家在聚类之后所属的类别 45 }E[maxm]; 46 struct work{//对所有作品确定排名的排序类 47 int index; 48 double score; 49 }w[maxn]; 50 double R[maxm][maxm];//相似度矩阵 51 double total_mean;//所有专家打分的均值 52 double total_std;//所有专家打分的标准差 53 int kide[100]={3,2,3,3,3,2,3,3,3,1,3,2,2,1,3,3,3,2,3,2,1,3,2,3,2,1,2,3,2,1,3,2,3,3,3,3,2,1,3,3,3,2,2,3,1};//专家类别表,由聚类分析得出 54 double get_std(specialist& s)//获取每个专家打分的标准差 55 { 56 double mean=0.0; 57 for(int i = 1; i <= s.count; i ++ )//计算均值 58 { 59 mean+=s.raw_score[i]; 60 } 61 mean/=s.count; 62 double ans = 0.0; 63 for(int i = 1; i <= s.count; i ++ ) 64 { 65 ans+=(s.raw_score[i]-mean)*(s.raw_score[i]-mean); 66 } 67 return sqrt(ans/s.count); 68 } 69 double get_mean(specialist& s)//获取s打分的均值 70 { 71 double ans = 0.0; 72 for(int i = 1; i <= s.count; i ++ ) 73 { 74 ans += s.raw_score[i]; 75 } 76 return ans/s.count; 77 } 78 int get_rank(double score,specialist& s)//获取某一得分在专家所有打分中的排名 79 { 80 int rank = 0; 81 for(int i = 0; i <= s.count; i ++ ) 82 { 83 if(s.raw_score[i] < score)rank++; 84 } 85 return rank; 86 } 87 double get_delta0i(specialist& Ei)//获取专家E[i]的delta0i 88 { 89 double ans = 0.0; 90 for(int j = 1; j <= Ei.count; j ++ ) 91 { 92 double final_score = a[Ei.num_of_work[j]].final_score;//专家Ei在评阅的作品j的总评得分 93 ans += fabs(Ei.raw_score[j]-final_score)/final_score; 94 } 95 return ans/(double)Ei.count; 96 } 97 double get_delta1i(specialist& Ei)//获取专家E[i]的delta1i 98 { 99 double ans = 0.0; 100 int count = Ei.count; 101 for(int j = 1; j <= Ei.count; j ++ ) 102 { 103 double rank = a[Ei.num_of_work[j]].rank;//Ei评阅的第j件作品的总评排序 104 ans += fabs((double)Ei.rank[j]-rank)/(double)(count-1); 105 } 106 return ans/count; 107 } 108 void get_R()//计算定义的相似度矩阵 109 { 110 double M = -1e10; 111 for(int i = 1; i <= 45; i ++ ) 112 { 113 for(int j = 1; j <= 45; j ++ ) 114 { 115 double P0i = E[i].P0i; 116 double P0j = E[j].P0i; 117 double P1i = E[i].P1i; 118 double P1j = E[j].P1i; 119 double tmp = P0i*P0j+P1i*P1j; 120 M = max(M,tmp); 121 if(i == j)R[i][j]=1; 122 else 123 { 124 R[i][j]=tmp; 125 } 126 } 127 } 128 for(int i = 1; i <= 45; i ++ ) 129 { 130 for( int j = 1; j <= 45; j ++ ) 131 { 132 if(i==j)continue; 133 R[i][j] = R[i][j]/M;//映射到(0,1)区间 134 } 135 } 136 } 137 double get_total_mean()//获得总体均值 138 { 139 double ans = 0.0; 140 for(int i = 1; i <= 1046; i ++ ) 141 { 142 ans += a[i].final_score; 143 } 144 return ans/1046; 145 } 146 double get_total_std()//获得总体方差 147 { 148 double ans = 0.0; 149 int count = 0; 150 for(int i = 1; i <= 45;i ++ ) 151 { 152 count += E[i].count; 153 for(int j = 1; j <= E[i].count; j ++ ) 154 { 155 int num = E[i].num_of_work[j]; 156 ans += pow(a[num].final_score-E[i].raw_score[j],2); 157 } 158 } 159 return sqrt(ans/count); 160 } 161 void display();//展示专家信息 162 void display_R();//展示相关系数矩阵 163 void display_P();//打印可信度表 164 struct test{ 165 int index; 166 }; 167 168 bool cmp(work& a1,work& a2){return a1.score<a2.score;}//按照得分进行升序排序 169 int main() 170 { 171 freopen("input.txt","r",stdin); 172 // freopen("output.txt","w",stdout); 173 std::ios::sync_with_stdio(false); 174 int number,number_of_work; 175 double tmp; 176 int x; 177 double tmp1,tmp2; 178 for(int i = 1;i <= 1046;i ++)//获取1046条数据 179 { 180 cin>>tmp; 181 number = (int)tmp; 182 cin>>a[number].final_score; 183 w[i].index = i; 184 w[i].score = a[number].final_score; 185 //获取三个专家的信息 186 for(int j = 1; j <= 3; j ++ ) 187 { 188 cin>>tmp; 189 number = (int)tmp; 190 cin>>tmp1>>tmp2; 191 192 int count = ++E[number].count; 193 E[number].raw_score[count]=tmp1; 194 E[number].std_score[count]=tmp2; 195 E[number].num_of_work[count]=i;//评阅的作品编号 196 197 a[i].raw_score[j] = tmp1; 198 a[i].score_givener[j] = number; 199 a[i].std_score[j] = tmp2; 200 } 201 } 202 203 for(int i = 1; i <= 45; i ++ ) 204 { 205 E[i].std = get_std(E[i]); 206 E[i].mean = get_mean(E[i]); 207 for(int j = 1; j <= E[i].count; j ++ )//计算在E[i]所打的分中作品Aj的排名 208 { 209 E[i].rank[j] = get_rank(E[i].raw_score[j],E[i]); 210 } 211 } 212 sort(w+1,w+1046+1,cmp);//对作品final_score进行升序排序 213 for(int i = 1; i <=1046; i ++ ) 214 { 215 a[w[i].index].rank=i;//得到每件作品的排名 216 } 217 218 for(int i = 1; i <= 45; i ++ )//获取每位专家的分值偏差和排序偏差与可信度 219 { 220 E[i].delta0i = get_delta0i(E[i]); 221 E[i].delta1i = get_delta1i(E[i]); 222 E[i].P0i = 1 - E[i].delta0i; 223 E[i].P1i = 1 - E[i].delta1i; 224 } 225 // cout<<get_total_mean()<<" "<<get_total_std()<<endl; 226 // display();//通过display 函数可以展示每一个专家的详细信息 227 // get_R();//计算相关矩阵 228 // display_R(); 229 // 230 // display_P(); 231 } 232 void display() 233 { 234 cout<<"四元组(a,b,c,d) => 该专家第a次批阅了作品b,给了c分,该作品的标准分是d"<<endl; 235 for(int j = 1; j <= 45; j ++ ) 236 { 237 cout<<"第"<<j<<"个专家:"<<endl; 238 cout<<"总体:"<<E[j].count<<endl; 239 for(int i = 1; i <= E[j].count; i ++ ) 240 { 241 cout<<"("<<i<<","<<E[j].num_of_work[i]<<","<<E[j].raw_score[j]<<","<<E[j].std_score[i]<<")"<<endl; 242 cout<<"该作品在该专家所以给分中的排名:"<<E[1].rank[i]<<endl; 243 } 244 cout<<"标准差:"<<E[j].std<<endl; 245 cout<<"delta0i = "<<E[j].delta0i<<endl; 246 cout<<"delta1i = "<<E[j].delta1i<<endl; 247 248 cout<<"P0i = "<<E[j].P0i<<endl; 249 cout<<"P1i = "<<E[j].P1i<<endl; 250 cout<<"#########################################################"<<endl; 251 } 252 } 253 void display_R() 254 { 255 cout<<" "; 256 for(int i = 1;i <= 45; i ++ ) 257 { 258 cout<<"("<<i<<")"<<" "; 259 } 260 cout<<endl; 261 for(int i = 1; i <= 45; i ++ ) 262 { 263 cout<<"("<<i<<")"<<" "; 264 for(int j = 1; j <= 45; j ++ ) 265 { 266 cout<<R[i][j]<<" "; 267 } 268 cout<<endl; 269 } 270 } 271 void display_P() 272 { 273 cout<<"可信度矩阵"<<endl; 274 for(int i = 1; i <= 45; i ++ ) 275 { 276 cout<<E[i].P0i<<" "<<E[i].P1i<<endl; 277 } 278 }
标签:shape sdi namespace ids 图片 NPU clu with import
原文地址:https://www.cnblogs.com/randy-lo/p/12868259.html