标签:处理 chord 保留 ret java实现 rap foreach lambda 就是
Lambda:
我们知道,对于一个Java变量,我们可以赋给其一个“值”。

如果你想把“一块代码”赋给一个Java变量,应该怎么做呢?
比如,我想把右边那块代码,赋给一个叫做aBlockOfCode的Java变量:

在Java 8之前,这个是做不到的。但是Java 8问世之后,利用Lambda特性,就可以做到了。
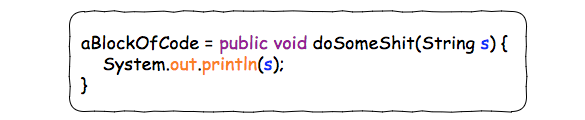
当然,这个并不是一个很简洁的写法。所以,为了使这个赋值操作更加elegant, 我们可以移除一些没用的声明。
这样,我们就成功的非常优雅的把“一块代码”赋给了一个变量。而“这块代码”,或者说“这个被赋给一个变量的函数”,就是一个Lambda表达式。
但是这里仍然有一个问题,就是变量aBlockOfCode的类型应该是什么?
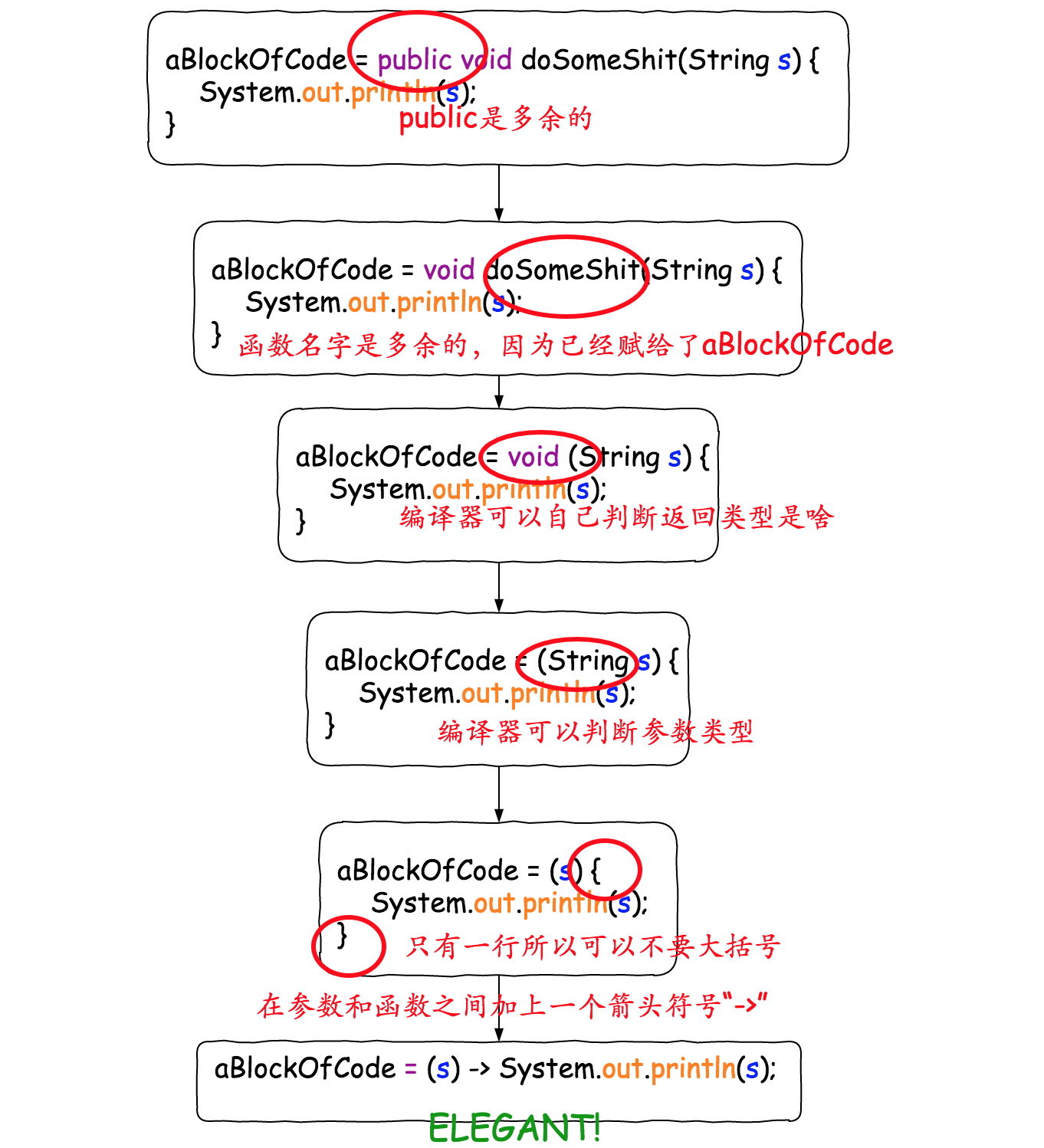
在Java 8里面,所有的Lambda的类型都是一个接口,而Lambda表达式本身,也就是”那段代码“,需要是这个接口的实现。这是我认为理解Lambda的一个关键所在,简而言之就是,Lambda表达式本身就是一个接口的实现。直接这样说可能还是有点让人困扰,我们继续看看例子。我们给上面的aBlockOfCode加上一个类型:

这种只有一个接口函数需要被实现的接口类型,我们叫它”函数式接口“。为了避免后来的人在这个接口中增加接口函数导致其有多个接口函数需要被实现,变成"非函数接口”,我们可以在这个上面加上一个声明@FunctionalInterface, 这样别人就无法在里面添加新的接口函数了:

这样,我们就得到了一个完整的Lambda表达式声明:

最直观的作用就是使得代码变得异常简洁。
我们可以对比一下Lambda表达式和传统的Java对同一个接口的实现:
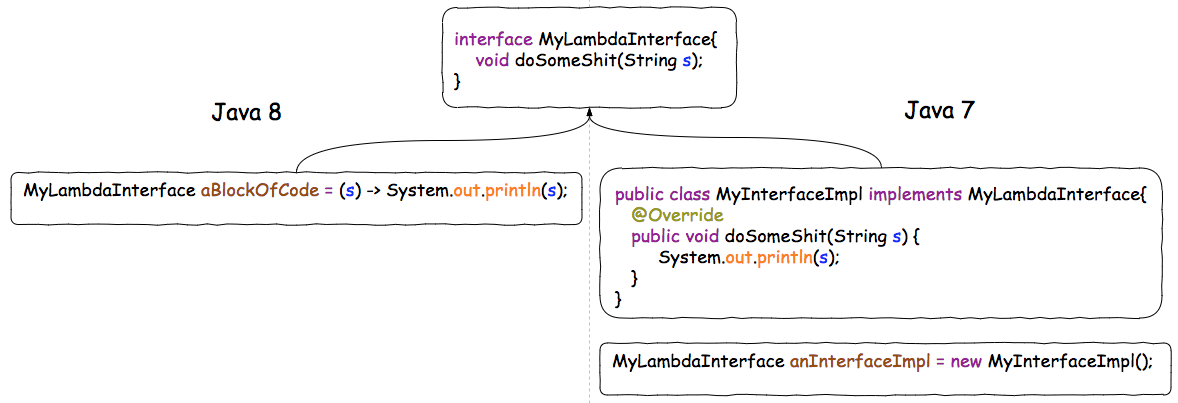
这两种写法本质上是等价的。但是显然,Java 8中的写法更加优雅简洁。并且,由于Lambda可以直接赋值给一个变量,我们就可以直接把Lambda作为参数传给函数, 而传统的Java必须有明确的接口实现的定义,初始化才行:

有些情况下,这个接口实现只需要用到一次。传统的Java 7必须要求你定义一个“污染环境”的接口实现MyInterfaceImpl,而相较之下Java 8的Lambda, 就显得干净很多。
直接上例子。
假设Person的定义和List<Person>的值都给定。
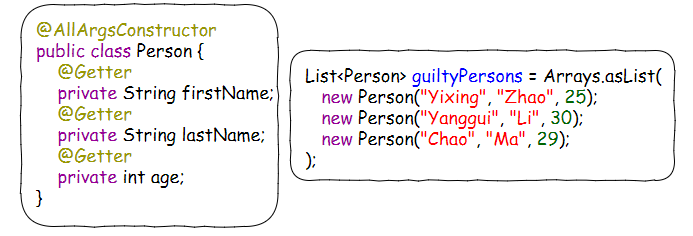
现在需要你打印出guiltyPersons List里面所有LastName以"Z"开头的人的FirstName。
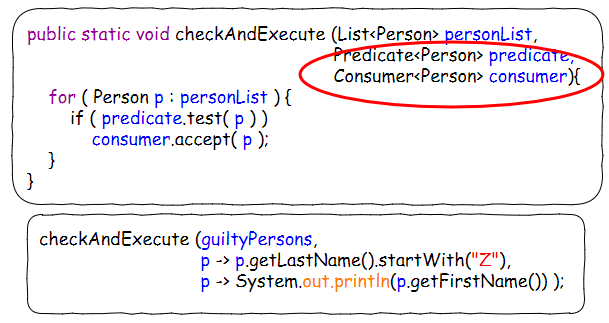
原生态Lambda写法:定义两个函数式接口,定义一个静态函数,调用静态函数并给参数赋值Lambda表达式。

这个代码实际上已经比较简洁了,但是我们还可以更简洁么?
当然可以。在Java 8中有一个函数式接口的包,里面定义了大量可能用到的函数式接口(java.util.function (Java Platform SE 8 ))。所以,我们在这里压根都不需要定义NameChecker和Executor这两个函数式接口,直接用Java 8函数式接口包里的Predicate<T>和Consumer<T>就可以了——因为他们这一对的接口定义和NameChecker/Executor其实是一样的。
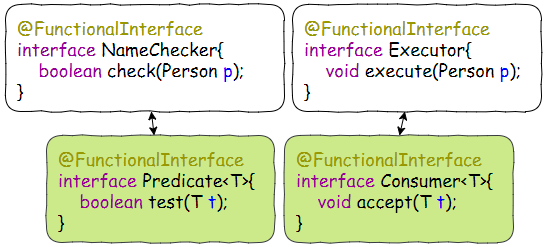
第一步简化 - 利用函数式接口包:
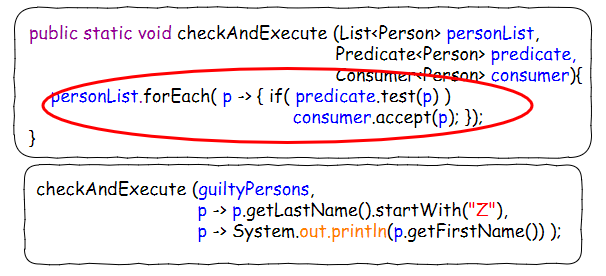
静态函数里面的for each循环其实是非常碍眼的。这里可以利用Iterable自带的forEach()来替代。forEach()本身可以接受一个Consumer<T> 参数。
第二步简化 - 用Iterable.forEach()取代foreach loop:
由于静态函数其实只是对List进行了一通操作,这里我们可以甩掉静态函数,直接使用stream()特性来完成。stream()的几个方法都是接受Predicate<T>,Consumer<T>等参数的(java.util.stream (Java Platform SE 8 ))。你理解了上面的内容,stream()这里就非常好理解了,并不需要多做解释。
第三步简化 - 利用stream()替代静态函数:

对比最开始的Lambda写法,这里已经非常非常简洁了。但是如果,我们的要求变一下,变成print这个人的全部信息,及p -> System.out.println(p); 那么还可以利用Method reference来继续简化。所谓Method reference, 就是用已经写好的别的Object/Class的method来代替Lambda expression。格式如下:

第四步简化 - 如果是println(p),则可以利用Method reference代替forEach中的Lambda表达式:

这基本上就是能写的最简洁的版本了。
这个地方应该实现一个闭包的语义,编译器需要把闭包的对象引用传给内部类。但java实现时没有传引用,而是直接copy了数据。也就是里外两个变量实际上是两个名字和值相同,但各自独立的东西。
如果该数据在内部类的函数里可以修改,就会出现里外不一致,于是会露馅。因此java干脆规定这种变量必须是final的,不能改。
Stream:
Java 8 新特性系列文章索引。
我们都知道 Lambda 和 Stream 是 Java 8 的两大亮点功能,在前面的文章里已经介绍过 Lambda 相关知识,这次介绍下 Java 8 的 Stream 流操作。它完全不同于 java.io 包的 Input/Output Stream ,也不是大数据实时处理的 Stream 流。这个 Stream 流操作是 Java 8 对集合操作功能的增强,专注于对集合的各种高效、便利、优雅的聚合操作。借助于 Lambda 表达式,显著的提高编程效率和可读性。且 Stream 提供了并行计算模式,可以简洁的编写出并行代码,能充分发挥如今计算机的多核处理优势。
在使用 Stream 流操作之前你应该先了解 Lambda 相关知识,如果还不了解,可以参考之前文章:还看不懂同事的代码?Lambda 表达式、函数接口了解一下 。
Stream 不同于其他集合框架,它也不是某种数据结构,也不会保存数据,但是它负责相关计算,使用起来更像一个高级的迭代器。在之前的迭代器中,我们只能先遍历然后在执行业务操作,而现在只需要指定执行什么操作, Stream 就会隐式的遍历然后做出想要的操作。另外 Stream 和迭代器一样的只能单向处理,如同奔腾长江之水一去而不复返。
由于 Stream 流提供了惰性计算和并行处理的能力,在使用并行计算方式时数据会被自动分解成多段然后并行处理,最后将结果汇总。所以 Stream 操作可以让程序运行变得更加高效。
Stream 流的使用总是按照一定的步骤进行,可以抽象出下面的使用流程。
数据源(source) -> 数据处理/转换(intermedia) -> 结果处理(terminal )
数据源(source)也就是数据的来源,可以通过多种方式获得 Stream 数据源,下面列举几种常见的获取方式。
数据处理/转换(intermedia)步骤可以有多个操作,这步也被称为intermedia(中间操作)。在这个步骤中不管怎样操作,它返回的都是一个新的流对象,原始数据不会发生任何改变,而且这个步骤是惰性计算处理的,也就是说只调用方法并不会开始处理,只有在真正的开始收集结果时,中间操作才会生效,而且如果遍历没有完成,想要的结果已经获取到了(比如获取第一个值),会停止遍历,然后返回结果。惰性计算可以显著提高运行效率。
数据处理演示。
@Test
public void streamDemo(){
List<String> nameList = Arrays.asList("Darcy", "Chris", "Linda", "Sid", "Kim", "Jack", "Poul", "Peter");
// 1. 筛选出名字长度为4的
// 2. 名字前面拼接 This is
// 3. 遍历输出
nameList.stream()
.filter(name -> name.length() == 4)
.map(name -> "This is "+name)
.forEach(name -> System.out.println(name));
}
// 输出结果
// This is Jack
// This is Poul
数据处理/转换操作自然不止是上面演示的过滤 filter 和 map映射两种,另外还有 map (mapToInt, flatMap 等)、 filter、 distinct、 sorted、 peek、 limit、 skip、 parallel、 sequential、 unordered 等。
结果处理(terminal )是流处理的最后一步,执行完这一步之后流会被彻底用尽,流也不能继续操作了。也只有到了这个操作的时候,流的数据处理/转换等中间过程才会开始计算,也就是上面所说的惰性计算。结果处理也必定是流操作的最后一步。
常见的结果处理操作有 forEach、 forEachOrdered、 toArray、 reduce、 collect、 min、 max、 count、 anyMatch、 allMatch、 noneMatch、 findFirst、 findAny、 iterator 等。
下面演示了简单的结果处理的例子。
/**
* 转换成为大写然后收集结果,遍历输出
*/
@Test
public void toUpperCaseDemo() {
List<String> nameList = Arrays.asList("Darcy", "Chris", "Linda", "Sid", "Kim", "Jack", "Poul", "Peter");
List<String> upperCaseNameList = nameList.stream()
.map(String::toUpperCase)
.collect(Collectors.toList());
upperCaseNameList.forEach(name -> System.out.println(name + ","));
}
// 输出结果
// DARCY,CHRIS,LINDA,SID,KIM,JACK,POUL,PETER,
有一种 Stream 操作被称作 short-circuiting ,它是指当 Stream 流无限大但是需要返回的 Stream 流是有限的时候,而又希望它能在有限的时间内计算出结果,那么这个操作就被称为short-circuiting。例如 findFirst 操作。
Stream 流在使用时候总是借助于 Lambda 表达式进行操作,Stream 流的操作也有很多种方式,下面列举的是常用的 11 种操作。
获取 Stream 的几种方式在上面的 Stream 数据源里已经介绍过了,下面是针对上面介绍的几种获取 Stream 流的使用示例。
@Test
public void createStream() throws FileNotFoundException {
List<String> nameList = Arrays.asList("Darcy", "Chris", "Linda", "Sid", "Kim", "Jack", "Poul", "Peter");
String[] nameArr = {"Darcy", "Chris", "Linda", "Sid", "Kim", "Jack", "Poul", "Peter"};
// 集合获取 Stream 流
Stream<String> nameListStream = nameList.stream();
// 集合获取并行 Stream 流
Stream<String> nameListStream2 = nameList.parallelStream();
// 数组获取 Stream 流
Stream<String> nameArrStream = Stream.of(nameArr);
// 数组获取 Stream 流
Stream<String> nameArrStream1 = Arrays.stream(nameArr);
// 文件流获取 Stream 流
BufferedReader bufferedReader = new BufferedReader(new FileReader("README.md"));
Stream<String> linesStream = bufferedReader.lines();
// 从静态方法获取流操作
IntStream rangeStream = IntStream.range(1, 10);
rangeStream.limit(10).forEach(num -> System.out.print(num+","));
System.out.println();
IntStream intStream = IntStream.of(1, 2, 3, 3, 4);
intStream.forEach(num -> System.out.print(num+","));
}
forEach 是 Strean 流中的一个重要方法,用于遍历 Stream 流,它支持传入一个标准的 Lambda 表达式。但是它的遍历不能通过 return/break 进行终止。同时它也是一个 terminal 操作,执行之后 Stream 流中的数据会被消费掉。
如输出对象。
List<Integer> numberList = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);
numberList.stream().forEach(number -> System.out.println(number+","));
// 输出结果
// 1,2,3,4,5,6,7,8,9,
使用 map 把对象一对一映射成另一种对象或者形式。
/**
* 把数字值乘以2
*/
@Test
public void mapTest() {
List<Integer> numberList = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);
// 映射成 2倍数字
List<Integer> collect = numberList.stream()
.map(number -> number * 2)
.collect(Collectors.toList());
collect.forEach(number -> System.out.print(number + ","));
System.out.println();
numberList.stream()
.map(number -> "数字 " + number + ",")
.forEach(number -> System.out.println(number));
}
// 输出结果
// 2,4,6,8,10,12,14,16,18,
// 数字 1,数字 2,数字 3,数字 4,数字 5,数字 6,数字 7,数字 8,数字 9,
上面的 map 可以把数据进行一对一的映射,而有些时候关系可能不止 1对 1那么简单,可能会有1对多。这时可以使用 flatMap。下面演示使用 flatMap把对象扁平化展开。
/**
* flatmap把对象扁平化
*/
@Test
public void flatMapTest() {
Stream<List<Integer>> inputStream = Stream.of(
Arrays.asList(1),
Arrays.asList(2, 3),
Arrays.asList(4, 5, 6)
);
List<Integer> collect = inputStream
.flatMap((childList) -> childList.stream())
.collect(Collectors.toList());
collect.forEach(number -> System.out.print(number + ","));
}
// 输出结果
// 1,2,3,4,5,6,
使用 filter 进行数据筛选,挑选出想要的元素,下面的例子演示怎么挑选出偶数数字。
/**
* filter 数据筛选
* 筛选出偶数数字
*/
@Test
public void filterTest() {
List<Integer> numberList = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);
List<Integer> collect = numberList.stream()
.filter(number -> number % 2 == 0)
.collect(Collectors.toList());
collect.forEach(number -> System.out.print(number + ","));
}
得到如下结果。
2,4,6,8,
findFirst 可以查找出 Stream 流中的第一个元素,它返回的是一个 Optional 类型,如果还不知道 Optional 类的用处,可以参考之前文章 Jdk14都要出了,还不能使用 Optional优雅的处理空指针? 。
/**
* 查找第一个数据
* 返回的是一个 Optional 对象
*/
@Test
public void findFirstTest(){
List<Integer> numberList = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);
Optional<Integer> firstNumber = numberList.stream()
.findFirst();
System.out.println(firstNumber.orElse(-1));
}
// 输出结果
// 1
findFirst 方法在查找到需要的数据之后就会返回不再遍历数据了,也因此 findFirst 方法可以对有无限数据的 Stream 流进行操作,也可以说 findFirst 是一个 short-circuiting 操作。
Stream 流可以轻松的转换为其他结构,下面是几种常见的示例。
/**
* Stream 转换为其他数据结构
*/
@Test
public void collectTest() {
List<Integer> numberList = Arrays.asList(1, 1, 2, 2, 3, 3, 4, 4, 5);
// to array
Integer[] toArray = numberList.stream()
.toArray(Integer[]::new);
// to List
List<Integer> integerList = numberList.stream()
.collect(Collectors.toList());
// to set
Set<Integer> integerSet = numberList.stream()
.collect(Collectors.toSet());
System.out.println(integerSet);
// to string
String toString = numberList.stream()
.map(number -> String.valueOf(number))
.collect(Collectors.joining()).toString();
System.out.println(toString);
// to string split by ,
String toStringbJoin = numberList.stream()
.map(number -> String.valueOf(number))
.collect(Collectors.joining(",")).toString();
System.out.println(toStringbJoin);
}
// 输出结果
// [1, 2, 3, 4, 5]
// 112233445
// 1,1,2,2,3,3,4,4,5
获取或者扔掉前 n 个元素
/**
* 获取 / 扔掉前 n 个元素
*/
@Test
public void limitOrSkipTest() {
// 生成自己的随机数流
List<Integer> ageList = Arrays.asList(11, 22, 13, 14, 25, 26);
ageList.stream()
.limit(3)
.forEach(age -> System.out.print(age+","));
System.out.println();
ageList.stream()
.skip(3)
.forEach(age -> System.out.print(age+","));
}
// 输出结果
// 11,22,13,
// 14,25,26,
数学统计功能,求一组数组的最大值、最小值、个数、数据和、平均数等。
/**
* 数学计算测试
*/
@Test
public void mathTest() {
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6);
IntSummaryStatistics stats = list.stream().mapToInt(x -> x).summaryStatistics();
System.out.println("最小值:" + stats.getMin());
System.out.println("最大值:" + stats.getMax());
System.out.println("个数:" + stats.getCount());
System.out.println("和:" + stats.getSum());
System.out.println("平均数:" + stats.getAverage());
}
// 输出结果
// 最小值:1
// 最大值:6
// 个数:6
// 和:21
// 平均数:3.5
分组聚合功能,和数据库的 Group by 的功能一致。
/**
* groupingBy
* 按年龄分组
*/
@Test
public void groupByTest() {
List<Integer> ageList = Arrays.asList(11, 22, 13, 14, 25, 26);
Map<String, List<Integer>> ageGrouyByMap = ageList.stream()
.collect(Collectors.groupingBy(age -> String.valueOf(age / 10)));
ageGrouyByMap.forEach((k, v) -> {
System.out.println("年龄" + k + "0多岁的有:" + v);
});
}
// 输出结果
// 年龄10多岁的有:[11, 13, 14]
// 年龄20多岁的有:[22, 25, 26]
/**
* partitioningBy
* 按某个条件分组
* 给一组年龄,分出成年人和未成年人
*/
public void partitioningByTest() {
List<Integer> ageList = Arrays.asList(11, 22, 13, 14, 25, 26);
Map<Boolean, List<Integer>> ageMap = ageList.stream()
.collect(Collectors.partitioningBy(age -> age > 18));
System.out.println("未成年人:" + ageMap.get(false));
System.out.println("成年人:" + ageMap.get(true));
}
// 输出结果
// 未成年人:[11, 13, 14]
// 成年人:[22, 25, 26]
/**
* 生成自己的 Stream 流
*/
@Test
public void generateTest(){
// 生成自己的随机数流
Random random = new Random();
Stream<Integer> generateRandom = Stream.generate(random::nextInt);
generateRandom.limit(5).forEach(System.out::println);
// 生成自己的 UUID 流
Stream<UUID> generate = Stream.generate(UUID::randomUUID);
generate.limit(5).forEach(System.out::println);
}
// 输出结果
// 793776932
// -2051545609
// -917435897
// 298077102
// -1626306315
// 31277974-841a-4ad0-a809-80ae105228bd
// f14918aa-2f94-4774-afcf-fba08250674c
// d86ccefe-1cd2-4eb4-bb0c-74858f2a7864
// 4905724b-1df5-48f4-9948-fa9c64c7e1c9
// 3af2a07f-0855-455f-a339-6e890e533ab3
上面的例子中 Stream 流是无限的,但是获取到的结果是有限的,使用了 Limit 限制获取的数量,所以这个操作也是 short-circuiting 操作。
正确使用并且正确格式化的 Stream 流操作代码不仅简洁优雅,更让人赏心悦目。下面对比下在使用 Stream 流和不使用 Stream 流时相同操作的编码风格。
/**
* 使用流操作和不使用流操作的编码风格对比
*/
@Test
public void diffTest() {
// 不使用流操作
List<String> names = Arrays.asList("Jack", "Jill", "Nate", "Kara", "Kim", "Jullie", "Paul", "Peter");
// 筛选出长度为4的名字
List<String> subList = new ArrayList<>();
for (String name : names) {
if (name.length() == 4) {
subList.add(name);
}
}
// 把值用逗号分隔
StringBuilder sbNames = new StringBuilder();
for (int i = 0; i < subList.size() - 1; i++) {
sbNames.append(subList.get(i));
sbNames.append(", ");
}
// 去掉最后一个逗号
if (subList.size() > 1) {
sbNames.append(subList.get(subList.size() - 1));
}
System.out.println(sbNames);
}
// 输出结果
// Jack, Jill, Nate, Kara, Paul
如果是使用 Stream 流操作。
// 使用 Stream 流操作
String nameString = names.stream()
.filter(num -> num.length() == 4)
.collect(Collectors.joining(", "));
System.out.println(nameString);
上面有提到,数据处理/转换(intermedia) 操作 map (mapToInt, flatMap 等)、 filter、 distinct、 sorted、 peek、 limit、 skip、 parallel、 sequential、 unordered 等这些操作,在调用方法时并不会立即调用,而是在真正使用的时候才会生效,这样可以让操作延迟到真正需要使用的时刻。
下面会举个例子演示这一点。
/**
* 找出偶数
*/
@Test
public void lazyTest() {
// 生成自己的随机数流
List<Integer> numberLIst = Arrays.asList(1, 2, 3, 4, 5, 6);
// 找出偶数
Stream<Integer> integerStream = numberLIst.stream()
.filter(number -> {
int temp = number % 2;
if (temp == 0 ){
System.out.println(number);
}
return temp == 0;
});
System.out.println("分割线");
List<Integer> collect = integerStream.collect(Collectors.toList());
}
如果没有 惰性计算,那么很明显会先输出偶数,然后输出 分割线。而实际的效果是。
分割线
2
4
6
可见 惰性计算 把计算延迟到了真正需要的时候。
获取 Stream 流时可以使用 parallelStream 方法代替 stream 方法以获取并行处理流,并行处理可以充分的发挥多核优势,而且不增加编码的复杂性。
下面的代码演示了生成一千万个随机数后,把每个随机数乘以2然后求和时,串行计算和并行计算的耗时差异。
/**
* 并行计算
*/
@Test
public void main() {
// 生成自己的随机数流,取一千万个随机数
Random random = new Random();
Stream<Integer> generateRandom = Stream.generate(random::nextInt);
List<Integer> numberList = generateRandom.limit(10000000).collect(Collectors.toList());
// 串行 - 把一千万个随机数,每个随机数 * 2 ,然后求和
long start = System.currentTimeMillis();
int sum = numberList.stream()
.map(number -> number * 2)
.mapToInt(x -> x)
.sum();
long end = System.currentTimeMillis();
System.out.println("串行耗时:"+(end - start)+"ms,和是:"+sum);
// 并行 - 把一千万个随机数,每个随机数 * 2 ,然后求和
start = System.currentTimeMillis();
sum = numberList.parallelStream()
.map(number -> number * 2)
.mapToInt(x -> x)
.sum();
end = System.currentTimeMillis();
System.out.println("并行耗时:"+(end - start)+"ms,和是:"+sum);
}
得到如下输出。
串行耗时:1005ms,和是:481385106
并行耗时:47ms,和是:481385106
效果显而易见,代码简洁优雅。
从上面的使用案例中,可以发现使用 Stream 流操作的代码非常简洁,而且可读性更高。但是如果不正确的排版,那么看起来将会很糟糕,比如下面的同样功能的代码例子,多几层操作呢,是不是有些让人头大?
// 不排版
String string = names.stream().filter(num -> num.length() == 4).map(name -> name.toUpperCase()).collect(Collectors.joining(","));
// 排版
String string = names.stream()
.filter(num -> num.length() == 4)
.map(name -> name.toUpperCase())
.collect(Collectors.joining(","));
如果想要你的 Stream 流对于每次的相同操作的结果都是相同的话,那么你必须保证 Lambda 表达式的纯度,也就是下面亮点。
这两点对于保证函数的幂等非常重要,不然你程序执行结果可能会变得难以预测,就像下面的例子。
@Test
public void simpleTest(){
List<Integer> numbers = Arrays.asList(1, 2, 3);
int[] factor = new int[] { 2 };
Stream<Integer> stream = numbers.stream()
.map(e -> e * factor[0]);
factor[0] = 0;
stream.forEach(System.out::println);
}
// 输出结果
// 0
// 0
// 0
文中代码都已经上传到
<完>
标签:处理 chord 保留 ret java实现 rap foreach lambda 就是
原文地址:https://www.cnblogs.com/ym65536/p/12888405.html