标签:upd 一点 中间 友好 htc agent hunk 拉取 帮助
HTTP 协议是运行在 TCP/IP 基础上的,依靠 TCP/IP 协议来实现数据的可靠传输。所以浏览器要用 HTTP 协议收发数据,首先要做的就是建立 TCP 连接。
经过 SYN、SYN/ACK、ACK 的三个包之后,浏览器与服务器的 TCP 连接就建立起来了。
浏览器按照 HTTP 协议规定的格式,通过 TCP 发送了一个“GET / HTTP/1.1”请求报文
Web 服务器回复了第五个包,在 TCP 协议层面确认:“刚才的报文我已经收到了”
Web 服务器收到报文后在内部就要处理这个请求。同样也是依据 HTTP 协议的规定,解析报文,看看浏览器发送这个请求想要干什么。
完成请求后返回 “HTTP/1.1 200 OK”
浏览器也要给服务器回复一个 TCP 的 ACK 确认,“你的响应报文收到了,多谢。”
浏览器就收到了响应数据,然后解析报文
为这个过程画了一个交互图,你可以对照着看一下。不过要提醒你,图里 TCP 关闭连接的“四次挥手”在抓包里没有出现,这是因为 HTTP/1.1 长连接特性,默认不会立即关闭连接。
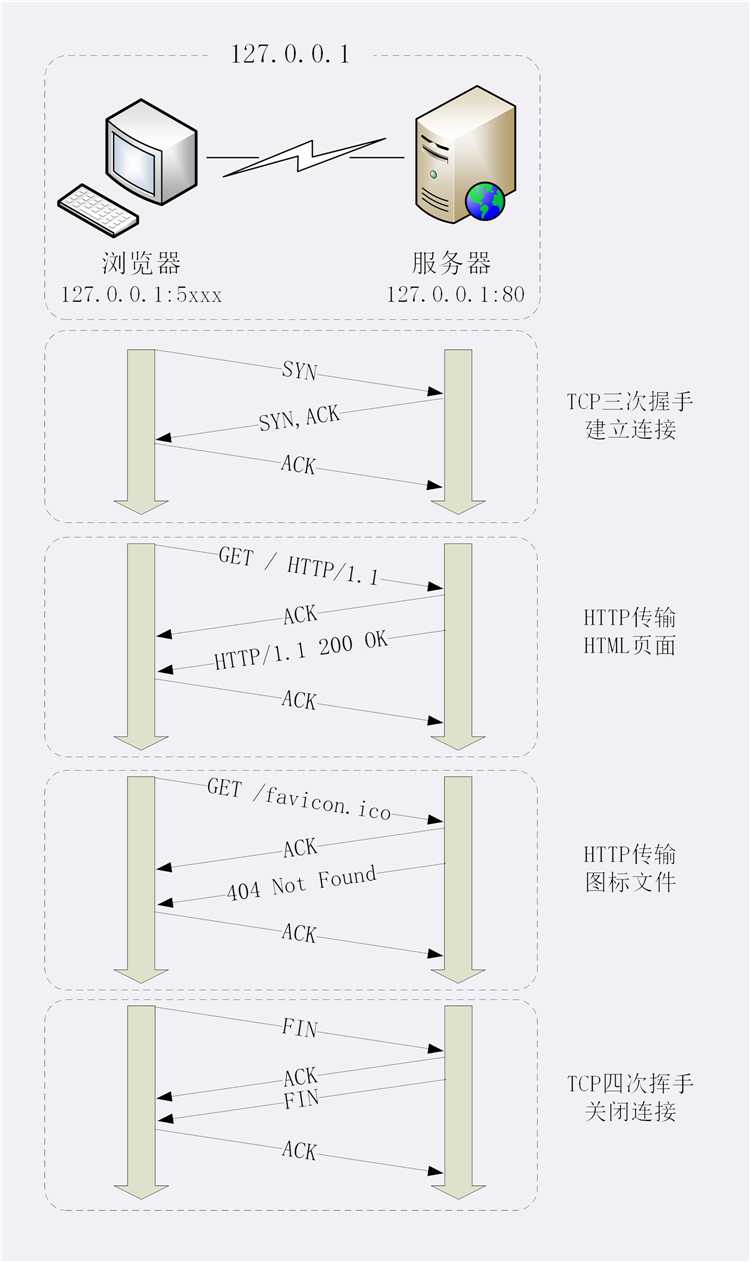
再简要叙述一下这次最简单的浏览器 HTTP 请求过程:
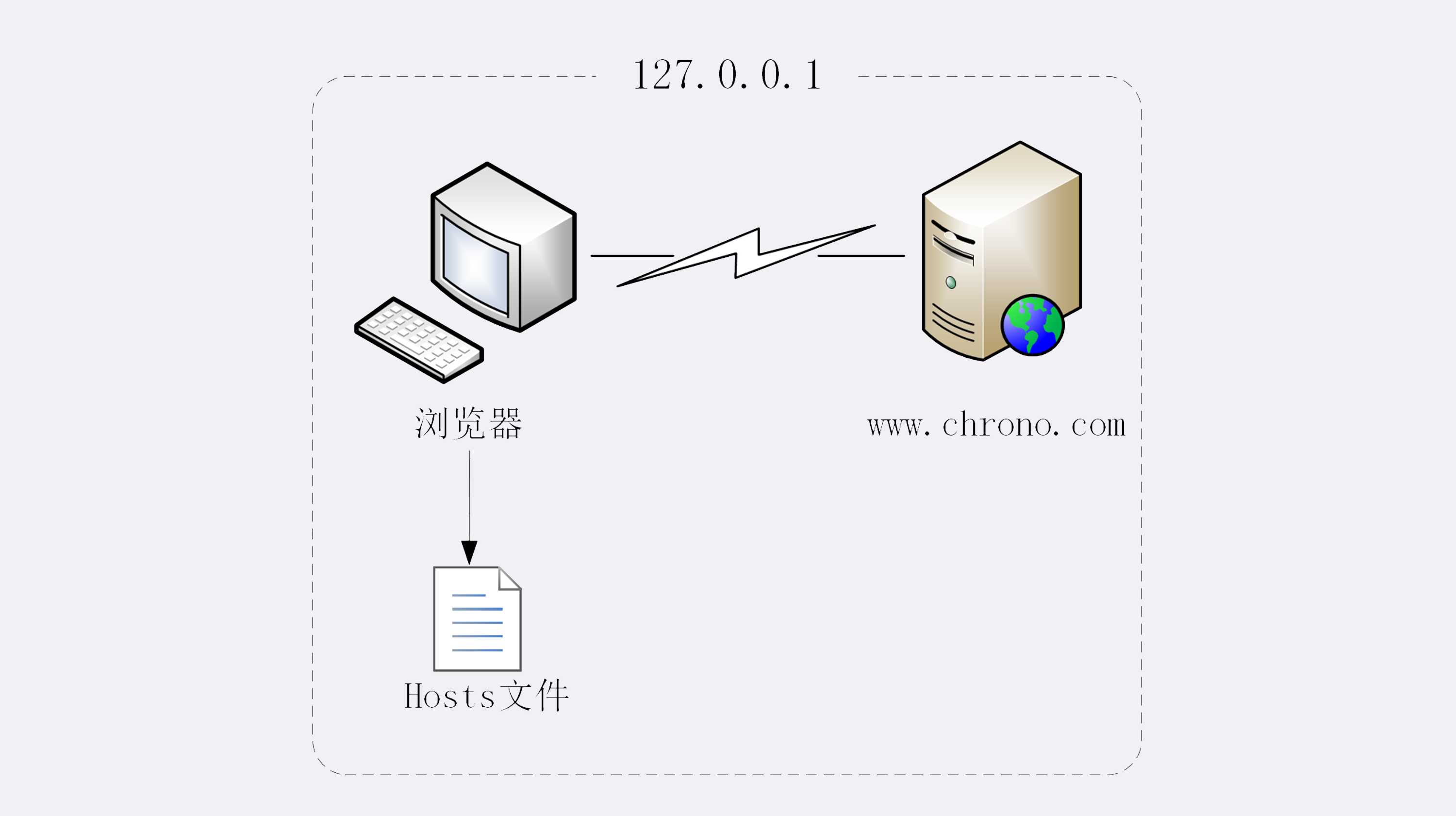
浏览器看到了网址不是数字形式的 IP 地址,那就肯定是域名了,于是就会发起域名解析动作,通过访问一系列的域名解析服务器,试图把这个域名翻译成 TCP/IP 协议里的 IP 地址。
把这个过程也画出了一张图,但省略了 TCP/IP 协议的交互部分,里面的浏览器多出了一个访问 hosts 文件的动作,也就是本机的 DNS 解析。
真实的互联网世界要比上面两个场景要复杂的多,利用下面的这张图来做一个详细的说明。
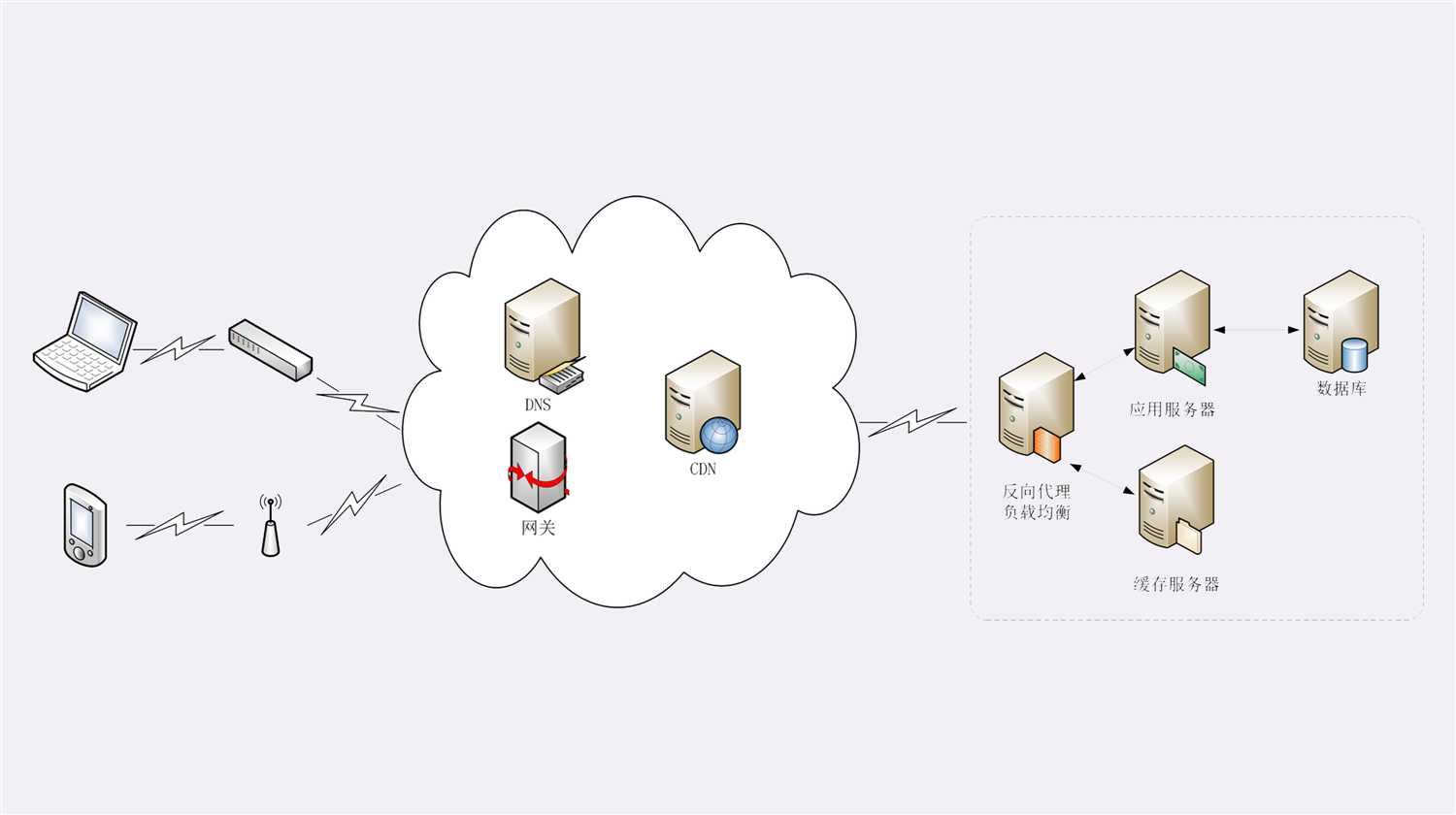
如果你用的是电脑台式机,那么你可能会使用带水晶头的双绞线连上网口,由交换机接入固定网络。如果你用的是手机、平板电脑,那么你可能会通过蜂窝网络、WiFi,由电信基站、无线热点接入移动网络。
接入网络的同时,网络运行商会给你的设备分配一个 IP 地址,这个地址可能是静态分配的,也可能是动态分配的。静态 IP 就始终不变,而动态 IP 可能你下次上网就变了。
假设你要访问的是 Apple 网站,显然你是不知道它的真实 IP 地址的,在浏览器里只能使用域名“www.apple.com”访问,那么接下来要做的必然是域名解析。这就要用 DNS 协议开始从操作系统、本地 DNS、根 DNS、顶级 DNS、权威 DNS 的层层解析,当然这中间有缓存,可能不会费太多时间就能拿到结果。
别忘了互联网上还有另外一个重要的角色 CDN,它也会在 DNS 的解析过程中“插上一脚”。DNS 解析可能会给出 CDN 服务器的 IP 地址,这样你拿到的就会是 CDN 服务器而不是目标网站的实际地址。
因为 CDN 会缓存网站的大部分资源,比如图片、CSS 样式表,所以有的 HTTP 请求就不需要再发到 Apple,CDN 就可以直接响应你的请求,把数据发给你。
由 PHP、Java 等后台服务动态生成的页面属于“动态资源”,CDN 无法缓存,只能从目标网站获取。于是你发出的 HTTP 请求就要开始在互联网上的“漫长跋涉”,经过无数的路由器、网关、代理,最后到达目的地。
目标网站的服务器对外表现的是一个 IP 地址,但为了能够扛住高并发,在内部也是一套复杂的架构。通常在入口是负载均衡设备,例如四层的 LVS 或者七层的 Nginx,在后面是许多的服务器,构成一个更强更稳定的集群。
负载均衡设备会先访问系统里的缓存服务器,通常有 memory 级缓存 Redis 和 disk 级缓存 Varnish,它们的作用与 CDN 类似,不过是工作在内部网络里,把最频繁访问的数据缓存几秒钟或几分钟,减轻后端应用服务器的压力。
如果缓存服务器里也没有,那么负载均衡设备就要把请求转发给应用服务器了。这里就是各种开发框架大显神通的地方了,例如 Java 的 Tomcat/Netty/Jetty,Python 的 Django,还有 PHP、Node.js、Golang 等等。它们又会再访问后面的 MySQL、PostgreSQL、MongoDB 等数据库服务,实现用户登录、商品查询、购物下单、扣款支付等业务操作,然后把执行的结果返回给负载均衡设备,同时也可能给缓存服务器里也放一份。
应用服务器的输出到了负载均衡设备这里,请求的处理就算是完成了,就要按照原路再走回去,还是要经过许多的路由器、网关、代理。如果这个资源允许缓存,那么经过 CDN 的时候它也会做缓存,这样下次同样的请求就不会到达源站了。
最后网站的响应数据回到了你的设备,它可能是 HTML、JSON、图片或者其他格式的数据,需要由浏览器解析处理才能显示出来,如果数据里面还有超链接,指向别的资源,那么就又要重走一遍整个流程,直到所有的资源都下载完。
HTTP 协议的请求报文和响应报文的结构基本相同,由三大部分组成:
这其中前两部分起始行和头部字段经常又合称为“请求头”或“响应头”,消息正文又称为“实体”,但与“header”对应,很多时候就直接称为“body”。
HTTP 协议规定报文必须有 header,但可以没有 body,而且在 header 之后必须要有一个“空行”,也就是“CRLF”,十六进制的“0D0A”。
所以,一个完整的 HTTP 报文就像是下图的这个样子,注意在 header 和 body 之间有一个“空行”。
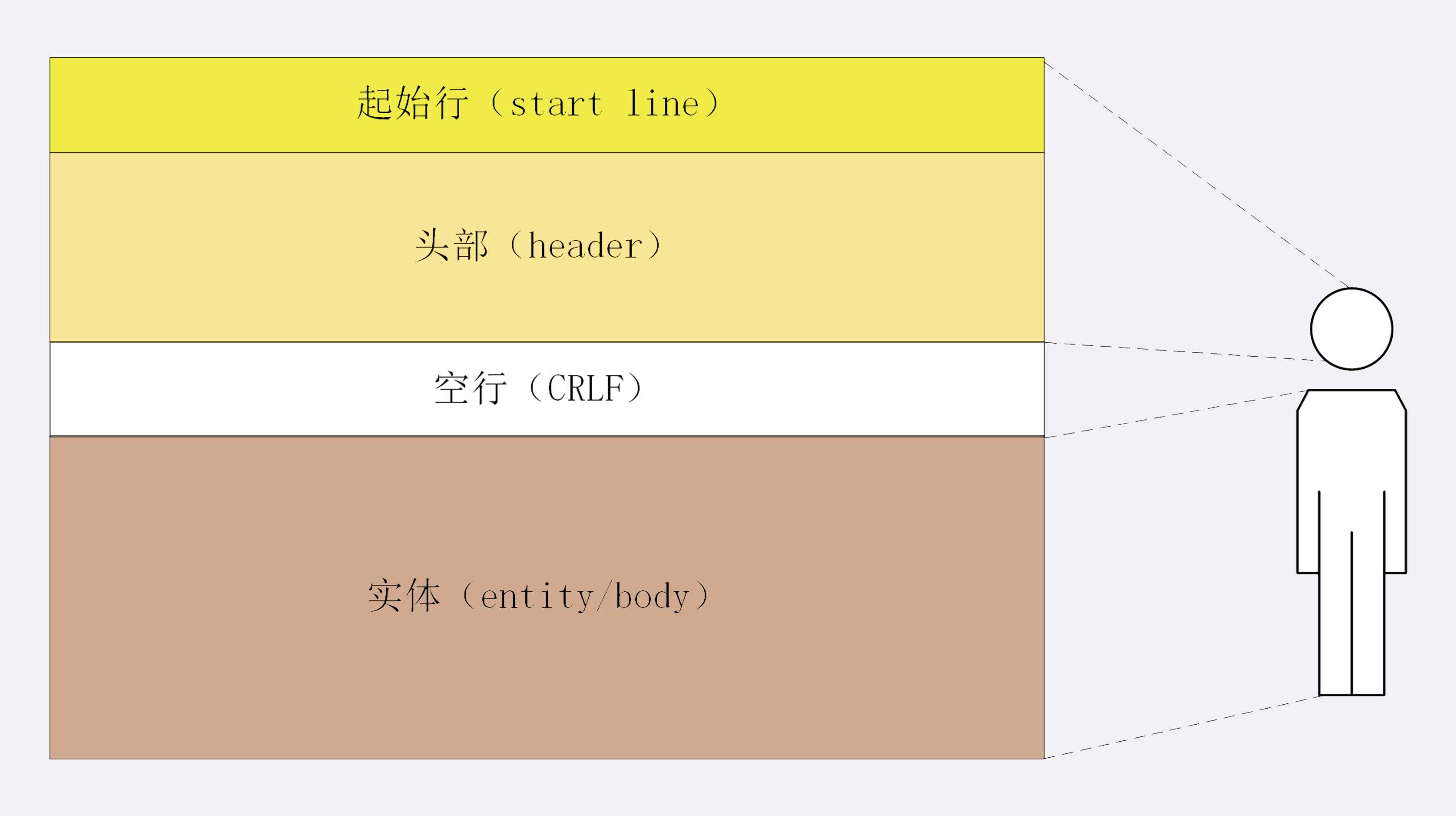
HTTP 的报文结构像不像里面的“大头儿子”?
报文里的 header 就是“大头儿子”的“大头”,空行就是他的“脖子”,而后面的 body 部分就是他的身体了。
看一下我们用 Wireshark 抓的包
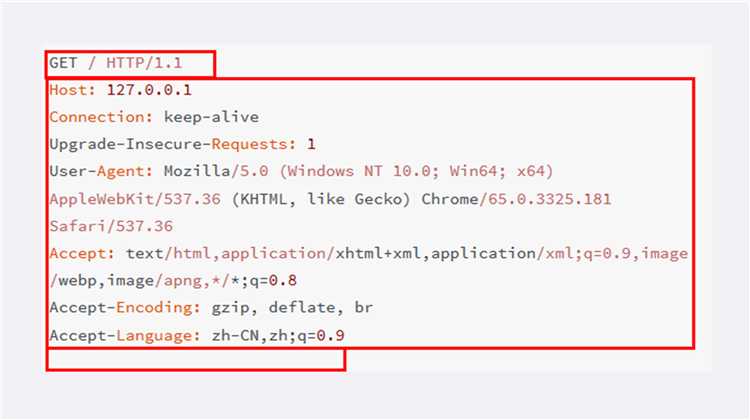
在这个浏览器发出的请求报文里,第一行“GET / HTTP/1.1”就是请求行,而后面的“Host”“Connection”等等都属于 header,报文的最后是一个空白行结束,没有 body。
在很多时候,特别是浏览器发送 GET 请求的时候都是这样,HTTP 报文经常是只有 header 而没 body,相当于只发了一个超级“大头”过来,你可以想象的出来:每时每刻网络上都会有数不清的“大头儿子”在跑来跑去。
不过这个“大头”也不能太大,虽然 HTTP 协议对 header 的大小没有做限制,但各个 Web 服务器都不允许过大的请求头,因为头部太大可能会占用大量的服务器资源,影响运行效率。
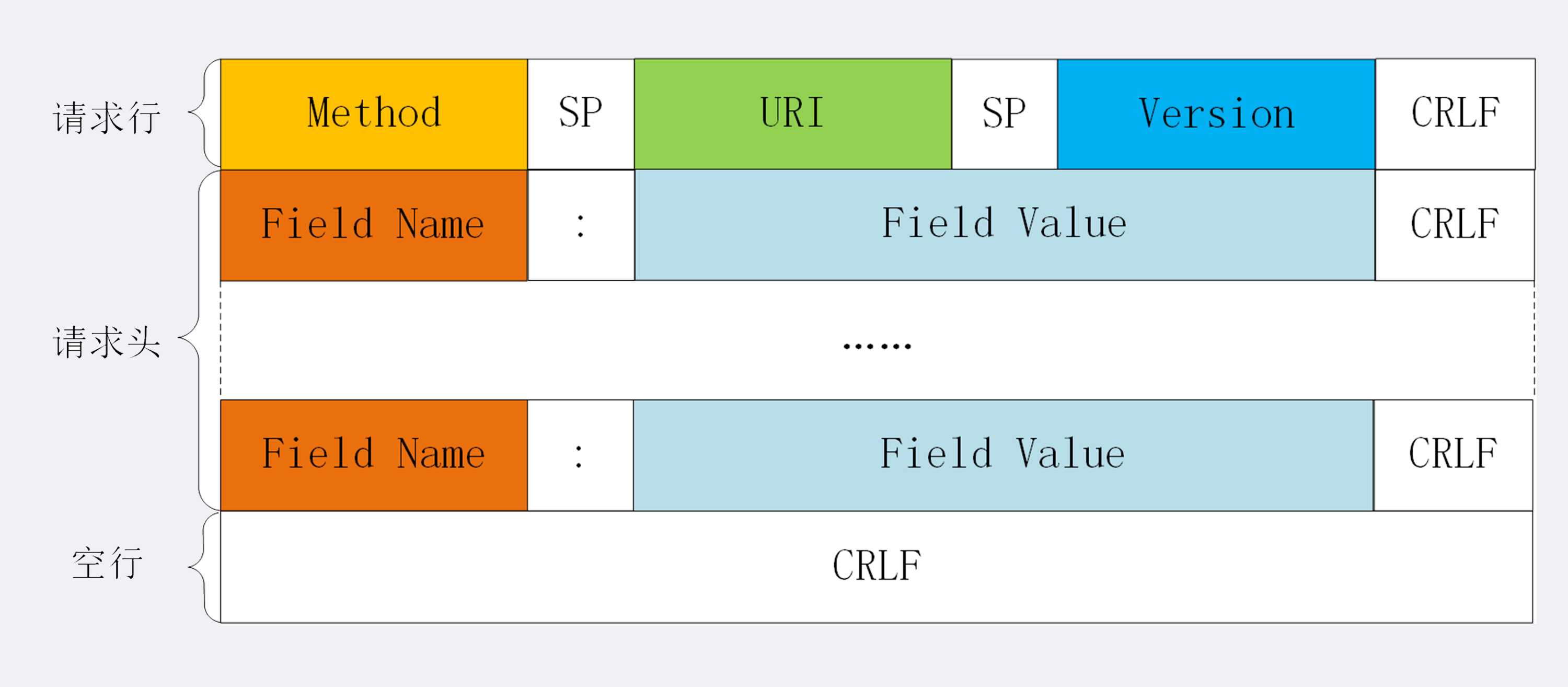
了解了 HTTP 报文的基本结构后,我们来看看请求报文里的起始行也就是请求行(request line),它简要地描述了客户端想要如何操作服务器端的资源。
请求行由三部分构成:
这三个部分通常使用空格(space)来分隔,最后要用 CRLF 换行表示结束。

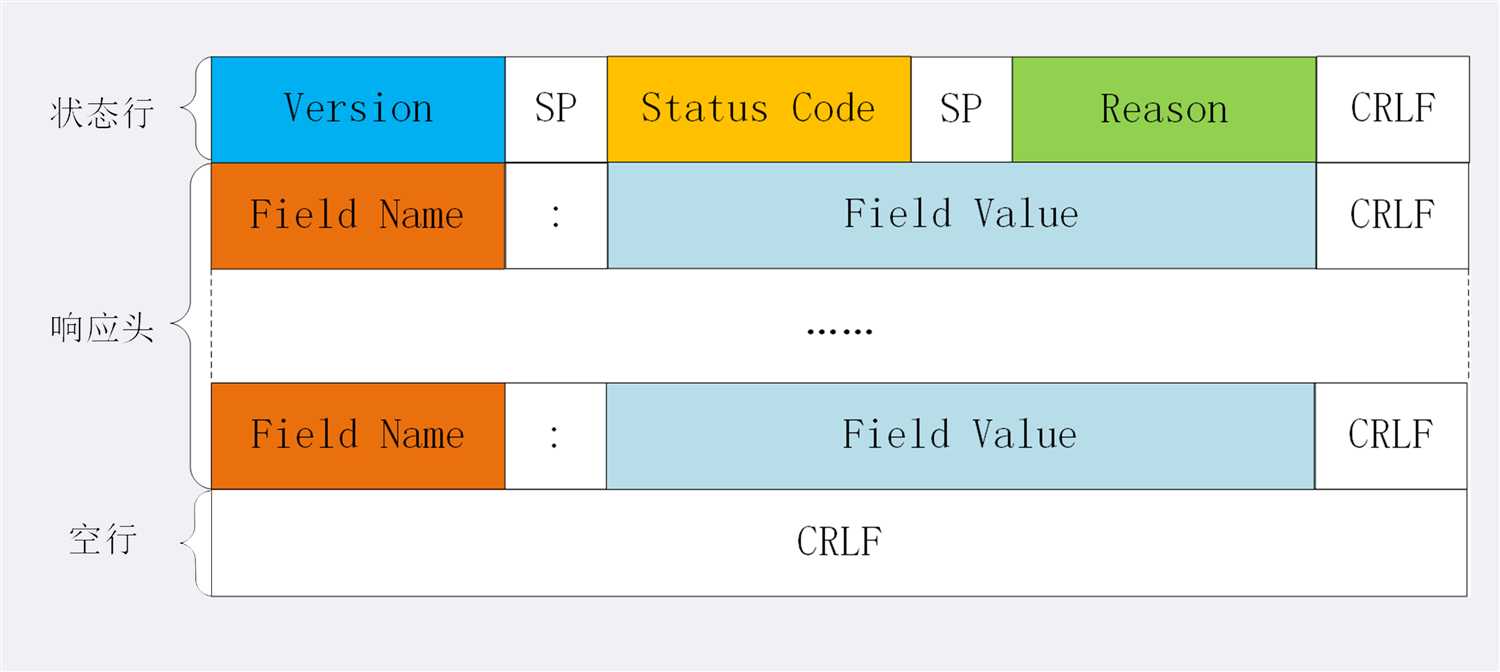
看完了请求行,我们再看响应报文里的起始行,在这里它不叫“响应行”,而是叫“状态行”(status line),意思是服务器响应的状态。
比起请求行来说,状态行要简单一些,同样也是由三部分构成:

请求行或状态行再加上头部字段集合就构成了 HTTP 报文里完整的请求头或响应头,画了两个示意图,你可以看一下。
请求头和响应头的结构是基本一样的,唯一的区别是起始行,所以我把请求头和响应头里的字段放在一起介绍。
头部字段是 key-value 的形式,key 和 value 之间用“:”分隔,最后用 CRLF 换行表示字段结束。比如在“Host: 127.0.0.1”这一行里 key 就是“Host”,value 就是“127.0.0.1”。
HTTP 头字段非常灵活,不仅可以使用标准里的 Host、Connection 等已有头,也可以任意添加自定义头,这就给 HTTP 协议带来了无限的扩展可能。
不过使用头字段需要注意下面几点:
HTTP 协议规定了非常多的头部字段,实现各种各样的功能,但基本上可以分为四大类:
对 HTTP 报文的解析和处理实际上主要就是对头字段的处理,理解了头字段也就理解了 HTTP 报文。
首先要说的是Host字段,它属于请求字段,只能出现在请求头里,它同时也是唯一一个 HTTP/1.1 规范里要求必须出现的字段,也就是说,如果请求头里没有 Host,那这就是一个错误的报文。
Host 字段告诉服务器这个请求应该由哪个主机来处理,当一台计算机上托管了多个虚拟主机的时候,服务器端就需要用 Host 字段来选择,有点像是一个简单的“路由重定向”。
例如我们的试验环境,在 127.0.0.1 上有三个虚拟主机:“www.chrono.com” “www.metroid.net” 和 “origin.io”。那么当使用域名的方式访问时,就必须要用 Host 字段来区分这三个 IP 相同但域名不同的网站,否则服务器就会找不到合适的虚拟主机,无法处理。
User-Agent是请求字段,只出现在请求头里。它使用一个字符串来描述发起 HTTP 请求的客户端,服务器可以依据它来返回最合适此浏览器显示的页面。
但由于历史的原因,User-Agent 非常混乱,每个浏览器都自称是“Mozilla” “Chrome” “Safari”,企图使用这个字段来互相“伪装”,导致 User-Agent 变得越来越长,最终变得毫无意义。
不过有的比较“诚实”的爬虫会在 User-Agent 里用“spider”标明自己是爬虫,所以可以利用这个字段实现简单的反爬虫策略。
Date字段是一个通用字段,但通常出现在响应头里,表示 HTTP 报文创建的时间,客户端可以使用这个时间再搭配其他字段决定缓存策略。
Server字段是响应字段,只能出现在响应头里。它告诉客户端当前正在提供 Web 服务的软件名称和版本号,例如在我们的实验环境里它就是“Server: openresty/1.15.8.1”,即使用的是 OpenResty 1.15.8.1。
Server 字段也不是必须要出现的,因为这会把服务器的一部分信息暴露给外界,如果这个版本恰好存在 bug,那么黑客就有可能利用 bug 攻陷服务器。所以,有的网站响应头里要么没有这个字段,要么就给出一个完全无关的描述信息。
比如 GitHub,它的 Server 字段里就看不出是使用了 Apache 还是 Nginx,只是显示为“GitHub.com”。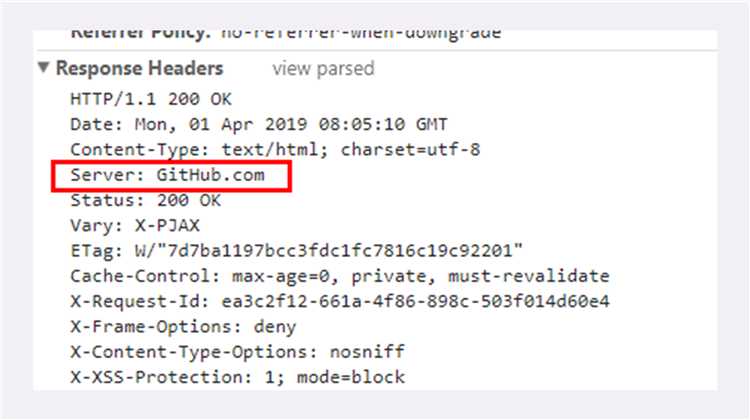
实体字段里要说的一个是Content-Length,它表示报文里 body 的长度,也就是请求头或响应头空行后面数据的长度。服务器看到这个字段,就知道了后续有多少数据,可以直接接收。如果没有这个字段,那么 body 就是不定长的,需要使用 chunked 方式分段传输。
HTTP 协议里为什么要有“请求方法”这个东西呢?
这就要从 HTTP 协议设计时的定位说起了。蒂姆·伯纳斯 - 李最初设想的是要用 HTTP 协议构建一个超链接文档系统,使用 URI 来定位这些文档,也就是资源。那么,该怎么在协议里操作这些资源呢?
很显然,需要有某种“动作的指示”,告诉操作这些资源的方式。所以,就这么出现了“请求方法”。它的实际含义就是客户端发出了一个“动作指令”,要求服务器端对 URI 定位的资源执行这个动作。
目前 HTTP/1.1 规定了八种方法,单词都必须是大写的形式,我先简单地列把它们列出来,后面再详细讲解。
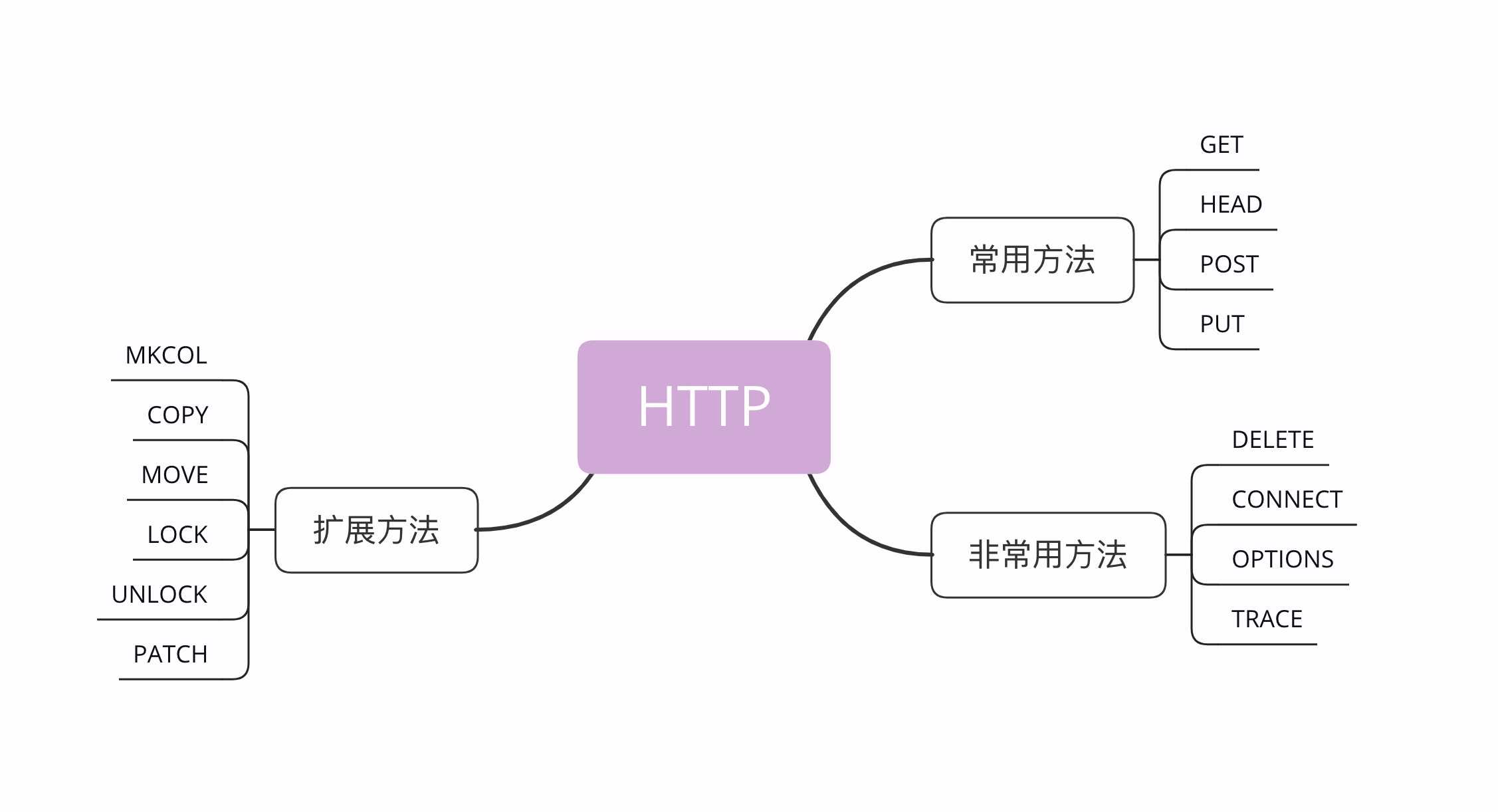
看看这些方法,是不是有点像对文件或数据库的“增删改查”操作,只不过这些动作操作的目标不是本地资源,而是远程服务器上的资源,所以只能由客户端“请求”或者“指示”服务器来完成。
既然请求方法是一个“指示”,那么客户端自然就没有决定权,服务器掌控着所有资源,也就有绝对的决策权力。它收到 HTTP 请求报文后,看到里面的请求方法,可以执行也可以拒绝,或者改变动作的含义,毕竟 HTTP 是一个“协议”,两边都要“商量着来”。
比如,你发起了一个 GET 请求,想获取“/orders”这个文件,但这个文件保密级别比较高,不是谁都能看的,服务器就可以有如下的几种响应方式:
虽然 HTTP/1.1 里规定了八种请求方法,但只有前四个是比较常用的,所以我们先来看一下这四个方法。
GET方法应该是 HTTP 协议里最知名的请求方法了,也应该是用的最多的,自 0.9 版出现并一直被保留至今,是名副其实的“元老”。
它的含义是请求从服务器获取资源,这个资源既可以是静态的文本、页面、图片、视频,也可以是由 PHP、Java 动态生成的页面或者其他格式的数据。
GET 方法虽然基本动作比较简单,但搭配 URI 和其他头字段就能实现对资源更精细的操作。
例如,在 URI 后使用“#”,就可以在获取页面后直接定位到某个标签所在的位置;
使用 If-Modified-Since 字段就变成了“有条件的请求”,仅当资源被修改时才会执行获取动作;
使用 Range 字段就是“范围请求”,只获取资源的一部分数据。
HEAD方法与 GET 方法类似,也是请求从服务器获取资源,服务器的处理机制也是一样的,但服务器不会返回请求的实体数据,只会传回响应头,也就是资源的“元信息”。
HEAD 方法可以看做是 GET 方法的一个“简化版”或者“轻量版”。因为它的响应头与 GET 完全相同,所以可以用在很多并不真正需要资源的场合,避免传输 body 数据的浪费。
比如,想要检查一个文件是否存在,只要发个 HEAD 请求就可以了,没有必要用 GET 把整个文件都取下来。再比如,要检查文件是否有最新版本,同样也应该用 HEAD,服务器会在响应头里把文件的修改时间传回来。
接下来要说的是POST和PUT方法,这两个方法也很像。
GET 和 HEAD 方法是从服务器获取数据,而 POST 和 PUT 方法则是相反操作,向 URI 指定的资源提交数据,数据就放在报文的 body 里。
POST 也是一个经常用到的请求方法,使用频率应该是仅次于 GET,应用的场景也非常多,只要向服务器发送数据,用的大多数都是 POST。
比如,你上论坛灌水,敲了一堆字后点击“发帖”按钮,浏览器就执行了一次 POST 请求,把你的文字放进报文的 body 里,然后拼好 POST 请求头,通过 TCP 协议发给服务器。
又比如,你上购物网站,看到了一件心仪的商品,点击“加入购物车”,这时也会有 POST 请求,浏览器会把商品 ID 发给服务器,服务器再把 ID 写入你的购物车相关的数据库记录。
PUT 的作用与 POST 类似,也可以向服务器提交数据,但与 POST 存在微妙的不同,通常 POST 表示的是“新建” “create”的含义,而 PUT 则是“修改” “update”的含义。
在实际应用中,PUT 用到的比较少。而且,因为它与 POST 的语义、功能太过近似,有的服务器甚至就直接禁止使用 PUT 方法,只用 POST 方法上传数据。
讲完了 GET/HEAD/POST/PUT,还剩下四个标准请求方法,它们属于比较“冷僻”的方法,应用的不是很多。
DELETE方法指示服务器删除资源,因为这个动作危险性太大,所以通常服务器不会执行真正的删除操作,而是对资源做一个删除标记。当然,更多的时候服务器就直接不处理 DELETE 请求。
CONNECT是一个比较特殊的方法,要求服务器为客户端和另一台远程服务器建立一条特殊的连接隧道,这时 Web 服务器在中间充当了代理的角色。
OPTIONS方法要求服务器列出可对资源实行的操作方法,在响应头的 Allow 字段里返回。它的功能很有限,用处也不大,有的服务器(例如 Nginx)干脆就没有实现对它的支持。
TRACE方法多用于对 HTTP 链路的测试或诊断,可以显示出请求 - 响应的传输路径。它的本意是好的,但存在漏洞,会泄漏网站的信息,所以 Web 服务器通常也是禁止使用。
虽然 HTTP/1.1 里规定了八种请求方法,但它并没有限制我们只能用这八种方法,这也体现了 HTTP 协议良好的扩展性,我们可以任意添加请求动作,只要请求方和响应方都能理解就行。
例如著名的愚人节玩笑 RFC2324,它定义了协议 HTCPCP,即“超文本咖啡壶控制协议”,为 HTTP 协议增加了用来煮咖啡的 BREW 方法,要求添牛奶的 WHEN 方法。
此外,还有一些得到了实际应用的请求方法(WebDAV),例如 MKCOL、COPY、MOVE、LOCK、UNLOCK、PATCH 等。如果有合适的场景,你也可以把它们应用到自己的系统里,比如用 LOCK 方法锁定资源暂时不允许修改,或者使用 PATCH 方法给资源打个小补丁,部分更新数据。但因为这些方法是非标准的,所以需要为客户端和服务器编写额外的代码才能添加支持。
当然了,你也完全可以根据实际需求,自己发明新的方法,比如“PULL”拉取某些资源到本地,“PURGE”清理某个目录下的所有缓存数据。
关于请求方法还有两个面试时有可能会问到、比较重要的概念:安全与幂等。
在 HTTP 协议里,所谓的“安全”是指请求方法不会“破坏”服务器上的资源,即不会对服务器上的资源造成实质的修改。
按照这个定义,只有 GET 和 HEAD 方法是“安全”的,因为它们是“只读”操作,只要服务器不故意曲解请求方法的处理方式,无论 GET 和 HEAD 操作多少次,服务器上的数据都是“安全的”。
而 POST/PUT/DELETE 操作会修改服务器上的资源,增加或删除数据,所以是“不安全”的。
所谓的“幂等”实际上是一个数学用语,被借用到了 HTTP 协议里,意思是多次执行相同的操作,结果也都是相同的,即多次“幂”后结果“相等”。
很显然,GET 和 HEAD 既是安全的也是幂等的,DELETE 可以多次删除同一个资源,效果都是“资源不存在”,所以也是幂等的。
POST 和 PUT 的幂等性质就略费解一点。
按照 RFC 里的语义,POST 是“新增或提交数据”,多次提交数据会创建多个资源,所以不是幂等的;而 PUT 是“替换或更新数据”,多次更新一个资源,资源还是会第一次更新的状态,所以是幂等的。
对你的建议是,你可以对比一下 SQL 来加深理解:把 POST 理解成 INSERT,把 PUT 理解成 UPDATE,这样就很清楚了。多次 INSERT 会添加多条记录,而多次 UPDATE 只操作一条记录,而且效果相同。
标签:upd 一点 中间 友好 htc agent hunk 拉取 帮助
原文地址:https://www.cnblogs.com/wwj99/p/12896714.html