标签:udp 提高 好的 creat rop 支持 实例 new 就是
Producer异步发送演示在上文中介绍了AdminClient API的使用,现在我们已经知道如何在应用中通过API去管理Kafka了。但在大多应用开发中,我们最常面临的场景就是发送消息到Kafka,或者从Kafka中消费消息,也就是典型的生产/消费模式。而本文将要演示的就是如何使用Producer API将消息发送至Kafka中,使应用成为一个生产者。
Producer API具有以下几种发送模式:
接下来,使用一个简单的例子演示一下异步向Kafka发送消息。首先,我们需要创建一个Producer实例,并且必须配置三个参数,分别是Kafka服务的ip地址及端口号,以及消息key和value的序列化器(消息体以key-value结构形式存在)。
在本例中,消息的key和value均为String类型,所以使用StringSerializer这个字符串类型的序列化器。代码示例:
/**
* 创建Producer实例
*/
public static Producer<String, String> createProducer() {
Properties properties = new Properties();
// 指定Kafka服务的ip地址及端口号
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "127.0.0.1:9092");
// 指定消息key的序列化器
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
// 指定消息value的序列化器
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
return new KafkaProducer<>(properties);
}在new KafkaProducer时,构造器里做了什么:
Properties里的配置项,初始化ProducerConfigProducerConfig初始化一些配置字段MetricConfig监控度量指标配置以及MetricsReporter报告器列表和Metrics存储库partitioner负载均衡器,当有多个partition时就是通过这个负载均衡器去将消息均匀的分发到不同的partition中RecordAccumulator,一个类似于计数器的东西,用于计算消息批次的。因为Producer并不是接收到一条消息就发送到一条消息,而是达到一定批量后按批次发送的,所以需要有一个计数器来存储和计算批次。Sender,然后会为其创建一个守护线程,并启动Tips:
KafkaProducer构造器的源码,就会发现其所有的属性都是final的,并且均在构造器中完成了初始化,不存在不安全的发布或共享变量,这也就变相说明了KafkaProducer是线程安全的然后调用Producer中的send方法即可实现异步发送。代码示例:
/**
* 演示Producer异步发送
*/
public static void producerAsyncSend() {
String topicName = "MyTopic";
String key = "test-key";
String value = "this is test message!";
try (Producer<String, String> producer = createProducer()) {
// 构建消息对象
ProducerRecord<String, String> record =
new ProducerRecord<>(topicName, key, value);
// 发送一条消息
producer.send(record);
}
}在producer.send(record)里主要做了以下事情:
accumulator.append向批次中追加消息sender.wakeup在守护线程中去发送消息大致时序图如下: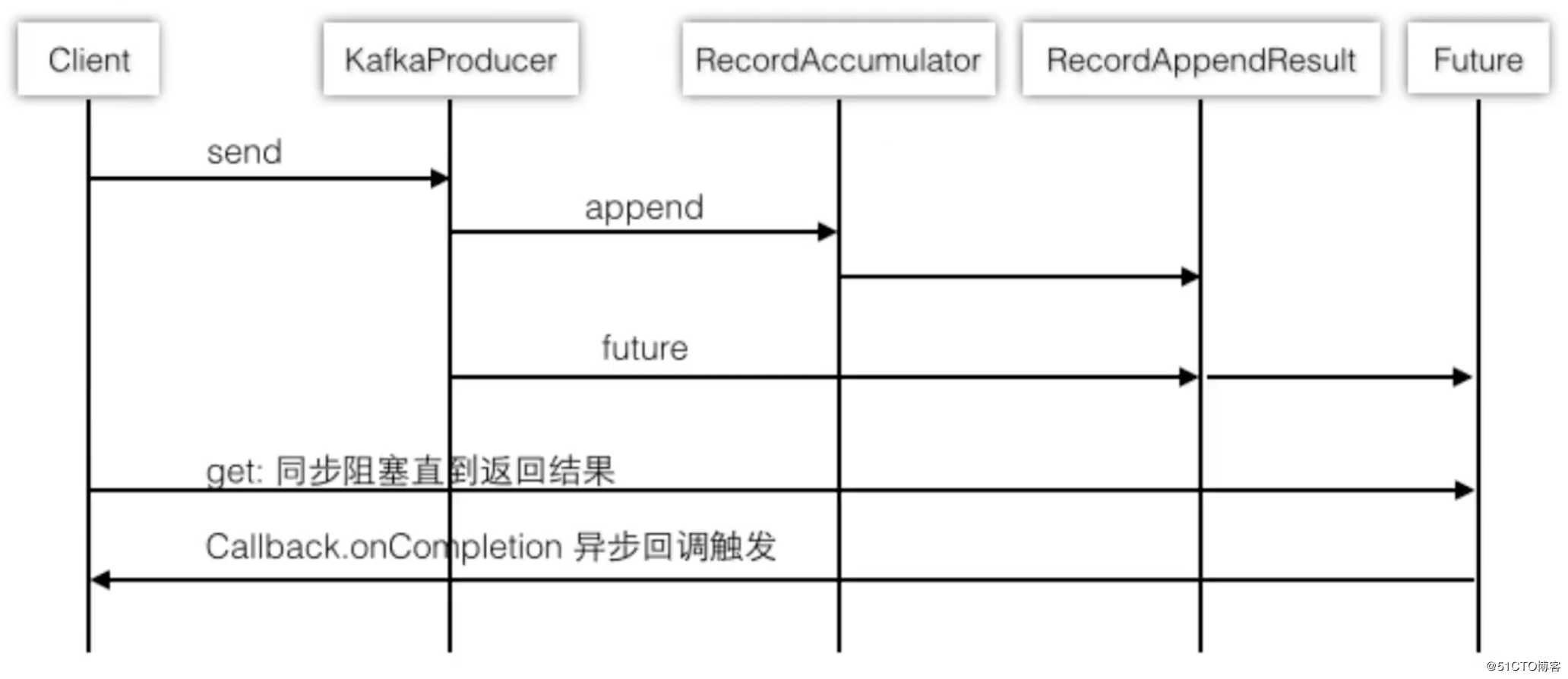
发送消息的具体流程图如下: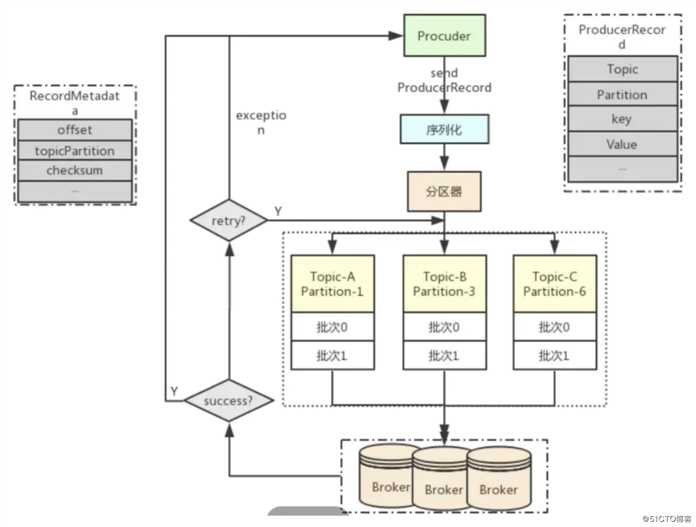
send方法会有一个Future类型的返回值,当我们调用Future的get方法时,就会阻塞当前线程,此时就达到了异步阻塞发送消息的效果,即发送消息是异步的,获取结果是阻塞的。我们可以通过这种方式去获取Future里存储的元数据信息。代码示例:
/**
* 演示Producer异步阻塞式发送
*/
public static void producerAsyncBlockSend() throws Exception {
String topicName = "MyTopic";
String key = "test-key";
String value = "this is test message!";
try (Producer<String, String> producer = createProducer()) {
// 构建消息对象
ProducerRecord<String, String> record =
new ProducerRecord<>(topicName, key, value);
// 发送一条消息
Future<RecordMetadata> future = producer.send(record);
// 调用get时会阻塞当前线程,就能实现异步阻塞式地发送
// 其实发送完就马上get已经同等于同步的效果了
RecordMetadata metadata = future.get();
System.out.println(String.format(
"hasTimestamp: %s, timestamp: %s, hasOffset: %s, offset: %s, partition: %s, topic: %s",
metadata.hasTimestamp(), metadata.timestamp(),
metadata.hasOffset(), metadata.offset(),
metadata.partition(), metadata.topic()
));
}
}运行以上代码,控制台输出内容如下:
hasTimestamp: true, timestamp: 1589637627231, hasOffset: true, offset: 5, partition: 1, topic: MyTopic如果想要在发送完消息后获取结果,比起直接调用Future的get方法更好的方式是使用异步回调的消息发送形式。
在send方法中支持传入一个回调函数,当消息发送完毕后,会调用回调函数并将结果当作参数传入,此时我们就可以在回调函数中对结果进行处理。代码示例:
/**
* 演示Producer异步回调发送
*/
public static void producerAsyncCallbackSend() throws Exception {
String topicName = "MyTopic";
String key = "test-key";
String value = "this is test message!";
try (Producer<String, String> producer = createProducer()) {
// 构建消息对象
ProducerRecord<String, String> record =
new ProducerRecord<>(topicName, key, value);
// 发送一条消息,传入一个回调函数,当消息发送完成后会调用传入的回调函数
producer.send(record, (metadata, err) -> {
if (err != null) {
err.printStackTrace();
}
System.out.println(String.format(
"hasTimestamp: %s, timestamp: %s, hasOffset: %s, offset: %s, partition: %s, topic: %s",
metadata.hasTimestamp(), metadata.timestamp(),
metadata.hasOffset(), metadata.offset(),
metadata.partition(), metadata.topic()
));
});
}
}运行以上代码,控制台输出内容如下:
hasTimestamp: true, timestamp: 1589639553024, hasOffset: true, offset: 7, partition: 1, topic: MyTopic在某些特殊的业务场景下我们经常会有自定义负载均衡算法的需求,在Kafka中可以通过实现Partitioner接口来自定义Partition负载均衡器。
本例中所实现的负载均衡算法比较简单,就是使用key的hashcode去对partition的数量进行取余得出partition的索引,代码示例:
package com.zj.study.kafka.producer;
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import java.util.Map;
/**
* 自定义Partition负载均衡器
*
* @author 01
* @date 2020-05-17
**/
public class MyPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key,
byte[] keyBytes, Object value,
byte[] valueBytes, Cluster cluster) {
int partitionsNum = cluster.partitionsForTopic(topic).size();
return key.hashCode() % partitionsNum;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}然后在创建Producer实例时,指定MyPartitioner的包名路径即可。代码示例:
/**
* 创建Producer实例
*/
public static Producer<String, String> createProducer() {
Properties properties = new Properties();
...
// 指定自定义的Partition负载均衡器
properties.setProperty(ProducerConfig.PARTITIONER_CLASS_CONFIG
, "com.zj.study.kafka.producer.MyPartitioner");
return new KafkaProducer<>(properties);
}我们首先要了解一下消息的传递语义,一般存在三种类型语义:
在Kafka中主要通过消息重发和ACK机制来保障消息的传递,消息重发机制主要是提高消息发送的成功率,并不能保证消息一定能发送成功。我们可以通过在创建Producer实例时,设置retries配置项来开启或关闭消息重发机制,代码示例:
// 设置的值为0表示关闭,大于0则表示开启
properties.setProperty(ProducerConfig.RETRIES_CONFIG, "0");另一个消息传递保障机制就是ACK机制,Kafka中的ACK机制有三种模式,需要通过配置去指定。这三种配置的含义如下:
同样的该配置项可以在创建Producer实例时进行设置,代码示例:
properties.setProperty(ProducerConfig.ACKS_CONFIG, "all");上面的三种取值可以根据实际的业务场景来进行设置,消息的可靠性越强的,性能肯定就会越差。这三种取值就是在消息的可靠性以及性能两个方面做一个权衡:
acks=0acks=1acks=all标签:udp 提高 好的 creat rop 支持 实例 new 就是
原文地址:https://blog.51cto.com/zero01/2495999