标签:where data- nal 数据库 记录 优先级 序列 alt 额外信息
使用explain关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的,分析你的查询语句或是表结构的性能瓶颈。
可用于分析:
执行计划包含的信息如下:

各字段解释
select查询的序列号,包含一组数字,表示查询中执行select子句或操作表的顺序。
分为三种情况:
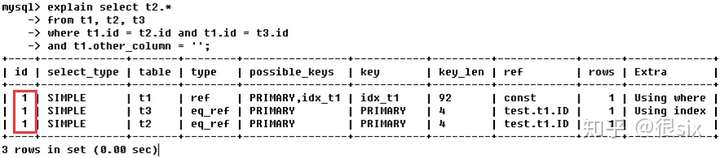
id相同,执行顺序从上到下,搭配table列进行观察可知,执行顺序为t1->t3->t2。
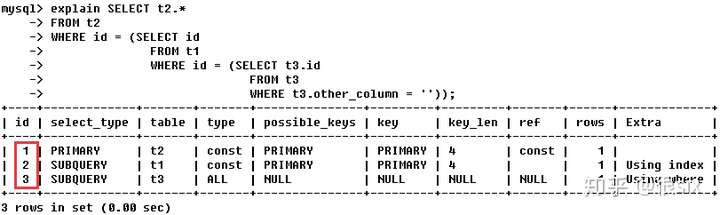
如果是子查询id的序号会递增,id值越大执行优先级越高,搭配table列可知,执行顺序为t3->t1->t2。
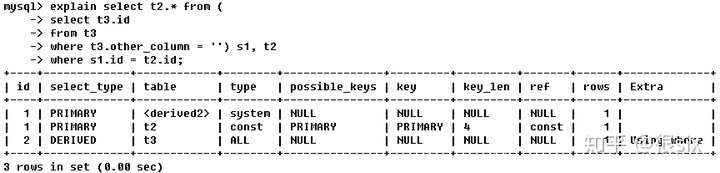
id如果相同,可认为是同一组,执行顺序从上到下。在所有组中,id值越大执行优先级越高。所以执行顺序为t3->derived2(衍生表,也可以说临时表)->t2。
总结:id的值表示select子句或表的执行顺序,id相同,执行顺序从上到下,id不同,值越大的执行优先级越高。
访问类型,显示查询使用了何种类型,从最好到最差依次是:system > const > eq_ref > ref > range > index > ALL。一般来说,要保证查询至少达到range级别,最好能达到ref。


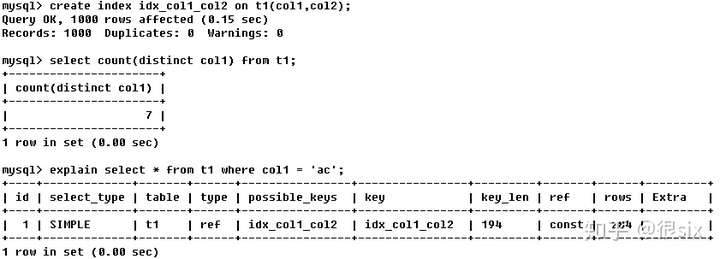
eq_ref和ref:就好比一个班级里面,只有一个班主任和一群学生,t2返回的只有一个记录(就就好比班主任),而col1返回的是所有col1等于ac(所有名字是ac的学生)



简而简之:possible_keys是MySQL分析出推测可能用到的索引有哪几个,而key最后实际用到的索引。(理论:聚会中大概能来多少人和实际来多少人的区别)
覆盖索引演示:
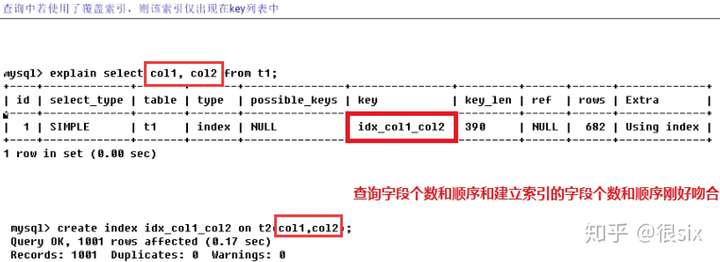
举例:理论上t1这张表应该用到PRIMARY,idx_t1这两个索引,但是实际中却只用到了idx_t1这一个月索引。
举例:假设班级的表中在名字列加上一个索引,我们要根据名字去查询名字姓李的,此时我们还想去根据城市去查询,此时的查询条件比单查名字时更精确。此时得到的结果更精确,但是却投入了更多的条件(第一次名字,第二个城市),此时的key_len会比上一次更多。
下图所示:

显示索引的哪一列被使用了,如果可能的话,最好是一个常数。哪些列或常量被用于查找索引列上的值

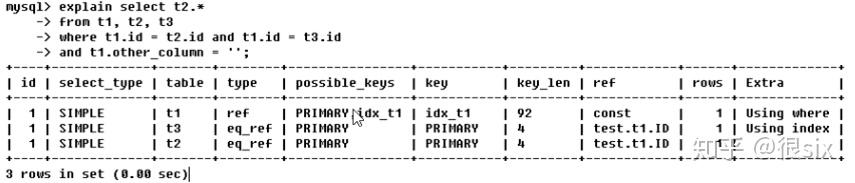
MySQL处理这条语句顺序加载(t2)后加载t1,t1中ref为shared.t2.col1和const,前面代表shared库中t2表的col1字段在和t2表中的col1做关联,const代表t1表中的col2匹配了ac这个常量。
根据表统计信息及索引选用情况,大致估算出找到所需记录所需要读取的行数(被张表有多行被优化器优化过)

没有索引的时候,两张表关联后的加载顺序t2>t1,type就是上面介绍eq_ref和ref区别是介绍的班主任(唯一扫描,只有一行匹配),t2.col1=‘ac‘就好比这个班级是ac,两个表加起来读取了641行。
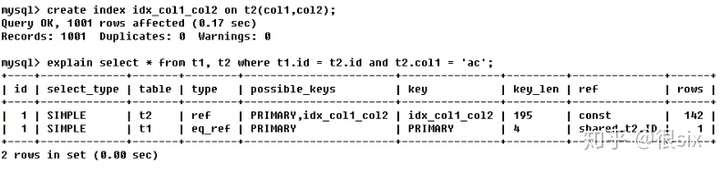
建立复合索引之后(idx_col1_col2),所需要读取的行数为143。
包含不适合在其他列中显示但十分重要的额外信息
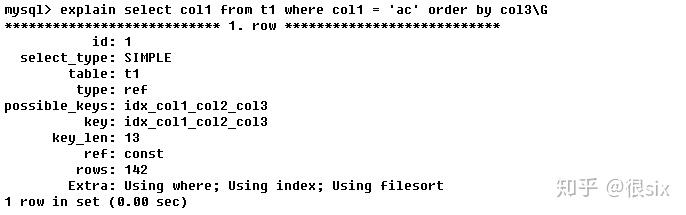
Extra中包含Using where和Using index,确实看到了where条件和使用了索引(idx_col1_col2_col3),还出现了Using filesort,也就说索引只是部分使用到了。我们知道索引干两件事(排序、快速查询),查询的时候部分使用到了(key不为null并且有值,而且type是ref,ref为const),但是排序没有用到。
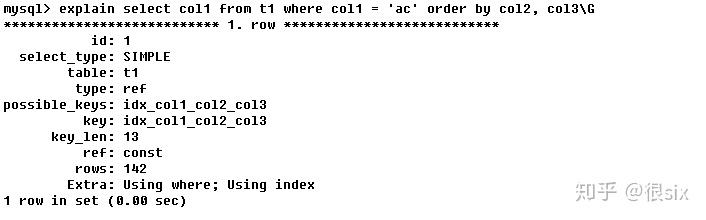
前一章索引有点说过(查询中排序的字段,排序的字段若通过索引去访问将大大提高排序速度),MySQL自我分析之后的结果和前者的区别:从两条SQL中可以看出修改后后者SQL性能高于前者,后者你怎么修的路(索引),那么我就按照你修好的路走(索引),但是前者也同样查出来了,但是修的路,并没有都走,而是自己在内部产生了一次排序,同比性能,前者在内部自己折腾了一次进行了排序结果得到的结果并没有后者好。(建立索引之后,尽可能访问的时候也是按照索引的顺序)
tip:临时表的创建是很伤系统性能的,因为搬数据搬到临时表,用完之后再把临时表回收,数据库内部要自己折腾,这时候查询数据几百万几千万条数据,空间要申请的多,搬数据也多,最后还需要释放,严重增加数据库负担。
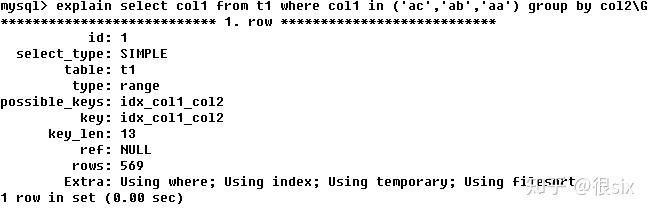

分析两者SQL,使用复合索引(idx_col1_col2,只要key不为null就是用到索引不要怀疑),这种SQL就慢的无比,如果数据是百万千万级别系统会被拖慢。避免临时表的创建。
1. 如果同时出现Using where,表明索引被用来执行索引键值的查找;

创建的索引中包含col1和col2,并且查询的列就包含col2,部分列跟索引重合匹配。
2. 如果没有出现同时出现Using where,表明索引用来读取数据而非执行查找动作

同上,只是SQL中并没有根据条件去查找
覆盖索引(Covering Index),一说为索引覆盖
理解方式一:就是select的数据列只用从索引中就能够获取,不比读取数据行,MySQL可以利用索引返回select列表中的字段,而不必根据索引再次读取数据文件,换句话说查询列要被所见的索引覆盖。(也就是说建的索引是col1,col2,col3的复合索引,刚好查询的也是这几列或者部分满足)
理解方式二:索引是高效找到行的一个方法,但是一般数据库也能使用索引找到一个列的行,因此他不比读取整个行,毕竟索引叶子节点存储了他们所引用的数据,当能通过读取索引就可以得到想要的数据,那就不需要读取行了,一个索引包含了(或覆盖了)满足查询结果的数据就叫做覆盖索引。
注意:如果使用覆盖索引,一定要注意select列表中只去除需要的列,不可select *;因为如果将所有的字段一起做索引会导致索引文件过大,查询性能下降。
热身Case
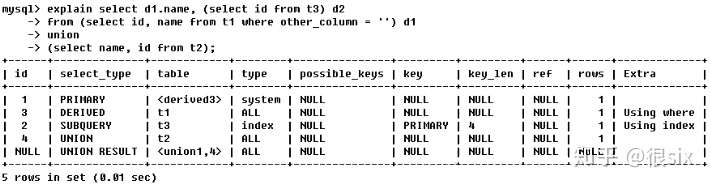
第一行(执行顺序4):id列为1,表示union里的第一个select,select_type列的primary表示查询为外层查询,table列被标记为<devied3>,表示查询结果来自一个衍生表,其中derived3中3代表该查询衍生自第三个select查询,即id为3的select。【select d1,name...】
第二行(执行顺序2):id为3,是整个查询中第三个select的一部分,因查询包含在from中,所以为derived。【select id,name from t1 where other_column=‘‘】
第三行(执行顺序3):select列表中的子查询select_type为subquery,为整个查询中的第二个select。【select id from t3】
第四行(执行顺序1):select_type为union,说明第四个select是union里的第二个select,直接执行【select name,id from t2】
第五行(执行顺序5):代表从union的临时表中读取行的阶段,table列的<union1,4>表示用第一行和第四行的select结果进行union操作。【两个结果union操作】
转自:
https://zhuanlan.zhihu.com/p/56529089
标签:where data- nal 数据库 记录 优先级 序列 alt 额外信息
原文地址:https://www.cnblogs.com/zjfjava/p/12873033.html