标签:imshow 大量 min tps 创建 cmap 过程 好的 对象
细心的小伙伴可能注意到了,svd_solver是奇异值分解器的意思,为什么PCA算法下面会有有关奇异值分解的参数?不是两种算法么?我们之前曾经提到过,PCA和SVD涉及了大量的矩阵计算,两者都是运算量很大的模型,但其实,SVD有一种惊人的数学性质,即是它可以跳过数学神秘的宇宙,不计算协方差矩阵,直接找出一个新特征向量组成的n维空间,而这个n维空间就是奇异值分解后的右矩阵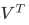 (所以一开始在讲解降维过程时,我们说”生成新特征向量组成的空间V",并非巧合,而是特指奇异值分解中的矩阵
(所以一开始在讲解降维过程时,我们说”生成新特征向量组成的空间V",并非巧合,而是特指奇异值分解中的矩阵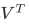 )。
)。

右奇异矩阵 有着如下性质:
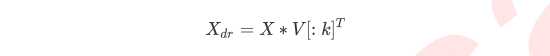
k就是n_components,是我们降维后希望得到的维度。若X为(m,n)的特征矩阵, 就是结构为(n,n)的矩阵,取这个矩阵的前k行(进行切片),即将V转换为结构为(k,n)的矩阵。
而$V_{(k,n)}^T$与原特征矩阵X相乘,即可得到降维后的特征矩阵X_dr。
这是说,奇异值分解可以不计算协方差矩阵等等结构复杂计算冗长的矩阵,就直接求出新特征空间和降维后的特征矩阵。
简而言之,SVD在矩阵分解中的过程比PCA简单快速,虽然两个算法都走一样的分解流程,但SVD可以作弊耍赖直接算出V。但是遗憾的是,SVD的信息量衡量指标比较复杂,要理解”奇异值“远不如理解”方差“来得容易,
因此,sklearn将降维流程拆成了两部分:一部分是计算特征空间V,由奇异值分解完成,另一部分是映射数据和求解新特征矩阵,由主成分分析完成,实现了用SVD的性质减少计算量,却让信息量的评估指标是方差,具体流程如下图: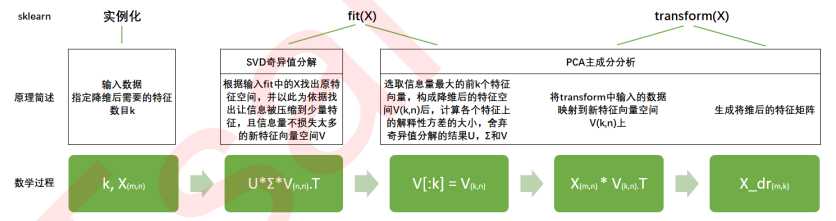
讲到这里,相信大家就能够理解,为什么PCA的类里会包含控制SVD分解器的参数了。通过SVD和PCA的合作,sklearn实现了一种计算更快更简单,但效果却很好的“合作降维“。
很多人理解SVD,是把SVD当作PCA的一种求解方法,其实指的就是在矩阵分解时不使用PCA本身的特征值分解,而使用奇异值分解来减少计算量。
这种方法确实存在,但在sklearn中,矩阵U和Σ虽然会被计算出来(同样也是一种比起PCA来说简化非常多的数学过程,不产生协方差矩阵),但完全不会被用到,也无法调取查看或者使用,因此我们可以认为,U和Σ在?t过后就被遗弃了。奇异值分解追求的仅仅是V,只要有了V,就可以计算出降维后的特征矩阵。在transform过程之后,?t中奇异值分解
的结果除了V(k,n)以外,就会被舍弃,而V(k,n)会被保存在属性components_ 当中,可以调用查看。
PCA(2).fit(X).components_
PCA(2).fit(X).components_.shape
参数svd_solver是在降维过程中,用来控制矩阵分解的一些细节的参数。有四种模式可选:"auto", "full", "arpack","randomized",默认”auto"。
"auto":基于X.shape和n_components的默认策略来选择分解器:如果输入数据的尺寸大于500x500且要提取的特征数小于数据最小维度min(X.shape)的80%,就启用效率更高的”randomized“方法。否则,精确完整的SVD将被计算,截断将会在矩阵被分解完成后有选择地发生
"full":从scipy.linalg.svd中调用标准的LAPACK分解器来生成精确完整的SVD,适合数据量比较适中,计算时间充足的情况,生成的精确完整的SVD的结构为: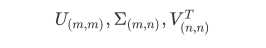
"arpack":从scipy.sparse.linalg.svds调用ARPACK分解器来运行截断奇异值分解(SVD truncated),分解时就将特征数量降到n_components中输入的数值k,可以加快运算速度,适合特征矩阵很大的时候,但一般用于特征矩阵为稀疏矩阵的情况,此过程包含一定的随机性。截断后的SVD分解出的结构为:
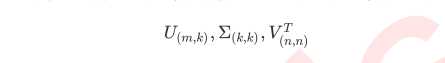
"randomized",通过Halko等人的随机方法进行随机SVD。在"full"方法中,分解器会根据原始数据和输入的n_components值去计算和寻找符合需求的新特征向量,但是在"randomized"方法中,分解器会先生成多个随机向量,然后一一去检测这些随机向量中是否有任何一个符合我们的分解需求,如果符合,就保留这个随机向量,并基于这个随机向量来构建后续的向量空间。这个方法已经被Halko等人证明,比"full"模式下计算快很多,并且还能够保证模型运行效果。适合特征矩阵巨大,计算量庞大的情况。
而参数random_state在参数svd_solver的值为"arpack" or "randomized"的时候生效,可以控制这两种SVD模式中的随机模式。通常我们就选用”auto“,不必对这个参数纠结太多。
现在我们了解了,V(k,n)是新特征空间,是我们要将原始数据进行映射的那些新特征向量组成的矩阵。我们用它来计算新的特征矩阵,但我们希望获取的毕竟是X_dr,为什么我们要把V(k,n)这个矩阵保存在n_components这个属性当中来让大家调取查看呢?
我们之前谈到过PCA与特征选择的区别,即特征选择后的特征矩阵是可解读的,而PCA降维后的特征矩阵式不可解读的:PCA是将已存在的特征进行压缩,降维完毕后的特征不是原本的特征矩阵中的任何一个特征,而是通过某些方式组合起来的新特征。
通常来说,在新的特征矩阵生成之前,我们无法知晓PCA都建立了怎样的新特征向量,新特征矩阵生成之后也不具有可读性,我们无法判断新特征矩阵的特征是从原数据中的什么特征组合而来,新特征虽然带有原始数据的信息,却已经不是原数据上代表着的含义了。
但是其实,在矩阵分解时,PCA是有目标的:在原有特征的基础上,找出能够让信息尽量聚集的新特征向量。
在sklearn使用的PCA和SVD联合的降维方法中,这些新特征向量组成的新特征空间其实就是V(k,n)。
当V(k,n)是数字时,我们无法判断V(k,n)和原有的特征究竟有着怎样千丝万缕的数学联系。
但是,如果原特征矩阵是图像,V(k,n)这个空间矩阵也可以被可视化的话,我们就可以通过两张图来比较,就可以看出新特征空间究竟从原始数据里提取了什么重要的信息。
让我们来看一个,人脸识别中属性components_的运用。
1. 导入需要的库和模块
from sklearn.datasets import fetch_lfw_people from sklearn.decomposition import PCA import matplotlib.pyplot as plt import numpy as np
2. 实例化数据集,探索数据
faces = fetch_lfw_people(min_faces_per_person=60) faces.images.shape #怎样理解这个数据的维度? faces.data.shape #换成特征矩阵之后,这个矩阵是什么样? X = faces.data
3. 看看图像什么样?将原特征矩阵进行可视化
#数据本身是图像,和数据本身只是数字,使用的可视化方法不同 #创建画布和子图对象 fig, axes = plt.subplots(4,5 ,figsize=(8,4) ,subplot_kw = {"xticks":[],"yticks":[]} #不要显示坐标轴 ) fig axes #不难发现,axes中的一个对象对应fig中的一个空格 #我们希望,在每一个子图对象中填充图像(共24张图),因此我们需要写一个在子图对象中遍历的循环 axes.shape #二维结构,可以有两种循环方式,一种是使用索引,循环一次同时生成一列上的三个图 #另一种是把数据拉成一维,循环一次只生成一个图 #在这里,究竟使用哪一种循环方式,是要看我们要画的图的信息,储存在一个怎样的结构里 #我们使用 子图对象.imshow 来将图像填充到空白画布上 #而imshow要求的数据格式必须是一个(m,n)格式的矩阵,即每个数据都是一张单独的图 #因此我们需要遍历的是faces.images,其结构是(1277, 62, 47) #要从一个数据集中取出24个图,明显是一次性的循环切片[i,:,:]来得便利 #因此我们要把axes的结构拉成一维来循环 axes.flat enumerate(axes.flat) #填充图像 for i, ax in enumerate(axes.flat): ax.imshow(faces.images[i,:,:] ,cmap="gray" #选择色彩的模式 ) #https://matplotlib.org/tutorials/colors/colormaps.html
4. 建模降维,提取新特征空间矩阵
#原本有2900维,我们现在来降到150维 pca = PCA(150).fit(X) V = pca.components_ V.shape
5. 将新特征空间矩阵可视化
fig, axes = plt.subplots(3,8,figsize=(8,4),subplot_kw = {"xticks":[],"yticks":[]})
for i, ax in enumerate(axes.flat):
ax.imshow(V[i,:].reshape(62,47),cmap="gray")
这张图稍稍有一些恐怖,但可以看出,比起降维前的数据,新特征空间可视化后的人脸非常模糊,这是因为原始数据还没有被映射到特征空间中。
但是可以看出,整体比较亮的图片,获取的信息较多,整体比较暗的图片,却只能看见黑漆漆的一块。在比较亮的图片中,眼睛,鼻子,嘴巴,都相对清晰,脸的轮廓,头发之类的比较模糊。
这说明,新特征空间里的特征向量们,大部分是"五官"和"亮度"相关的向量,所以新特征向量上的信息肯定大部分是由原数据中和"五官"和"亮度"相关的特征中提取出来的。
到这里,我们通过可视化新特征空间V,解释了一部分降维后的特征:虽然显示出来的数字看着不知所云,但画出来的图表示,这些特征是和”五官“以及”亮度“有关的。
这也再次证明了,PCA能够将原始数据集中重要的数据进行聚集。
机器学习实战基础(二十三):sklearn中的降维算法PCA和SVD(四) PCA与SVD 之 PCA中的SVD
标签:imshow 大量 min tps 创建 cmap 过程 好的 对象
原文地址:https://www.cnblogs.com/qiu-hua/p/12988450.html