标签:获得 用户 red turn 连接 sys 原理 不用 form
1、django的处理流程是什么?2、简单描述写你了解的django?
答:django模型是根据MVT模型的,模型即数据存取层,负责与数据库进行交互的,模板即表现层,渲染页面返回给客户端的,视图是业务逻辑层,视图不处理用户输入,而仅仅决定要展现哪些数据给用户,URLconf机制是使用正则表达式匹配URL,控制处理流程。
3、如何删除一个列表中重复的元素?
答:思路都是放置一个空列表
[root@node-2 yhc]# cat 1.py
#!/usr/bin/env python
list1=[5,2,3,3,4,1]
temp=[]
for i in range(len(list1)):
if list1[i] not in temp:
temp.append(list1[i])
temp.sort()
print temp
4、把字典的Key-Value值翻转?
dict2={1:‘a‘,2:‘b‘,3:‘c‘}
def test(dict_name):
... return dict( (v,k) for k,v in dict_name.iteritems() ) #输出k,v是1 a
...
test(dict2)
{‘a‘: 1, ‘c‘: 3, ‘b‘: 2}iteritems()方法是字典项生成器,紧接着是列表表达式,
print dict1.items() ##items()方法是将字典的每个项作为元组,然后把所有把所有元组放在一个列表容器中
[(1, 7), (2, 8), (3, 9)]
#coding: utf-8
def QuickSort(myList,start,end):
if start < end: #判断low是否小于high,如果为false,直接返回
i,j = start,end
base = myList[i] #设置基准数
while i < j:
while (i < j) and (myList[j] >= base):
#如果列表后边的数,比基准数大或相等,则前移一位直到有比基准数小的数出现
j = j - 1
myList[i] = myList[j]
#如找到,则把第j个元素赋值给第i个元素,此时表中i,j个元素相等
while (i < j) and (myList[i] <= base): #同样的方式比较前半区
i = i + 1
myList[j] = myList[i]
myList[i] = base #做完第一轮比较之后,列表被分成了两个半区,并且i=j,需要将这个数设置回base
QuickSort(myList, start, i - 1)
QuickSort(myList, j + 1, end)
return myList
myList = [5,4,3,2,1]
print("Quick Sort: ")
QuickSort(myList,0,len(myList)-1)
print(myList)
(2)优点:分治算法采用中间值作为基准数的话,分为两个等长子序列,效率会比较高
(3)缺点:如果有大量元素相同,那么进行反复的位置交换是没有必要的,会造成不稳定
(4)时间复杂度:n/2^k = 1,解得k = nlogn,因为它是每次都切割为一半,所以每次递归都要除以2。在有序的情况下,时间复杂度最高,因为每次分割的单位是1,时间复杂度是O(n^2)。假设有1到8代表要排序的数,快速排序会递归log(8)=3次,每次对n个数进行一次处理,所以他的时间复杂度为n*log(n)。所以排序问题的时间复杂度可以认为是对排序数据的总的操作次数。
参考文档:https://blog.csdn.net/qfikh/article/details/52870875
6、说说python的语言特性?
答:(1)动态强类型语言,所谓动态就是运行过程中可以改变的类型的属性,并且python没有常量,不需要提前定义数据类型,所谓强类型就是不能隐式转换数据类型,只能进行强制的数据类型转换。
(2)面向对象设计,封装继承多态,对对象的修改影响全局
7、类的装饰器有哪些?
答:(1)property属性装饰器:调用类中的方法和调用属性一样,这个装饰器还有和其配套的setter、deleter。
(2) staticmethod静态方法装饰器:将类内的方法变成普通的函数,或者把类外的函数放到类内当作方法调用,不用加self参数
(3) classmethod类方法装饰器:该方法用于操作类属性,无法操作对象属性,就是定义在类中的一个变量,类可以不实例化就能调用函数,也可以实例化调用该函数。
参考文档:https://www.cnblogs.com/lfpython/p/7346385.html
8、已知列表a=[1,2,3],列表b=[4,5,6],如何打印出[(1,2,3),(4,5,6)]的形式?
答:>>> a = [1,2,3]
b = [4,5,6]
zipped = zip(a,b)
zip(*zipped) ##相当于解压
[(1, 2, 3), (4, 5, 6)]
解析:python是zip函数将对象的元素按照索引位置打包成元组,然后以元组作为列表元素的方式进行返回
参考文档:http://www.runoob.com/python/python-func-zip.html
9、说说垃圾回收机制?如果不垃圾回收,会导致什么?
答:(1)引用计数跟踪机制,当引用计数的数值减为0的时候,内存会被回收;在引用计数的基础上,还可以通过“标记-清除”解决容器对象可能产生的循环引用(对象之间相互引用)的问题。通过分代回收以空间换取时间进一步提高垃圾回收的效率。
(2)原理:当一个对象的引用被创建或者复制时,对象的引用计数加1;当一个对象的引用被销毁时,对象的引用计数减1,当对象的引用计数减少为0时,就意味着对象已经再没有被使用了,可以将其内存释放掉。
(3)后果:如果不垃圾回收,会导致内存泄漏
参考文档:https://www.cnblogs.com/George1994/p/7349871.html
10、Python里面如何生成随机数?
答:random模块
返回随机整数x,a<=x<=b:random.randint(a,b) ##这个random是类,不是模块
返回一个范围在(start,stop,step)之间的随机整数,不包括结束值: random.randrange(start,stop,[,step])
随机返回0到1之间的浮点数:random.random( )
返回指定范围内的浮点数:random.uniform(a,b)
11、Python里面search()和match()的区别?
答:(1)match( )方法会检查第一个字符是否匹配,如果匹配则继续,如果不匹配则返回None;
search( )方法会扫描整个字符串,然后匹配子字符串所在的位置
import re
print re.match(‘super‘,‘superman‘)
<_sre.SRE_Match object at 0x7f9002a5a8b8>
print re.match(‘super‘,‘superman‘).span() ##span( )方法返回索引位置,在这里和search方法相同
(0, 5)
print re.match(‘super‘,‘notsuperman‘)
None
print re.search(‘super‘,‘notsuperman‘).span()
(3, 8)
(2)search方法如果有多个返回结果的话,只会返回第一个结果
参考文档:https://www.cnblogs.com/xiao987334176/p/9053567.html
12、Python是如何进行内存管理的?
答:从三个方面来说,一对象的引用计数机制,二垃圾回收机制,三内存池机制
一、对象的引用计数机制
Python内部使用引用计数,来保持追踪内存中的对象,所有对象都有引用计数。
引用计数增加的情况:
1,一个对象分配一个新名称
2,将其放入一个容器中(如列表、元组或字典)
引用计数减少的情况:
1,使用del语句对对象别名显示的销毁
2,引用超出作用域或被重新赋值
sys.getrefcount( )函数可以获得对象的当前引用计数
多数情况下,引用计数比你猜测得要大得多。对于不可变数据(如数字和字符串),解释器会在程序的不同部分共享内存,以便节约内存。
二、垃圾回收
1,当一个对象的引用计数归零时,它将被垃圾收集机制处理掉。
2,当两个对象a和b相互引用时,del语句可以减少a和b的引用计数,并销毁用于引用底层对象的名称。然而由于每个对象都包含一个对其他对象的应用,因此引用计数不会归零,对象也不会销毁。(从而导致内存泄露)。为解决这一问题,解释器会定期执行一个循环检测器,搜索不可访问对象的循环并删除它们。
三、内存池机制
Python提供了对内存的垃圾收集机制,但是它将不用的内存放到内存池而不是返回给操作系统。
1,Pymalloc机制。为了加速Python的执行效率,Python引入了一个内存池机制,用于管理对小块内存的申请和释放。
2,Python中所有小于256个字节的对象都使用pymalloc实现的分配器,而大的对象则使用系统的malloc。
3,对于Python对象,如整数,浮点数和List,都有其独立的私有内存池,对象间不共享他们的内存池。也就是说如果你分配又释放了大量的整数,用于缓存这些整数的内存就不能再分配给浮点数
参考文档:http://mp.weixin.qq.com/s/mEXEcGjb5Bc5wyPPhzI8Ow
13、一个python类的实例如何变成一个可以调用的对象?
答:使用call( )方法,把类的实例作为一个可调用的对象,理解可调用就是理解为一个函数,然后加个括号不就是调用了吗,可能传个参数
举例:
class A(object):
def init(self, a, b):
self.a = a
self.b = b
def myprint(self):
print ‘a=‘, self.a, ‘b=‘, self.b
def call(self, num):
print ‘call:‘, num + self.__a
a1 =A(10.20)
a1(80)
print ‘call:‘90
14、Python中repr和str有何区别?
答:(1)str方法面向用户,直接把实例p回车,会输出内存地址,不会友好显示,打算print 实例p会进行友好显示,不显示内存地址,而显示其他东西;
(2)repr( )方法面向程序员,直接把实例p回车或者print 实例p都会友好显示,均不显示内存地址,显示手动定义的内容。
参考文档:http://blog.csdn.net/luckytanggu/article/details/53649156
15、python类中的new方法和init方法有何区别?
答:(1)new方法用来创建对象实例,而init方法用来初始化对象实例,在初始化实例之前,必须经过new方法的允许,才能进行执行init方法
(2)init方法使用self参数,而new方法使用cls参数
(3)new方法的特性是:第一,new方法在类准备实例化的时候调用,比如当执行p1 = Person(‘yhc‘)的时候,先调用new方法,再调用init方法;第二,new方法是类中的静态方法,即使没有加上静态方法装饰器。
(4)new方法在创建对象时调用,并且返回对象的cls实例,init在创建完对象后调用,无return返回值。如果new()没有返回cls(即当前类)的实例,那么当前类的init()方法是不会被调用的。如果new()返回其他类(新式类或经典类均可)的实例,那么只会调用被返回的那个类的构造方法。
参考文档:http://www.cnblogs.com/ifantastic/p/3175735.html
16、设计模式的单例模式应用场景
答:(1)所谓单例模式,也就是说不管什么时候都要确保只有一个类的对象实例存在。很多情况下,整个系统中只需要存在一个对象,所有的信息都从这个对象获取,比如系统的配置对象,或者是线程池。这些场景下,就非常适合使用单例模式。
总结起来,就是说不管初始化一个对象多少次,真正干活的对象只会生成一次并且在首次生成。
(2)应用场景在数据库的连接池
[root@ceph01 py]# cat 06.py
class Foo(object):
instance = None
def init(self, name):
self.name = namebr/>@classmethod
def get_instance(cls):
if cls.instance:
return cls.instance
else:
obj = cls(‘hexm‘)
cls.instance = obj
return obj
obj = Foo.get_instance()
obj1 = Foo.get_instance()
print(obj.name)
print(obj1.name)
print(Foo.instance)
print(obj)
[root@ceph01 py]# python 06.py
hexm
hexm
<main.Foo object at 0x7fb2e20e5bd0>
<main.Foo object at 0x7fb2e20e5bd0>
参考文档:https://www.cnblogs.com/xiaoming279/p/6106232.html
17、子类重写了父类的方法,那么如何实现让子类的实例访问父类的方法呢?
答:修改子类实例的class属性为父类的类名即可。比如
class A(object):
def show(self):
print ‘-----this i s A classs-----‘
class B(A):
def show (self):
pint ‘------this is B class --------‘
obj = B()
obj.show()
------this is B class --------obj.class = A
obj.show()
-----this i s A classs-----第二种方法就是改变子类中的new方法,得到父类的实例,从而调用父类的方法。
18、谈谈你理解类中的super( )超类?
答:(1)值得注意的是,super不是一个方法,而是一个类,super方法解决多继承问题,调用父类的方法。
(2)super(子类名,子类转为父类的对象).父类方法名( );super(FooChild,self) 首先找到 FooChild 的父类(就是类 FooParent),然后把类B的对象 FooChild 转换为类 FooParent 的对象
19、一个包里有三个模块,mod1.py, mod2.py, mod3.py,但使用from demopack import *导入模块时,如何保证只有mod1、mod3被导入了?
答:在该目录下添加一个init.py,里面的内容添加all = [‘mod1‘,‘mod3‘]即可
20、django里面常用到什么模块,ORM(Object Relational Mapping关系对象映射)需要用到什么模块?
答:(1)render渲染模块,,User用户权限模块,urls定义URL访问模块,以及定义数据库表设计所需的models模块、ModelForm(django自带的表单模块)、Django自带的auth认证模块。
(2)ORM需要用到models模块、ContentType模块、auth认证模块、
注:logging日志模块是Python自带的
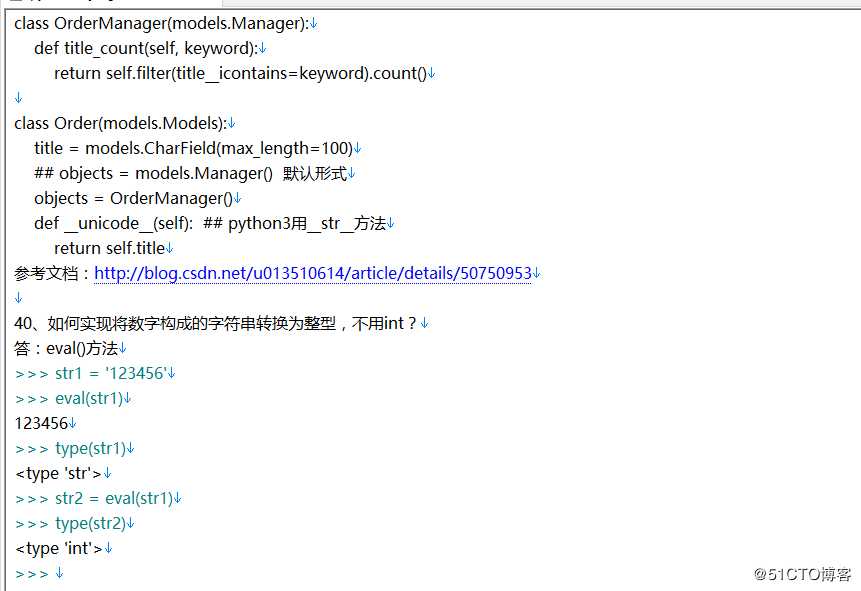
此篇文章,还有20道题目,在我的面经中,详情看下面。
我会持续更新面试题目,包括linux,前端(vue,jquery,css)、python、mysql和redis的面经题目,后期加入golang。可以加我qq 2093905919或者微信 18828004657,跟我聊聊。(注:可以分享一部分面试题目,觉得可以的话,剩下的全部面试题目(多年经验,非常多而广的题目,适合突击面试复习,适合运维工程师,python工程师,运维开发,甚至前端开发(vue,asp,jquery)等等),需要打赏200元,绝对物超所值)
标签:获得 用户 red turn 连接 sys 原理 不用 form
原文地址:https://blog.51cto.com/14830489/2500185