标签:str code 一段 网页 tail idf 表示 排列 简单
拜读了两篇大作,受益匪浅,感谢!
这孩子谁懂哈 https://blog.csdn.net/zhaomengszu/article/details/81452907
elly https://zhuanlan.zhihu.com/p/94446764
TF-IDF(Term Frequency-inverse Document Frequency)是一种针对 关键词的统计分析方法
用于评估一个词 对 一个文件集 或者 一个语料库 的 重要程度
一个词的重要程度跟它在文章中出现的次数成 正比
跟它在语料库出现的次数成 反比
这种计算方式能有效避免常用词对关键词的影响,提高了关键词与文章之间的相关性。

考虑到文章有长短之分,为了便于不同文章的比较,进行"词频"标准化。

或者

需要一个语料库(corpus),用来模拟语言的使用环境。

如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词)。log表示对得到的值取对数。
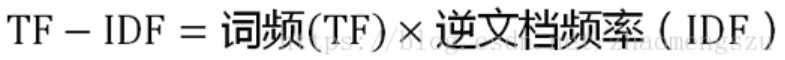
TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比。所以,自动提取关键词的算法就很清楚了,就是计算出文档的每个词的TF-IDF值,然后按降序排列,取排在最前面的几个词。
给个例子:例子来自
以《中国的蜜蜂养殖》为例,假定该文长度为1000个词,"中国"、"蜜蜂"、"养殖"各出现20次,则这三个词的"词频"(TF)都为0.02。然后,搜索Google发现,包含"的"字的网页共有250亿张,假定这就是中文网页总数。包含"中国"的网页共有62.3亿张,包含"蜜蜂"的网页为0.484亿张,包含"养殖"的网页为0.973亿张。则它们的逆文档频率(IDF)和TF-IDF如下:
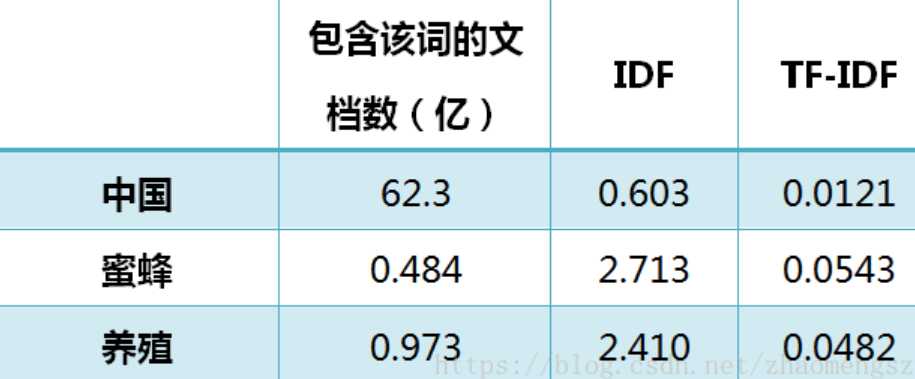
从上表可见,"蜜蜂"的TF-IDF值最高,"养殖"其次,"中国"最低。(如果还计算"的"字的TF-IDF,那将是一个极其接近0的值。)所以,如果只选择一个词,"蜜蜂"就是这篇文章的关键词。
除了自动提取关键词,TF-IDF算法还可以用于许多别的地方。比如,信息检索时,对于每个文档,都可以分别计算一组搜索词("中国"、"蜜蜂"、"养殖")的TF-IDF,将它们相加,就可以得到整个文档的TF-IDF。这个值最高的文档就是与搜索词最相关的文档。
TF-IDF算法的优点是简单快速,结果比较符合实际情况。缺点是,单纯以"词频"衡量一个词的重要性,不够全面,有时重要的词可能出现次数并不多。而且,这种算法无法体现词的位置信息,出现位置靠前的词与出现位置靠后的词,都被视为重要性相同,这是不正确的。(一种解决方法是,对全文的第一段和每一段的第一句话,给予较大的权重。)
标签:str code 一段 网页 tail idf 表示 排列 简单
原文地址:https://www.cnblogs.com/duoba/p/13156897.html