标签:his params 获取 而不是 value 思路 集中 error rom
通过前面两篇文章,我们完成了对 MyBatis 所有配置文件(包括配置文件和映射文件)解析过程的分析。回忆一下我们最开始给出的小示例(如下),经过前面的跋山涉水,我们终于完成了第一行代码的 99% (手动滑稽),这最后的 1% 就是创建 SqlSessionFactory 对象。所有的配置解析最后都会封装到 Configuration 对象中,接下去就是调用 SqlSessionFactoryBuilder#build 方法创建 SqlSessionFactory 对象,实际使用的是 DefaultSqlSessionFactory 实现类进行实例化。
SqlSessionFactory sessionFactory = new SqlSessionFactoryBuilder()
.build(Resources.getResourceAsStream("mybatis-config.xml"));
try (SqlSession sqlSession = sessionFactory.openSession()) {
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
User user = mapper.selectByName("zhenchao");
// ... use user object
}
SqlSessionFactory 是一个工厂类,用于创建 SqlSession 对象。按照官方文档的说明,SqlSessionFactory 对象一旦被创建就应该在应用的运行期间一直存在,不应该在运行期间对其进行清除或重建。调用该工厂的 SqlSessionFactory#openSession 方法可以开启一次会话,即创建一个 SqlSession 对象。SqlSession 封装了面向数据库执行 SQL 的所有 API,它不是线程安全的,因此不能被共享,所以该对象的最佳作用域是请求或方法作用域。在上面的示例中,我们用 SqlSession 拿到相应的 Mapper 接口对象(更准确的说是一个动态代理对象),然后执行指定的数据库操作,最后关闭此次会话。
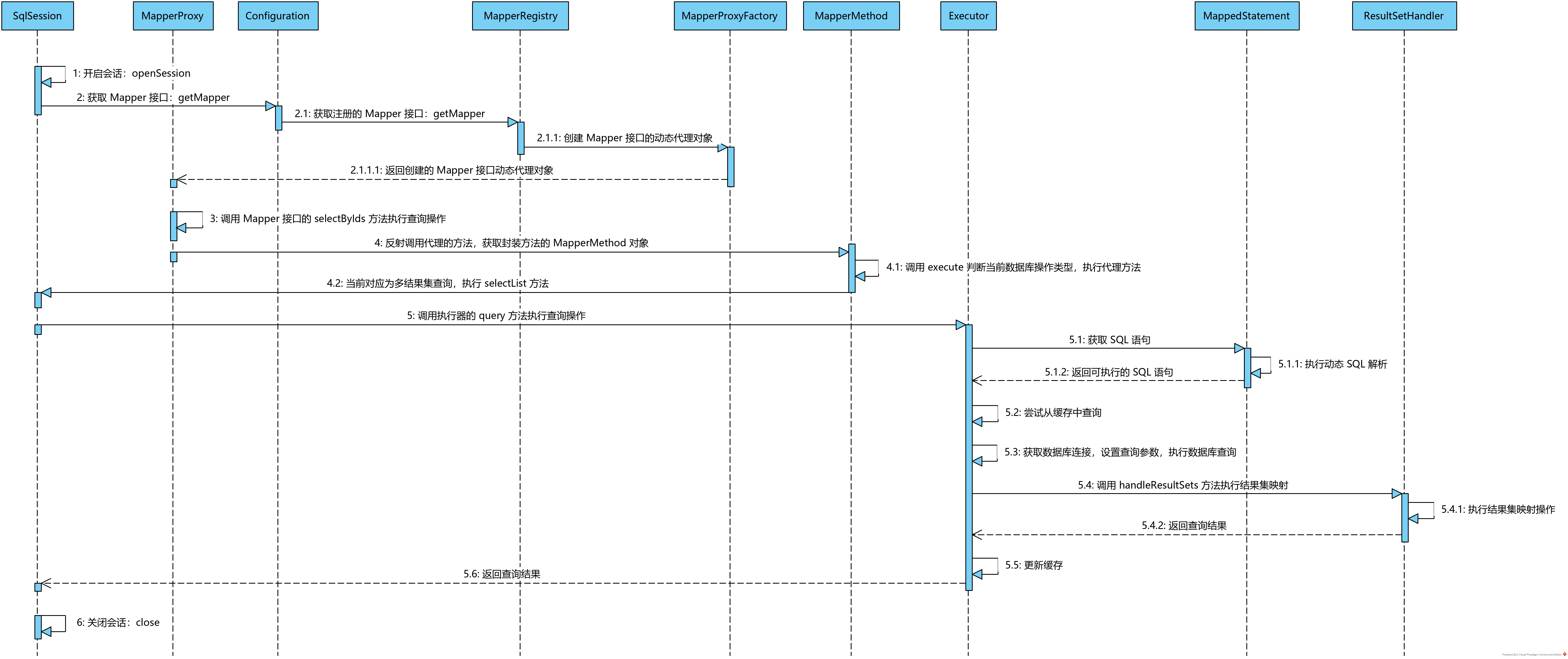
上面这张时序图我们在本系列开篇的文章中已经引用过,描绘了 MyBatis 在一次会话生命周期内执行数据库操作的交互时序。下面对这幅图中所描绘的执行过程中类之间的交互时序关系作进一步说明,稍后我们会对图中涉及到的类和接口从源码层面进行分析,执行时序如下:
SqlSessionFactory#openSession 方法创建 SqlSession 对象,开启一次会话;SqlSession#getMapper 方法获取指定的 Mapper 接口对象,这里实际上将请求委托给 Configuration#getMapper 方法执行,由前面分析映射文件解析过程时我们知道所有的 Mapper 接口都会注册到全局唯一的配置对象 Configuration 的 MapperRegistry 类型属性中;MapperRegistry#getMapper 操作时会反射创建 Mapper 接口的动态代理对象并返回;UserMapper#selectByName),即调用 Mapper 接口动态代理对象的 MapperProxy#invoke 方法,在该方法中会获取封装执行方法的 MapperMethod 对象;MapperMethod#execute 方法,该方法会判定当前数据库操作类型(例如 SELECT),依据类型选择执行 SqlSession 对应的数据库操作方法;SqlSession#close 方法关闭本次会话。整个过程围绕一次查询操作展开,虽然不能覆盖 MyBatis 执行 SQL 语句的各个方面,但主线上还是能够说明白 MyBatis 针对一次 SQL 执行的大概过程。在下面的篇幅中,我们将一起分析这一整套时序背后的实现机制。
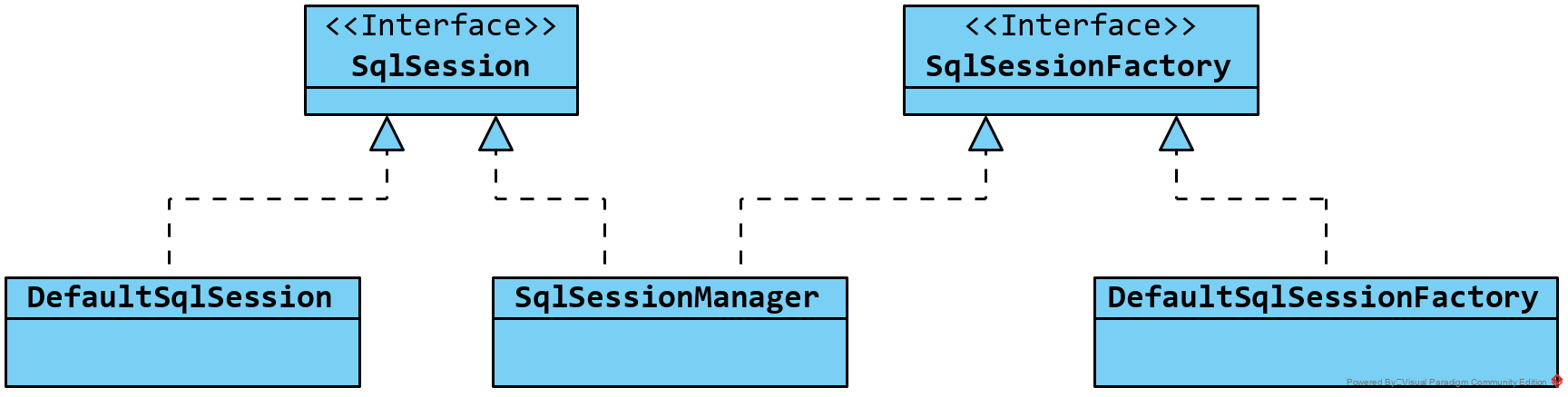
SqlSession 接口是 MyBatis 对外提供的数据库操作 API,是 MyBatis 的核心接口之一,用于管理一次数据库会话。围绕 SqlSession 接口的类继承关系如下图所示,其中 DefaultSqlSession 是默认的 SqlSession 实现。SqlSessionFactory 是一个工厂接口,其功能是用来创建 SqlSession 对象,该接口中声明了多个重载版本的 SqlSessionFactory#openSession 方法,DefaultSqlSessionFactory 是该接口的默认实现。上述示例程序中 SqlSessionFactoryBuilder#build 方法就是基于该实现类创建的 SqlSessionFactory 对象。SqlSessionManager 类实现了这两个接口,所以具备创建、使用,以及管理 SqlSession 对象的能力,后面会详细说明。
SqlSession 接口中声明的方法都比较直观,感兴趣的读者可以自行阅读源码。我们来看一下针对该接口的默认实现类 DefaultSqlSession,该类的属性定义如下:
/** 全局唯一的配置对象 */
private final Configuration configuration;
/** SQL 语句执行器 */
private final Executor executor;
/** 是否自动提交事务 */
private final boolean autoCommit;
/** 标记当前缓存中是否存在脏数据 */
private boolean dirty;
/** 记录已经打开的游标 */
private List<Cursor<?>> cursorList;
DefaultSqlSession 中的方法实现基本上都是对 Executor 接口方法的封装,实现上都比较简单。这里解释一下 DefaultSqlSession#cursorList 这个属性,在 DefaultSqlSession#selectCursor 方法中会记录查询返回的游标(Cursor)对象,并在关闭 SqlSession 会话时遍历集合逐一关闭,从而防止打开的游标没有被关闭的现象。
DefaultSqlSessionFactory 是 SqlSessionFactory 接口的默认实现,用于创建 SqlSession 对象。该实现类提供了两种创建 SqlSession 对象的方式,分别是基于当前数据源创建会话和基于当前数据库连接创建会话,对应的实现如下。
private SqlSession openSessionFromDataSource(
ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
Transaction tx = null;
try {
// 获取当前激活的数据库环境配置
final Environment environment = configuration.getEnvironment();
// 获取当前数据库环境对应的 TransactionFactory 对象,不存在的话就创建一个
final TransactionFactory transactionFactory = this.getTransactionFactoryFromEnvironment(environment);
tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
// 依据指定的 Executor 类型创建对应的 Executor 对象
final Executor executor = configuration.newExecutor(tx, execType);
// 创建 SqlSession 对象
return new DefaultSqlSession(configuration, executor, autoCommit);
} catch (Exception e) {
this.closeTransaction(tx); // may have fetched a connection so lets call close()
throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
private SqlSession openSessionFromConnection(ExecutorType execType, Connection connection) {
try {
boolean autoCommit;
try {
autoCommit = connection.getAutoCommit();
} catch (SQLException e) {
// 考虑到很多驱动或者数据库不支持事务,设置自动提交事务
autoCommit = true;
}
// 获取当前激活的数据库环境配置
final Environment environment = configuration.getEnvironment();
// 获取当前数据库环境对应的 TransactionFactory 对象,不存在的话就创建一个
final TransactionFactory transactionFactory = this.getTransactionFactoryFromEnvironment(environment);
final Transaction tx = transactionFactory.newTransaction(connection);
// 依据指定的 Executor 类型创建对应的 Executor 对象
final Executor executor = configuration.newExecutor(tx, execType);
// 创建 SqlSession 对象
return new DefaultSqlSession(configuration, executor, autoCommit);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
两种创建会话的方式在执行流程上基本一致,具体细节如上述代码注释。
SqlSessionManager 同时实现了 SqlSessionFactory 和 SqlSession 两个接口,所以具备这两个接口全部的功能。该实现类的属性定义如下:
/** 封装的 {@link SqlSessionFactory} 对象 */
private final SqlSessionFactory sqlSessionFactory;
/** 线程私有的 SqlSession 对象的动态代理对象 */
private final SqlSession sqlSessionProxy;
/** 线程私有的 SqlSession 对象 */
private final ThreadLocal<SqlSession> localSqlSession = new ThreadLocal<SqlSession>();
针对 SqlSessionFactory 接口中声明的方法,SqlSessionManager 均委托给持有的 SqlSessionFactory 对象完成。对于 SqlSession 接口中声明的方法,SqlSessionManager 提供了两种实现方式:如果当前线程已经绑定了一个 SqlSession 对象,那么只要未主动调用 SqlSessionManager#close 方法,就会一直复用该线程私有的 SqlSession 对象;否则会在每次执行数据库操作时创建一个新的 SqlSession 对象,并在使用完毕之后关闭会话。相关逻辑位于 SqlSessionInterceptor 类中,这是一个定义在 SqlSessionManager 中的内部类,属性 SqlSessionManager#sqlSessionProxy 是基于该类实现的动态代理对象:
this.sqlSessionProxy = (SqlSession) Proxy.newProxyInstance(
SqlSessionFactory.class.getClassLoader(), new Class[]{SqlSession.class}, new SqlSessionInterceptor());
SqlSessionInterceptor 类实现自 InvocationHandler 接口,对应的 SqlSessionInterceptor#invoke 方法实现如下:
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
// 获取当前线程私有的 SqlSession 对象
final SqlSession sqlSession = localSqlSession.get();
// 会话未被关闭
if (sqlSession != null) {
try {
// 直接反射调用相应的方法
return method.invoke(sqlSession, args);
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
// 没有 SqlSession,或已关闭,创建一个,使用完毕之后即关闭会话
else {
try (SqlSession autoSqlSession = SqlSessionManager.this.openSession()) {
try {
// 反射调用相应的方法
final Object result = method.invoke(autoSqlSession, args);
// 提交事务
autoSqlSession.commit();
return result;
} catch (Throwable t) {
// 回滚事务
autoSqlSession.rollback();
throw ExceptionUtil.unwrapThrowable(t);
}
}
}
}
SqlSessionInterceptor 首先会尝试获取线程私有的 SqlSession 对象,对于未绑定的线程来说会创建一个新的 SqlSession 对象,并在使用完毕之后立刻关闭。
MyBatis 要求所有的 Mapper 都定义成接口的形式,这主要是为了配合 JDK 内置的动态代理机制,JDK 内置的动态代理要求被代理的类必须抽象出一个接口。常用的动态代理除了 JDK 内置的方式,还有基于 CGlib 等第三方组件的方式,MyBatis 采用了 JDK 内置的方式创建 Mapper 接口的动态代理对象。
我们先来复习一下 JDK 内置的动态代理机制,假设现在有一个接口 Mapper 及其实现类如下:
public interface Mapper {
int select();
}
public class MapperImpl implements Mapper {
@Override
public int select() {
System.out.println("do select.");
return 0;
}
}
现在我们希望在方法执行之前打印一行调用日志,基于动态代理的实现方式如下。我们需要定义一个实现了 InvocationHandler 接口的代理类,然后在其 InvocationHandler#invoke 方法中实现增强逻辑:
public class MapperProxy implements InvocationHandler {
private Mapper mapper;
public MapperProxy(Mapper mapper) {
this.mapper = mapper;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println("before invoke.");
return method.invoke(this.mapper, args);
}
}
客户端调用代码:
Mapper mapper = new MapperImpl();
Mapper mapperProxy = (Mapper) Proxy.newProxyInstance(
mapper.getClass().getClassLoader(), mapper.getClass().getInterfaces(), new MapperProxy(mapper));
mapperProxy.select();
回到 MyBatis 框架本身,我们在执行目标数据库操作时,一般会直接调用目标 Mapper 接口的相应方法,这里框架返回给我们的实际上是 Mapper 接口的动态代理类对象。MyBatis 基于 JDK 的动态代理机制实现了 Mapper 接口中声明的方法,这其中包含了 获取 SQL 语句、参数绑定、缓存操作、数据库操作,以及结果集映射处理 等步骤,下面就 Mapper 接口动态代理机制涉及到的相关类和方法进行分析。
上一篇在分析映射文件时我们介绍了在 MapperRegistry#knownMappers 属性中记录了 Mapper 接口与 MapperProxyFactory 的映射关系,MapperProxyFactory 顾名思义是 MapperProxy 的工厂类,其中定义了创建 Mapper 接口代理对象的方法,如下:
public T newInstance(SqlSession sqlSession) {
final MapperProxy<T> mapperProxy = new MapperProxy<>(sqlSession, mapperInterface, methodCache);
return this.newInstance(mapperProxy);
}
protected T newInstance(MapperProxy<T> mapperProxy) {
// 创建 Mapper 接口对应的动态代理对象(基于 JDK 内置的动态代理机制)
return (T) Proxy.newProxyInstance(
mapperInterface.getClassLoader(),
new Class[] {mapperInterface},
mapperProxy);
}
来看一下 MapperProxy 实现,该类实现了 InvocationHandler 接口,对应的 InvocationHandler#invoke 实现如下:
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
// 对于 Object 类中声明的方法,直接调用
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, args);
}
// 对于非 Object 类中声明的方法
else {
// 获取方法关联的 MapperMethodInvoker 对象,并执行数据库操作
return this.cachedInvoker(method).invoke(proxy, method, args, sqlSession);
}
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
上述方法的核心逻辑在于获取当前执行方法 Method 对象对应的 MapperMethodInvoker 方法调用器,并执行 MapperMethodInvoker#invoke 方法触发对应的数据库操作。
围绕 MapperMethodInvoker 接口,MyBatis 提供了两种实现,即 DefaultMethodInvoker 和 PlainMethodInvoker,其中前者用于支持 JDK 7 引入的动态类型语言特性,后者则是对 MapperMethod 的封装。MapperMethod 中主要定义两个内部类:
先来看一下 SqlCommand 的具体实现,该类定义了 SqlCommand#name 和 SqlCommand#type 两个属性,分别用于记录对应 SQL 语句的名称和类型,并在构造方法中实现了相应的解析逻辑和初始化操作,如下:
public SqlCommand(Configuration configuration, Class<?> mapperInterface, Method method) {
// 获取方法名称
final String methodName = method.getName();
// 获取方法隶属的类或接口的 Class 对象
final Class<?> declaringClass = method.getDeclaringClass();
// 解析方法关联的 SQL 语句对应的 MappedStatement 对象(用于封装 SQL 语句)
MappedStatement ms = this.resolveMappedStatement(mapperInterface, methodName, declaringClass, configuration);
// 未找当前方法对应的 MappedStatement 对象
if (ms == null) {
// 如果对应方法注解了 @Flush,表示执行缓存的批量更新语句,则进行标记
if (method.getAnnotation(Flush.class) != null) {
name = null;
type = SqlCommandType.FLUSH;
} else {
throw new BindingException(
"Invalid bound statement (not found): " + mapperInterface.getName() + "." + methodName);
}
}
// 找当前方法对应的 MappedStatement 对象,初始化 SQL 语句名称和类型
else {
name = ms.getId();
type = ms.getSqlCommandType();
if (type == SqlCommandType.UNKNOWN) {
throw new BindingException("Unknown execution method for: " + name);
}
}
}
private MappedStatement resolveMappedStatement(
Class<?> mapperInterface, String methodName, Class<?> declaringClass, Configuration configuration) {
// 接口名称.方法名
String statementId = mapperInterface.getName() + "." + methodName;
// 方法存在关联的 SQL 语句,则获取封装该 SQL 语句的 MappedStatement 对象
if (configuration.hasStatement(statementId)) {
return configuration.getMappedStatement(statementId);
}
// 已经递归到该方法隶属的最上层类,但是仍然没有找到关联的 MappedStatement 对象
else if (mapperInterface.equals(declaringClass)) {
return null;
}
// 沿着继承关系向上递归检索
for (Class<?> superInterface : mapperInterface.getInterfaces()) {
if (declaringClass.isAssignableFrom(superInterface)) {
// 递归检索
MappedStatement ms = this.resolveMappedStatement(
superInterface, methodName, declaringClass, configuration);
if (ms != null) {
return ms;
}
}
}
return null;
}
SqlCommand 在实例化时所做的主要工作就是解析当前 Mapper 方法关联的 SQL 对应的 MappedStatement 对象,并初始化记录的 SQL 语句名称和类型,整个解析过程如上述代码注释。
再来看一下 MethodSignature 类,该类用于封装一个具体 Mapper 方法的相关签名信息,其中定义的方法实现都比较简单,这里列举一下其属性定义:
/** 标记返回值是否是 {@link java.util.Collection} 或数组类型 */
private final boolean returnsMany;
/** 标记返回值是否是 {@link Map} 类型 */
private final boolean returnsMap;
/** 标记返回值是否是 {@link Void} 类型 */
private final boolean returnsVoid;
/** 标记返回值是否是 {@link Cursor} 类型 */
private final boolean returnsCursor;
/** 标记返回值是否是 {@link Optional} 类型 */
private final boolean returnsOptional;
/** 返回值类型 */
private final Class<?> returnType;
/** 对于 Map 类型的返回值,用于记录 key 的别名 */
private final String mapKey;
/** 标记参数列表中 {@link ResultHandler} 的下标 */
private final Integer resultHandlerIndex;
/** 标记参数列表中 {@link RowBounds} 的下标 */
private final Integer rowBoundsIndex;
/** 参数名称解析器 */
private final ParamNameResolver paramNameResolver;
上面属性中重点介绍一下 ParamNameResolver 这个类,它的作用在于解析 Mapper 方法的参数列表,以便于在方法实参和方法关联的 SQL 语句的参数之间建立映射关系。其中一个比较重要的属性是 ParamNameResolver#names,定义如下:
/**
* 记录参数在参数列表中的下标和参数名称之间的对应关系。
* 参数名称通过 {@link Param} 注解指定,如果没有指定则使用参数下标作为参数名称,
* 需要注意的是,如果参数列表中包含 {@link RowBounds} 或 {@link ResultHandler} 类型的参数,
* 这两种功能型参数不会记录到集合中,此时如果用下标表示参数名称,索引值 key 与对应的参数名称(实际索引)可能会不一致。
*
* <p>
* The key is the index and the value is the name of the parameter.<br />
* The name is obtained from {@link Param} if specified. When {@link Param} is not specified,
* the parameter index is used. Note that this index could be different from the actual index
* when the method has special parameters (i.e. {@link RowBounds} or {@link ResultHandler}).
* </p>
* <ul>
* <li>aMethod(@Param("M") int a, @Param("N") int b) -> {{0, "M"}, {1, "N"}}</li>
* <li>aMethod(int a, int b) -> {{0, "0"}, {1, "1"}}</li>
* <li>aMethod(int a, RowBounds rb, int b) -> {{0, "0"}, {2, "1"}}</li>
* </ul>
*/
private final SortedMap<Integer, String> names;
我把它的英文注释和我的理解都写在代码注释中,应该可以清楚理解该属性的作用。至于为什么需要跳过 RowBounds 和 ResultHandler 这两个类型的参数,是因为前者用于设置 LIMIT 参数,后者用于设置结果集处理器,所以都不是真正意义上的参数,按照我的话说这两种类型的参数都是功能型的参数。
ParamNameResolver 在构造方法中实现了对参数列表的解析,如下:
public ParamNameResolver(Configuration config, Method method) {
// 获取参数类型列表
final Class<?>[] paramTypes = method.getParameterTypes();
// 获取参数列表上的注解列表
final Annotation[][] paramAnnotations = method.getParameterAnnotations();
final SortedMap<Integer, String> map = new TreeMap<>();
int paramCount = paramAnnotations.length;
// 遍历处理方法所有的参数
for (int paramIndex = 0; paramIndex < paramCount; paramIndex++) {
// 跳过 RowBounds 和 ResultHandler 类型参数
if (isSpecialParameter(paramTypes[paramIndex])) {
continue;
}
// 查找当前参数是否有 @Param 注解
String name = null;
for (Annotation annotation : paramAnnotations[paramIndex]) {
// 获取注解指定的参数名称
if (annotation instanceof Param) {
hasParamAnnotation = true;
name = ((Param) annotation).value();
break;
}
}
// 没有 @Param 注解
if (name == null) {
// 基于配置开关决定是否获取参数的真实名称
if (config.isUseActualParamName()) {
name = this.getActualParamName(method, paramIndex);
}
// 使用下标作为参数名称
if (name == null) {
// use the parameter index as the name ("0", "1", ...)
// gcode issue #71
name = String.valueOf(map.size());
}
}
map.put(paramIndex, name);
}
names = Collections.unmodifiableSortedMap(map);
}
整个过程概括来说就是遍历处理指定方法的参数列表,忽略 RowBounds 和 ResultHandler 类型的参数,并判断参数前面是否有 @Param 注解,如果有则尝试以注解指定的字符串作为参数名称,否则基于配置决定是否采用参数的真实名称作为这里的参数名,再不济就采用下标值作为参数名称。
考虑到会忽略 RowBounds 和 ResultHandler 两种类型的参数,但是属性 ParamNameResolver#names 对应的 key 又是递增的,所以就可能出现在以下标值作为参数名称时,参数名称与对应下标值不一致的情况。例如,假设有一个方法的参数列表为 (int a, RowBounds rb, int b),因为有 RowBounds 类型夹在中间,如果以下标值作为参数名称的最终解析结果就是 {0, "0"}, {2, "1"},下标与具体的参数名称不一致。
ParamNameResolver 中还有一个比较重要的方法 ParamNameResolver#getNamedParams,用于关联实参和形参列表,其中 args 参数是用户传递的实参数组,方法基于前面的参数列表解析结果将传递的实现与对应的方法参数进行关联,最终记录到 Object 对象中进行返回,实现如下:
public Object getNamedParams(Object[] args) {
// names 属性记录参数在参数列表中的下标和参数名称之间的对应关系
final int paramCount = names.size();
// 无参方法,直接返回
if (args == null || paramCount == 0) {
return null;
}
// 没有 @Param 注解,且只有一个参数
else if (!hasParamAnnotation && paramCount == 1) {
return args[names.firstKey()];
}
// 有 @Param 注解,或存在多个参数
else {
final Map<String, Object> param = new ParamMap<>();
int i = 0;
// 遍历处理参数列表中的非功能性参数
for (Map.Entry<Integer, String> entry : names.entrySet()) {
// 记录参数名称与参数值之间的映射关系
param.put(entry.getValue(), args[entry.getKey()]);
// 构造一般参数名称,即 (param1, param2, ...) 形式参数
final String genericParamName = GENERIC_NAME_PREFIX + (i + 1);
// 以“param + 索引”的形式再记录一次,如果 @Param 指定的参数名称已经是这种形式则不覆盖
if (!names.containsValue(genericParamName)) {
param.put(genericParamName, args[entry.getKey()]);
}
i++;
}
return param;
}
}
做了这么多的铺垫,是时候回来继续分析 MapperMethod 的核心方法 MapperMethod#execute 了。该方法的作用在于委托 SqlSession 对象执行方法对应的 SQL 语句,实现如下:
public Object execute(SqlSession sqlSession, Object[] args) {
Object result;
switch (command.getType()) {
case INSERT: {
// 关联实参与方法参数列表
Object param = method.convertArgsToSqlCommandParam(args);
// 调用 SqlSession#insert 方法执行插入操作,并对执行结果进行转换
result = this.rowCountResult(sqlSession.insert(command.getName(), param));
break;
}
case UPDATE: {
// 关联实参与方法参数列表
Object param = method.convertArgsToSqlCommandParam(args);
// 调用 SqlSession#update 方法执行更新操作,并对执行结果进行转换
result = this.rowCountResult(sqlSession.update(command.getName(), param));
break;
}
case DELETE: {
// 关联实参与方法参数列表
Object param = method.convertArgsToSqlCommandParam(args);
// 调用 SqlSession#delete 方法执行删除操作,并对执行结果进行转换
result = this.rowCountResult(sqlSession.delete(command.getName(), param));
break;
}
case SELECT:
// 返回值是 void 类型,且指定了 ResultHandler 处理结果集
if (method.returnsVoid() && method.hasResultHandler()) {
this.executeWithResultHandler(sqlSession, args);
result = null;
}
// 返回值为 Collection 或数组
else if (method.returnsMany()) {
result = this.executeForMany(sqlSession, args);
}
// 返回值为 Map 类型
else if (method.returnsMap()) {
result = this.executeForMap(sqlSession, args);
}
// 返回值为 Cursor 类型
else if (method.returnsCursor()) {
result = this.executeForCursor(sqlSession, args);
}
// 处理其它返回类型
else {
Object param = method.convertArgsToSqlCommandParam(args);
result = sqlSession.selectOne(command.getName(), param);
if (method.returnsOptional() // Optional 类型
&& (result == null || !method.getReturnType().equals(result.getClass()))) {
result = Optional.ofNullable(result);
}
}
break;
case FLUSH:
// 如果方法注解了 @Flush,则执行 SqlSession#flushStatements 方法提交缓存的批量更新操作
result = sqlSession.flushStatements();
break;
default:
throw new BindingException("Unknown execution method for: " + command.getName());
}
if (result == null && method.getReturnType().isPrimitive() && !method.returnsVoid()) {
throw new BindingException("Mapper method ‘" + command.getName()
+ " attempted to return null from a method with a primitive return type (" + method.getReturnType() + ").");
}
return result;
}
上述方法会依据具体的 SQL 语句类型分而治之。对于 INSERT、UPDATE,以及 DELETE 类型而言,会先调用 MethodSignature#convertArgsToSqlCommandParam 方法关联实参与方法形参,本质上是调用前面介绍的 ParamNameResolver#getNamedParams 方法。然后就是调用 SqlSession 对应的方法执行数据库操作,并通过方法 MapperMethod#rowCountResult 对结果进行类型转换。关于 SqlSession 相关方法的具体实现留到下一节针对性介绍。对于 SELECT 类型而言,则需要考虑不同的返回类型,分为 void、Collection、数组、Map、Cursor,以及对象几类情况,这里所做的都是对于参数或返回结果的处理,核心逻辑也都位于 SqlSession 中,在这一层面的实现都比较简单,就不再一一展开。对于 FLUSH 类型来说,官方文档的说明如下:
如果使用了这个注解,它将调用定义在 Mapper 接口中的
SqlSession#flushStatements方法。
具体的实现也就位于这里。
Executor 接口声明了基本的数据库操作,前面在介绍 SqlSession 时曾描述 SqlSession 是 MyBatis 框架对外提供的 API 接口,其中声明了对数据库的基本操作方法,而这些操作方法基本上都是对 Executor 方法的封装。Executor 接口定义如下:
public interface Executor {
ResultHandler NO_RESULT_HANDLER = null;
/** 执行数据库更新操作:update、insert、delete */
int update(MappedStatement ms, Object parameter) throws SQLException;
/** 执行数据库查询操作 */
<E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey cacheKey, BoundSql boundSql) throws SQLException;
<E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException;
/** 执行数据库查询操作,返回游标对象 */
<E> Cursor<E> queryCursor(MappedStatement ms, Object parameter, RowBounds rowBounds) throws SQLException;
/** 批量提交 SQL 语句 */
List<BatchResult> flushStatements() throws SQLException;
/** 提交事务 */
void commit(boolean required) throws SQLException;
/** 回滚事务 */
void rollback(boolean required) throws SQLException;
/** 创建缓存 key 对象 */
CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql);
/** 判断是否缓存 */
boolean isCached(MappedStatement ms, CacheKey key);
/** 清空一级缓存 */
void clearLocalCache();
/** 延迟加载一级缓存中的数据 */
void deferLoad(MappedStatement ms, MetaObject resultObject, String property, CacheKey key, Class<?> targetType);
/** 获取事务对象 */
Transaction getTransaction();
/** 关闭当前 Executor */
void close(boolean forceRollback);
/** 是否已经关闭 */
boolean isClosed();
/** 设置装饰的 Executor 对象 */
void setExecutorWrapper(Executor executor);
}
围绕 Executor 接口的类继承关系如下图,其中 CachingExecutor 实现类用于为 Executor 提供二级缓存支持。
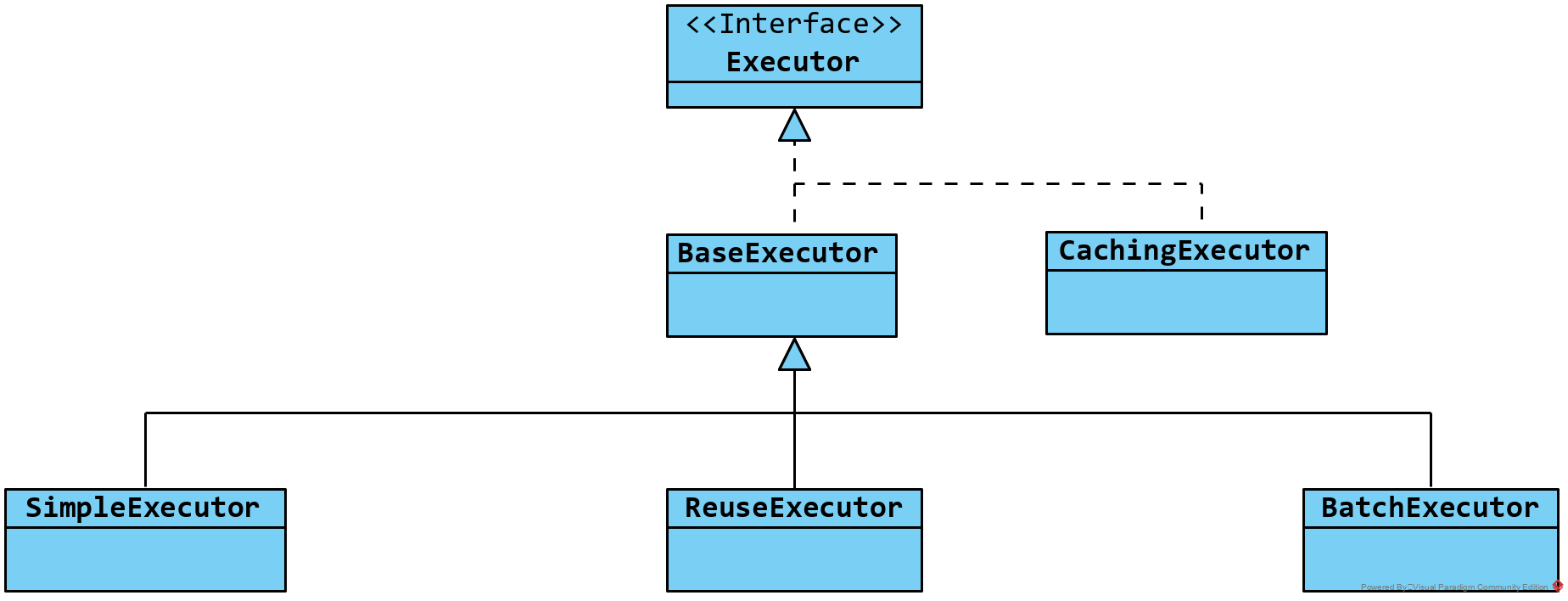
BaseExecutor 抽象类实现了 Executor 接口中声明的所有方法,并抽象了 4 个模板方法交由子类实现,这 4 个方法分别是:doUpdate、doFlushStatements、doQuery,以及 doQueryCursor。SimpleExecutor 派生自 BaseExecutor 抽象类,并为这 4 个模板方法提供了最简单的实现。ReuseExecutor 如其名,提供了重用的特性,提供对 Statement 对象的重用,以减少 SQL 预编译,以及创建和销毁 Statement 对象的开销。BatchExecutor 实现类则提供了对 SQL 语句批量执行的特性,也是针对提升性能的一种优化实现。
考虑到 Executor 在执行数据库操作时与缓存操作存在密切联系,所以在具体介绍 Executor 的实现之前我们先来了解一下 MyBatis 的缓存机制。
在谈论数据库架构设计时往往需要引入缓存的概念,数据库是相对脆弱且耗时的,所以需要尽量避免请求落库。在实际项目架构设计中,我们一般会引入 Redis、Memcached 这一类的组件对数据进行缓存,MyBatis 作为一个强大的 ORM 框架,也为缓存提供了内建的实现。前面我们在分析配置文件加载与解析时曾介绍过 MyBatis 缓存组件的具体实现,MyBatis 在数据存储上采用 HashMap 作为基本存储结构,并提供了多种装饰器从多个方面为缓存增加相应的特性。
本小节我们关注的是 MyBatis 在缓存结构方面的设计,MyBatis 缓存从结构上可以分为 一级缓存 和 二级缓存,一级缓存相对于二级缓存在粒度上更细,生命周期也更短。
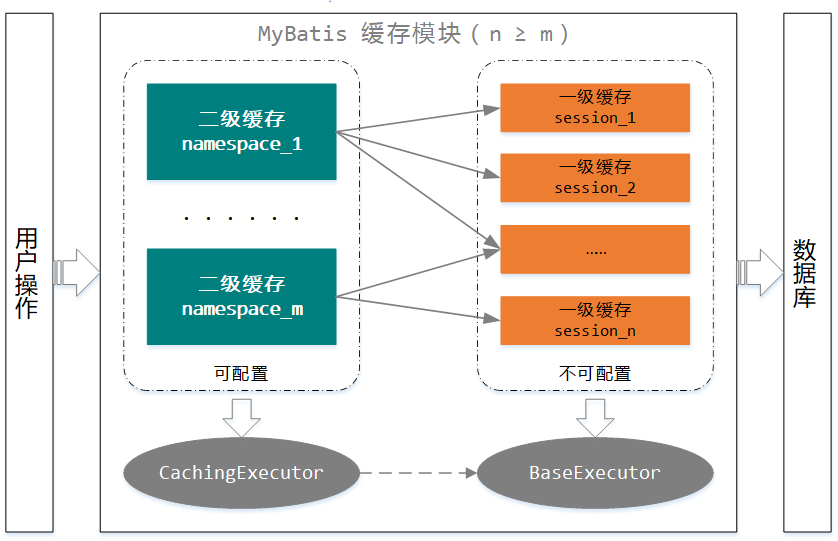
上图描绘了 MyBatis 缓存的结构设计,当我们发起一次数据库查询时,如果启用了二级缓存的话,MyBatis 首先会从二级缓存中检索查询结果,如果缓存不命中则会继续检索一级缓存,只有在这两层缓存都不命中的情况下才会查询数据库,最后会以数据库返回的结果更新一级缓存和二级缓存。
MyBatis 的 一级缓存是会话级别的缓存(生命周期与本次会话相同),当我们开启一次数据库会话时,框架默认会为本次会话绑定一个一级缓存对象。此类缓存主要应对在一个会话范围内的冗余查询操作,比如使用同一个 SqlSession 对象同时连续执行多次相同的查询语句。这种情况下每次查询都落库是没有必要的,因为短时间内数据库变化的可能性会很小,但是每次都落库却是一笔不必要的开销。一级缓存默认是开启的,且无需进行配置,即一级缓存对开发者是透明的,如果确实希望干预一级缓存的内在运行,可以借助于插件来实现。
对于二级缓存而言,默认也是开启的,MyBatis 提供了相应的治理选项,具体可以参考官方文档。二级缓存是应用级别的缓存,随着服务的启动而存在,并随着服务的关闭消亡。前面我们在分析 <cache/> 和 <cache-ref/> 标签时介绍了一个二级缓存会与一个具体的 namespace 绑定,并且支持引用一个已定义 namespace 缓存,即多个 namespace 可以共享同一个缓存。
本小节从整体结构上对 MyBatis 的缓存实现机制进行说明,目的在于对 MyBatis 的缓存有一个整体感知,关于一级缓存和二级缓存的具体实现,留到下面介绍分析 Executor 接口具体实现时穿插说明。
StatementHandler 接口及其实现类是 Executor 实现的基础,可以将其看作是 MyBatis 与数据库操作之间的纽带,实现了对 java.sql.Statement 对象的获取,以及 SQL 语句参数绑定与执行的逻辑。StatementHandler 接口及其实现类的类继承关系如下图所示:
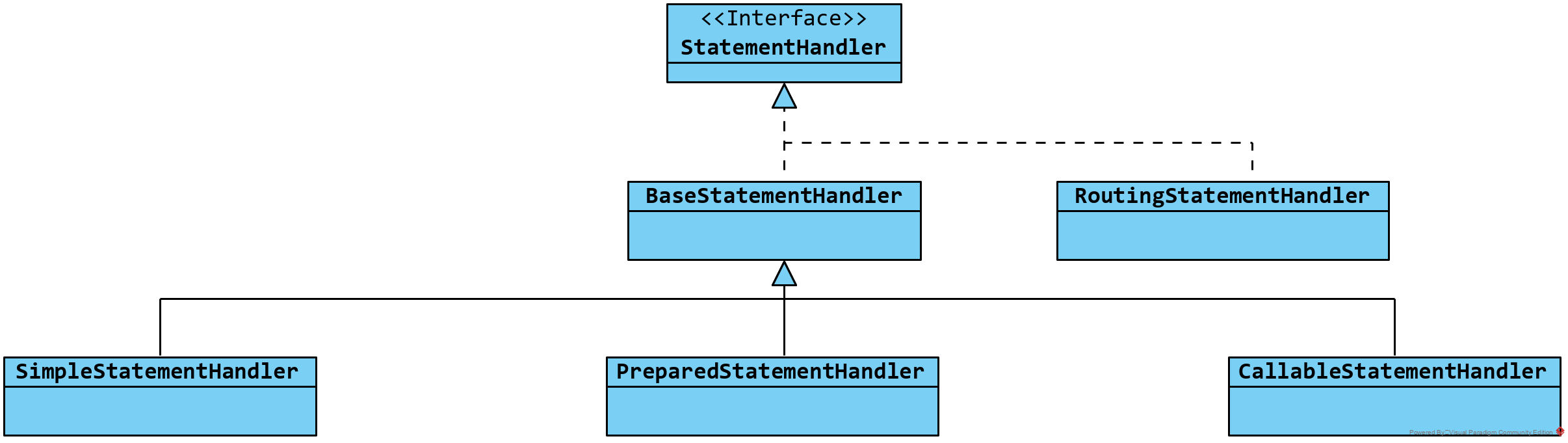
其中 BaseStatementHandler 中实现了一些公共的逻辑;SimpleStatementHandler、PreparedStatementHandler,以及 CallableStatementHandler 实现类分别对应 Statement、PreparedStatement 和 CallableStatement 的相关实现;RoutingStatementHandler 并没有添加新的实现,而是对前面三种 StatementHandler 实现类的封装,它会在构造方法中依据当前传递的 Statement 类型创建对应的 StatementHandler 实现类对象。
StatementHandler 接口定义如下:
public interface StatementHandler {
/** 获取对应的 {@link Statement } 对象 */
Statement prepare(Connection connection, Integer transactionTimeout) throws SQLException;
/** 绑定 Statement 执行 SQL 时需要的实参 */
void parameterize(Statement statement) throws SQLException;
/** 批量执行 SQL 语句 */
void batch(Statement statement) throws SQLException;
/** 执行数据库更新操作:insert、update、delete */
int update(Statement statement) throws SQLException;
/** 执行 select 操作 */
<E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException;
/** 执行 select 操作,返回游标对象 */
<E> Cursor<E> queryCursor(Statement statement) throws SQLException;
/** 获取对应的 SQL 对象 */
BoundSql getBoundSql();
/** 获取对应的 {@link ParameterHandler} 对象,用于参数绑定 */
ParameterHandler getParameterHandler();
}
首先来看一下 BaseStatementHandler 实现,该类中主要实现了获取 Statement 对象的逻辑,该类的属性定义如下:
protected final Configuration configuration;
protected final ObjectFactory objectFactory;
protected final TypeHandlerRegistry typeHandlerRegistry;
/** 处理结果集映射 */
protected final ResultSetHandler resultSetHandler;
/** 用于为 SQL 语句绑定实参 */
protected final ParameterHandler parameterHandler;
/** SQL 语句执行器 */
protected final Executor executor;
/** 对应 SQL 语句标签对象 */
protected final MappedStatement mappedStatement;
/** 封装 LIMIT 参数 */
protected final RowBounds rowBounds;
/** 可执行的 SQL 语句 */
protected BoundSql boundSql;
BaseStatementHandler 之于 StatementHandler#prepare 方法的实现如下:
public Statement prepare(Connection connection, Integer transactionTimeout) throws SQLException {
ErrorContext.instance().sql(boundSql.getSql());
Statement statement = null;
try {
// 从数据库连接中获取 Statement 对象,由子类实现
statement = this.instantiateStatement(connection);
// 设置超时时间
this.setStatementTimeout(statement, transactionTimeout);
// 设置返回的行数
this.setFetchSize(statement);
return statement;
} catch (SQLException e) {
this.closeStatement(statement);
throw e;
} catch (Exception e) {
this.closeStatement(statement);
throw new ExecutorException("Error preparing statement. Cause: " + e, e);
}
}
上述方法首先会调用 BaseStatementHandler#instantiateStatement 方法获取一个 Statement 对象,这是一个模板方法交由子类实现;然后对拿到的 Statement 对象设置超时时间和返回的行数属性。
BaseStatementHandler 中定义了 ParameterHandler 类型的属性,主要用于为包含 ? 占位符的 SQL 语句绑定实参。ParameterHandler 接口定义如下:
public interface ParameterHandler {
/** 获取输出类型参数 */
Object getParameterObject();
/** 为 SQL 语句绑定实参 */
void setParameters(PreparedStatement ps) throws SQLException;
}
其中,方法 ParameterHandler#getParameterObject 与存储过程相关,下面主要分析一下 ParameterHandler#setParameters 方法的实现。该方法用来为 SQL 语句绑定实参,具体操作等同于我们在直接使用 PreparedStatement 对象时注入相应类型的参数填充 SQL 语句。DefaultParameterHandler 是目前该接口的唯一实现,其 DefaultParameterHandler#setParameters 方法实现如下:
public void setParameters(PreparedStatement ps) {
ErrorContext.instance().activity("setting parameters").object(mappedStatement.getParameterMap().getId());
// 获取 BoundSql 中记录的参数映射关系列表
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
if (parameterMappings != null) {
// 遍历为 SQL 语句绑定对应的参数值
for (int i = 0; i < parameterMappings.size(); i++) {
ParameterMapping parameterMapping = parameterMappings.get(i);
// 忽略存储过程中的输出参数
if (parameterMapping.getMode() != ParameterMode.OUT) {
Object value; // 用于记录对应的参数值
// 获取参数名称
String propertyName = parameterMapping.getProperty();
// 获取对应的参数值
if (boundSql.hasAdditionalParameter(propertyName)) { // issue #448 ask first for additional params
value = boundSql.getAdditionalParameter(propertyName);
}
// 用户未传递实参
else if (parameterObject == null) {
value = null;
}
// 实参类型存在对应的类型处理器,即已经是最终的参数值
else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
value = parameterObject;
}
// 获取实参对象中对应的参数值
else {
MetaObject metaObject = configuration.newMetaObject(parameterObject);
value = metaObject.getValue(propertyName);
}
TypeHandler typeHandler = parameterMapping.getTypeHandler();
JdbcType jdbcType = parameterMapping.getJdbcType();
if (value == null && jdbcType == null) {
jdbcType = configuration.getJdbcTypeForNull();
}
try {
// 为 SQL 语句绑定对应的实参到 PreparedStatement 对象中
typeHandler.setParameter(ps, i + 1, value, jdbcType);
} catch (TypeException | SQLException e) {
throw new TypeException("Could not set parameters for mapping: " + parameterMapping + ". Cause: " + e, e);
}
}
}
}
}
上述实现整体上就是获取 BoundSql 对象记录的参数名称与 SQL 语句中参数的映射关系,然后获取参数名称对应的用户传递的实参设置到 PreparedStatement 对象中。如果使用过原生 JDBC 操作过数据库,对往 PreparedStatement 中填充实参的过程应该不难理解。
关于其余几个 StatementHandler 实现类的都比较简单,就不再展开。
结果集映射是 MyBatis 提供的一个强大且易用的特性,标签 <resultMap/> 用于配置数据库返回的结果集 ResultSet 与实体类属性之间的映射关系。前面我们分析了该标签的解析过程,本小节一起来探究一下 MyBatis 是如何基于这些配置执行结果集映射操作。
SQL 语句执行器 Executor 在调用具体的 StatementHandler 执行数据库查询操作时会针对数据库返回的结果集调用 ResultSetHandler 中相应方法执行结果集到实体类对象的映射处理。例如下面的代码块是 PreparedStatementHandler 在执行 PreparedStatementHandler#query 时的具体逻辑:
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
// 执行数据库操作
ps.execute();
// 调用 ResultSetHandler#handleResultSets 执行结果集映射
return resultSetHandler.handleResultSets(ps);
}
ResultSetHandler 接口定义了结果集映射所需要的方法,具体如下:
public interface ResultSetHandler {
/** 处理结果集,返回对应的结果对象集合 */
<E> List<E> handleResultSets(Statement stmt) throws SQLException;
/** 处理结果集,返回对应的游标对象 */
<E> Cursor<E> handleCursorResultSets(Statement stmt) throws SQLException;
/** 处理存储过程中的输出类型参数 */
void handleOutputParameters(CallableStatement cs) throws SQLException;
}
DefaultResultSetHandler 是目前 ResultSetHandler 接口的唯一实现。MyBatis 为结果集映射提供了灵活的配置,灵活的背后是强(复)大(杂)的映射解析过程,尤其是对于嵌套映射配置的情况。本小节力图对整个映射过程做一个比较详细的介绍,不过还是建议读者自己亲自 debug 跟踪一下整个执行过程。接下来我们围绕 ResultSetHandler#handleResultSets 方法对结果集映射处理过程进行分析,该方法实现如下:
public List<Object> handleResultSets(Statement stmt) throws SQLException {
ErrorContext.instance().activity("handling results").object(mappedStatement.getId());
/* 1. 处理普通映射情况 */
// 用于记录结果集映射的结果对象集合
final List<Object> multipleResults = new ArrayList<>();
int resultSetCount = 0;
// 获取第一个结果集
ResultSetWrapper rsw = this.getFirstResultSet(stmt);
// 获取之前解析得到的封装结果集映射配置的 ResultMap 对象集合
List<ResultMap> resultMaps = mappedStatement.getResultMaps();
int resultMapCount = resultMaps.size();
// 验证,如果结果集不为 null,则 resultMaps 也不能为空
this.validateResultMapsCount(rsw, resultMapCount);
// 遍历处理所有的结果集,基于结果集映射规则进行映射,并将结果记录到 multipleResults 集合中
while (rsw != null && resultMapCount > resultSetCount) {
// 获取一个配置的结果集映射标签 <resultMap/> 配置
ResultMap resultMap = resultMaps.get(resultSetCount);
// 依据结果集映射配置对结果集对象进行解析,并记录到 multipleResults 集合中
this.handleResultSet(rsw, resultMap, multipleResults, null);
// 获取下一个待处理的结果集
rsw = this.getNextResultSet(stmt);
// 清空 nestedResultObjects
this.cleanUpAfterHandlingResultSet();
resultSetCount++;
}
/*
* 2. 处理多结果集的情况
*
* 常见于存储过程,存在 <select resultSets="aaa,bbb"/> 类似的配置,
* 针对过程 1 未执行映射的结果集进行映射
*/
String[] resultSets = mappedStatement.getResultSets();
if (resultSets != null) {
while (rsw != null && resultSetCount < resultSets.length) {
// 获取 resultSet 配置名称对应的 ResultMapping 配置
ResultMapping parentMapping = nextResultMaps.get(resultSets[resultSetCount]);
if (parentMapping != null) {
// 获取对应的 <resultMap/> 标签配置
String nestedResultMapId = parentMapping.getNestedResultMapId();
ResultMap resultMap = configuration.getResultMap(nestedResultMapId);
// 执行结果集映射
this.handleResultSet(rsw, resultMap, null, parentMapping);
}
// 获取下一个待处理的结果集
rsw = this.getNextResultSet(stmt);
// 清空 nestedResultObjects
this.cleanUpAfterHandlingResultSet();
resultSetCount++;
}
}
// multipleResults.size() == 1 ? (List<Object>) multipleResults.get(0) : multipleResults
return this.collapseSingleResultList(multipleResults);
}
上述方法的执行过程可以分为两部分:普通结果集映射和多结果集映射。其中,多结果集映射一般用于存储过程,这是一个小众化的需求,所以大部分时候上述方法仅执行第一部分的逻辑。这一部分的执行过程如代码注释,其核心在于 DefaultResultSetHandler#handleResultSet 方法,该方法在第二部分中也会被调用,后面会针对该方法进行专门说明。
下面就第二部分的触发机制举例说明,能够执行到这里一般都伴随着存储过程,这里以 MySQL 数据库为例创建一个可以返回多结果集的存储过程,其中 t_blog 表和 t_post 表的定义参考官方文档示例:
CREATE PROCEDURE usp_demo(IN ID INT)
BEGIN
SELECT * FROM t_blog WHERE id = ID;
SELECT * FROM t_post WHERE id = ID;
END;
对应的映射配置如下:
<resultMap id="usp_demo_result_map" type="org.zhenchao.mybatis.entity.Blog">
<constructor>
<idArg column="id" javaType="int"/>
</constructor>
<result property="title" column="title"/>
<collection property="posts" ofType="org.zhenchao.mybatis.entity.Post" resultSet="posts">
<id property="id" column="id"/>
<result property="subject" column="subject"/>
</collection>
</resultMap>
<select id="uspDemo" resultSets="blogs,posts" resultMap="usp_demo_result_map" statementType="CALLABLE">
{CALL usp_demo(#{id, jdbcType=INTEGER, mode=IN})}
</select>
上述配置中,我们基于 resultSets 属性分别为对应的结果集命名,在执行该存储过程时会先映射 t_blog 数据表对应的结果集,映射的过程中遇到名为 posts 的结果集时,MyBatis 不会转去解析该结果集,而是会将该结果集记录到 DefaultResultSetHandler#nextResultMaps 属性中,等运行到第二部分时再对这些未解析的结果集统一进行映射处理。
上述过程中处理结果集映射的核心逻辑均位于 DefaultResultSetHandler#handleResultSet 方法中。该方法执行的主要逻辑在于判断当前是否指定了结果集处理器(即前面介绍过的 ResultHandler),如果没有指定则会创建一个默认的结果集处理器(默认采用 DefaultResultHandler 实现),然后调用 DefaultResultSetHandler#handleRowValues 方法执行映射逻辑。方法 DefaultResultSetHandler#handleResultSet 的实现如下:
private void handleResultSet(ResultSetWrapper rsw,
ResultMap resultMap,
List<Object> multipleResults,
ResultMapping parentMapping) throws SQLException {
try {
if (parentMapping != null) {
// 处理多结果集嵌套映射的情况
this.handleRowValues(rsw, resultMap, null, RowBounds.DEFAULT, parentMapping);
} else {
// 未指定 ResultHandler,构造默认的处理器
if (resultHandler == null) {
DefaultResultHandler defaultResultHandler = new DefaultResultHandler(objectFactory);
// 对结果集进行映射,并将映射结果记录到 DefaultResultHandler 对象中
this.handleRowValues(rsw, resultMap, defaultResultHandler, rowBounds, null);
// 获取保存在 DefaultResultHandler 对象中映射结果,记录到 multipleResults 中
multipleResults.add(defaultResultHandler.getResultList());
}
// 用户指定了 ResultHandler,使用该处理器进行处理
else {
this.handleRowValues(rsw, resultMap, resultHandler, rowBounds, null);
}
}
} finally {
// issue #228 (close resultsets)
this.closeResultSet(rsw.getResultSet());
}
}
方法 DefaultResultSetHandler#handleRowValues 会判断当前映射配置中是否存在嵌套映射的情况,如果存在嵌套映射则执行方法 DefaultResultSetHandler#handleRowValuesForNestedResultMap 方法处理嵌套结果集映射,否则执行 DefaultResultSetHandler#handleRowValuesForSimpleResultMap 方法处理简单的结果集映射。下面以简单结果集映射的过程进行分析,对于嵌套结果集映射的过程还是强烈建议大家去 debug 跟踪理解,单凭静态文字很难说清楚。
方法 DefaultResultSetHandler#handleRowValuesForSimpleResultMap 实现了对简单(相对于嵌套而言)结果集映射的处理逻辑。首先会基于 RowBounds 设置定位具体的处理行,MyBatis 对于 LIMIT 分页的处理是逻辑分页,而不是物理分页,即将符合条件的记录全部载入内存,然后在内存中进行截取,如果希望执行物理分页,可以自己编码插件,或者使用第三方插件,然后会遍历结果集中目标记录行对其逐一映射。
方法 DefaultResultSetHandler#handleRowValuesForSimpleResultMap 实现如下:
private void handleRowValuesForSimpleResultMap(ResultSetWrapper rsw,
ResultMap resultMap,
ResultHandler<?> resultHandler,
RowBounds rowBounds,
ResultMapping parentMapping) throws SQLException {
DefaultResultContext<Object> resultContext = new DefaultResultContext<>();
ResultSet resultSet = rsw.getResultSet();
// 针对设置了 RowBounds 定位指定的记录行
this.skipRows(resultSet, rowBounds);
// 检测是否可以继续对后续的记录行进行映射操作,可以的话就一直循环
while (this.shouldProcessMoreRows(resultContext, rowBounds) && !resultSet.isClosed() && resultSet.next()) {
// 确定具体使用的映射配置,如果配置了 <discriminator/> 标签则获取最终引用的 ResultMap,否则使用当前的 ResultMap 对象
ResultMap discriminatedResultMap = this.resolveDiscriminatedResultMap(resultSet, resultMap, null);
// 基于映射配置对当前记录行进行解析
Object rowValue = this.getRowValue(rsw, discriminatedResultMap, null);
// 保存映射得到的结果对象
this.storeObject(resultHandler, resultContext, rowValue, parentMapping, resultSet);
}
}
针对记录行的映射处理,方法首先会获取记录行对应的真正 ResultMap 映射配置对象,因为可能存在配置了 <discriminator/> 标签执行条件映射的情况,如果没有配置该标签则会使用当前实参对应的 ResultMap 对象。标签 <discriminator/> 的处理过程位于 DefaultResultSetHandler#resolveDiscriminatedResultMap 方法中,对照配置应该比较容易理解。获取到 ResultMap 映射配置对象之后,下一步就可以调用 DefaultResultSetHandler#getRowValue 方法对当前记录行执行映射处理,该方法实现如下:
private Object getRowValue(ResultSetWrapper rsw, ResultMap resultMap, String columnPrefix) throws SQLException {
final ResultLoaderMap lazyLoader = new ResultLoaderMap();
// 创建记录行映射结果对象
Object rowValue = this.createResultObject(rsw, resultMap, lazyLoader, columnPrefix);
// 如果结果对象不为 null,且没有对应的类型处理器
if (rowValue != null && !this.hasTypeHandlerForResultObject(rsw, resultMap.getType())) {
// 创建结果对象的 MetaObject 对象
final MetaObject metaObject = configuration.newMetaObject(rowValue);
// 标记是否成功映射任何一个属性
boolean foundValues = this.useConstructorMappings;
// 是否需要自动映射
if (this.shouldApplyAutomaticMappings(resultMap, false)) {
// 自动映射未在 <resultMap/> 标签中指定的列
foundValues = this.applyAutomaticMappings(rsw, resultMap, metaObject, columnPrefix) || foundValues;
}
// 映射在 <resultMap/> 标签中指定的列
foundValues = this.applyPropertyMappings(rsw, resultMap, metaObject, lazyLoader, columnPrefix) || foundValues;
foundValues = lazyLoader.size() > 0 || foundValues;
rowValue = foundValues || configuration.isReturnInstanceForEmptyRow() ? rowValue : null;
}
return rowValue;
}
方法首先会调用 DefaultResultSetHandler#createResultObject 方法创建实体结果对象,然后为该对象执行属性映射注入。对于未配置映射关系的属性会基于配置决定是否执行自动映射,对于明确指定映射关系的属性,则调用 DefaultResultSetHandler#applyPropertyMappings 方法执行映射处理,该方法的具体实现如下:
private boolean applyPropertyMappings(ResultSetWrapper rsw,
ResultMap resultMap,
MetaObject metaObject,
ResultLoaderMap lazyLoader,
String columnPrefix) throws SQLException {
// 获取所有指明了映射关系的列名集合
final List<String> mappedColumnNames = rsw.getMappedColumnNames(resultMap, columnPrefix);
boolean foundValues = false;
// 获取当前 ResultMap 包含的所有映射关系配置对象 ResultMapping 列表
final List<ResultMapping> propertyMappings = resultMap.getPropertyResultMappings();
// 遍历处理映射关系 ResultMapping 列表,执行映射过程
for (ResultMapping propertyMapping : propertyMappings) {
// 处理列前缀
String column = this.prependPrefix(propertyMapping.getColumn(), columnPrefix);
// 忽略嵌套的 ResultMap 映射
if (propertyMapping.getNestedResultMapId() != null) {
// the user added a column attribute to a nested result map, ignore it
column = null;
}
// 嵌套查询 | 配置了映射关系 | 多结果集
if (propertyMapping.isCompositeResult()
|| (column != null && mappedColumnNames.contains(column.toUpperCase(Locale.ENGLISH)))
|| propertyMapping.getResultSet() != null) { // 存在多结果集
// 执行映射,返回属性值
Object value = this.getPropertyMappingValue(
rsw.getResultSet(), metaObject, propertyMapping, lazyLoader, columnPrefix);
// issue #541 make property optional
final String property = propertyMapping.getProperty();
if (property == null) {
continue;
}
// 延迟加载的情况
else if (value == DEFERRED) {
foundValues = true;
continue;
}
if (value != null) {
foundValues = true;
}
// 设置属性值
if (value != null
|| (configuration.isCallSettersOnNulls() && !metaObject.getSetterType(property).isPrimitive())) {
// gcode issue #377, call setter on nulls (value is not ‘found‘)
metaObject.setValue(property, value);
}
}
}
return foundValues;
}
方法首先会获取当前结果集对应的映射关系配置和列名集合,然后遍历处理映射配置。针对嵌套查询、多结果集映射,以及普通映射的情况分而治之,这一过程位于 DefaultResultSetHandler#getPropertyMappingValue 方法中(实现如下)。针对嵌套查询的情况我们后面专门进行分析;对于多结果集的情况会将对应的结果集配置对象记录到 DefaultResultSetHandler#nextResultMaps 属性中,稍后会专门处理(即前面的第二部分代码);针对普通的映射则会基于 TypeHandler 获取属性对应的 java 类型值,也就是我们期望的值。
private Object getPropertyMappingValue(ResultSet rs,
MetaObject metaResultObject,
ResultMapping propertyMapping,
ResultLoaderMap lazyLoader,
String columnPrefix) throws SQLException {
// 嵌套查询
if (propertyMapping.getNestedQueryId() != null) {
return this.getNestedQueryMappingValue(rs, metaResultObject, propertyMapping, lazyLoader, columnPrefix);
}
// 多结果集情况,记录对应的 resultSet,后续处理
else if (propertyMapping.getResultSet() != null) {
this.addPendingChildRelation(rs, metaResultObject, propertyMapping);
return DEFERRED;
}
// 基于 TypeHandler 获取属性值
else {
final TypeHandler<?> typeHandler = propertyMapping.getTypeHandler();
final String column = this.prependPrefix(propertyMapping.getColumn(), columnPrefix);
return typeHandler.getResult(rs, column);
}
}
最后会调用 DefaultResultSetHandler#storeObject 方法将实体结果对象记录到 DefaultResultHandler#list 属性中,并在 DefaultResultSetHandler#handleResultSet 方法中调用 DefaultResultHandler#getResultList 方法拿到这些结果对象。
前面已经介绍了 Executor 接口以及相关的实现类继承关系,本小节将对这些执行器实现类逐一展开分析。
BaseExecutor 是一个抽象类,实现了 Executor 接口中声明的所有方法,并采用模板方法模式抽象出 4 个模板方法交由子类实现。需要强调的一点是,BaseExecutor 抽象类引入了一级缓存支持,在相应方法实现中增加了对一级缓存的操作,因此该抽象类的所有实现类都具备一级缓存的特性。BaseExecutor 抽象类的属性定义如下:
/** 事务对象 */
protected Transaction transaction;
/** 封装的 SQL 语句执行器 */
protected Executor wrapper;
/** 延迟加载队列 */
protected ConcurrentLinkedQueue<DeferredLoad> deferredLoads;
/** 缓存结果对象(一级缓存) */
protected PerpetualCache localCache;
/** 缓存存储过程输出类型参数(一级缓存) */
protected PerpetualCache localOutputParameterCache;
/** 全局唯一的配置对象 */
protected Configuration configuration;
/** 记录嵌套查询的层数 */
protected int queryStack;
/** 标记当前 Executor 是否已经关闭 */
private boolean closed;
下面针对一些比较复杂的方法实现展开说明,首先来看一下 BaseExecutor#update 方法实现(如下)。需要注意的是这里的 update 并不等同于 SQL 语句中的 UPDATE 操作,对于 Executor 而言数据库操作只包含 query 和 update 两大类,这里的 query 可以理解为 SQL 语句的 SELECT 操作,而 update 则对应着 SQL 语句中的 INSERT、UPDATE、DELECT 三类操作。
public int update(MappedStatement ms, Object parameter) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
// 先清空一级缓存
this.clearLocalCache();
// 执行更新操作,交由子类实现
return this.doUpdate(ms, parameter);
}
上述方法首先会判定当前 Executor 是否已被关闭,对于没有关闭的 Executor 会首先清空一级缓存,然后调用 BaseExecutor#doUpdate 模板方法,该方法由子类实现。
再来看一下 BaseExecutor#query 方法,该方法用于执行数据库查询操作。因为引入了一级缓存,所以这里的查询不是简单的直接查询数据库,而是会先查询一级缓存,只有在缓存不命中的情况下才会查询数据库,并利用数据库返回的结果对象更新一级缓存。该方法的实现如下:
public <E> List<E> query(MappedStatement ms,
Object parameter,
RowBounds rowBounds,
ResultHandler resultHandler) throws SQLException {
// 获取执行的 SQL 语句
BoundSql boundSql = ms.getBoundSql(parameter);
// 创建缓存 key
CacheKey key = this.createCacheKey(ms, parameter, rowBounds, boundSql);
// 调用重载的 query 方法执行查询操作
return this.query(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
public <E> List<E> query(MappedStatement ms,
Object parameter,
RowBounds rowBounds,
ResultHandler resultHandler,
CacheKey key,
BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
// 如果是非嵌套查询,且配置 <select flushCache="true"/> 要求执行该语句时清空一级缓存和二级缓存
if (queryStack == 0 && ms.isFlushCacheRequired()) {
// 清空一级缓存
this.clearLocalCache();
}
List<E> list;
try {
queryStack++;
// 尝试从一级缓存中获取结果
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
// 缓存名命中,针对存储过程特殊处理,获取缓存中保存的输出类型参数记录到实参对象中
if (list != null) {
this.handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
}
// 缓存不命中,查数据库并更新缓存,本质上调用的是 doQuery 方法
else {
list = this.queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
// 加载缓存中记录的嵌套查询的结果对象
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
this.clearLocalCache();
}
}
return list;
}
整个 BaseExecutor#query 方法的执行过程如上述代码注释。
方法 BaseExecutor#queryCursor 与 BaseExecutor#query 都是提供数据库查询操作,区别在于前者返回的是一个游标(Cursor)对象,而后者返回的是已经完成结果集映射的结果对象,游标需要等待用户真正操作时才会执行结果集映射的过程。
SimpleExecutor 提供了对 Executor 的简单实现,针对每一次数据库操作都会创建一个新的 Statement 对象,并在操作完毕之后进行关闭。SimpleExecutor 针对抽象类 BaseExecutor 中声明的方法实现流程都相同,下面以 SimpleExecutor#doQuery 方法为例进行分析,该方法的实现如下:
public <E> List<E> doQuery(MappedStatement ms,
Object parameter,
RowBounds rowBounds,
ResultHandler resultHandler,
BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
// 创建 StatementHandler 对象
StatementHandler handler = configuration.newStatementHandler(
wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
// 创建 Statement 对象并为 SQL 语句绑定实参
stmt = this.prepareStatement(handler, ms.getStatementLog());
// 执行数据库查询操作,以及结果集映射
return handler.query(stmt, resultHandler);
} finally {
// 关闭 Statement
this.closeStatement(stmt);
}
}
方法首先会基于 Configuration#newStatementHandler 创建对应的 StatementHandler 对象,这里实际上是采用了前面介绍的 RoutingStatementHandler 实现类依据入参进行创建。然后会调用 SimpleExecutor#prepareStatement 方法创建 Statement 对象,并为 SQL 语句绑定实参。接着执行具体的数据库查询操作,对于查询操作此时会执行结果集映射处理。最后关闭 Statement 对象。
方法 SimpleExecutor#prepareStatement 实现如下:
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
// 获取数据库连接
Connection connection = this.getConnection(statementLog);
// 获取 Statement 对象
stmt = handler.prepare(connection, transaction.getTimeout());
// 执行参数绑定
handler.parameterize(stmt);
return stmt;
}
其中 StatementHandler#prepare 方法的运行逻辑前面已经分析过。方法 StatementHandler#parameterize 执行了参数绑定的操作,该方法在 SimpleStatementHandler 中为空实现,毕竟对于 Statement 来说不支持设置参数;而对于 PreparedStatementHandler 和 CallableStatementHandler 而言都是调用了 ParameterHandler#setParameters 方法,该方法在前面已经专门分析过,不再重复介绍。
ReuseExecutor 提供了对 Statement 对象重用的机制,以减少该对象创建和销毁,以及 SQL 预编译所带来的开销。ReuseExecutor 类中定义了一个 ReuseExecutor#statementMap 属性(如下),其中 key 为 SQL 语句,value 为对应的 Statement 对象,以此实现对 Statement 对象的复用。
/** 缓存 Statement 对象,key 为对应的 SQL 语句(带有 ? 占位符) */
private final Map<String, Statement> statementMap = new HashMap<String, Statement>();
ReuseExecutor 中的方法实现也基本上沿用了同一套思路,仍然以 ReuseExecutor#doQuery 为例进行说明,该方法实现如下:
public <E> List<E> doQuery(MappedStatement ms,
Object parameter,
RowBounds rowBounds,
ResultHandler resultHandler,
BoundSql boundSql) throws SQLException {
Configuration configuration = ms.getConfiguration();
// 创建对应的 StatementHandler 对象
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
// 先尝试从缓存中获取当前 SQL 对应的 Statement 对象,缓存不命中则创建一个新的并缓存
Statement stmt = this.prepareStatement(handler, ms.getStatementLog());
// 执行数据库查询操作,以及结果集映射
return handler.query(stmt, resultHandler);
}
上述方法与 SimpleExecutor#doQuery 的区别在于在获取 Statement 对象时会先尝试从本地缓存中获取,如果缓存不命中则会创建一个新的 Statement 对象,并更新缓存,实现位于 ReuseExecutor#prepareStatement 方法中:
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
BoundSql boundSql = handler.getBoundSql();
String sql = boundSql.getSql();
// 获取缓存的 Statement 对象
if (this.hasStatementFor(sql)) {
stmt = this.getStatement(sql);
this.applyTransactionTimeout(stmt);
}
// 缓存不命中,新建一个 Statement 对象并缓存
else {
Connection connection = this.getConnection(statementLog);
stmt = handler.prepare(connection, transaction.getTimeout());
this.putStatement(sql, stmt);
}
// 绑定实参
handler.parameterize(stmt);
return stmt;
}
BatchExecutor 用于批量执行 SQL 语句。通常应用程序都是单行的执行 SQL 语句,但是某些场景下单行执行数据库操作是比较耗时的,比如需要远程执行数据库操作。因此,JDBC 针对 INSERT、UPDATE,以及 DELETE 操作提供了批量执行的支持。
BatchExecutor 是批量 SQL 语句执行器,其属性定义如下:
/** 缓存多个 {@link Statement} 对象,每个对象都对应多条 SQL 语句 */
private final List<Statement> statementList = new ArrayList<>();
/** 记录批处理的结果,每个 {@link BatchResult} 对应一个 {@link Statement} 对象 */
private final List<BatchResult> batchResultList = new ArrayList<>();
/** 当前执行的 SQL 语句 */
private String currentSql;
/** 当前操作的 {@link MappedStatement} 对象 */
private MappedStatement currentStatement;
下面探究一下 BatchExecutor 的批处理执行过程。首先来看一下 BatchExecutor#doUpdate 方法实现,该方法用于添加批处理 SQL 语句:
public int doUpdate(MappedStatement ms, Object parameterObject) throws SQLException {
final Configuration configuration = ms.getConfiguration();
// 基于参数创建对应的 StatementHandler 对象
final StatementHandler handler = configuration.newStatementHandler(
this, ms, parameterObject, RowBounds.DEFAULT, null, null);
final BoundSql boundSql = handler.getBoundSql();
final String sql = boundSql.getSql();
final Statement stmt;
// 当前执行的 SQL 语句与前一次执行的 SQL 语句(不包含实参)相同,且对应的 MappedStatement 对象也相同
if (sql.equals(currentSql) && ms.equals(currentStatement)) {
// 获取缓存的最后一个 Statement 对象,即前一次使用的 Statement 对象
int last = statementList.size() - 1;
stmt = statementList.get(last);
this.applyTransactionTimeout(stmt);
// 绑定实参
handler.parameterize(stmt);//fix Issues 322
BatchResult batchResult = batchResultList.get(last);
batchResult.addParameterObject(parameterObject);
}
// 当前执行的 SQL 语句与前一次执行的 SQL 语句不同
else {
Connection connection = this.getConnection(ms.getStatementLog());
// 获取一个新的 Statement 对象
stmt = handler.prepare(connection, transaction.getTimeout());
// 绑定实参
handler.parameterize(stmt); //fix Issues 322
// 记录本次执行的 SQL 语句和 MappedStatement 对象
currentSql = sql;
currentStatement = ms;
// 缓存新建的 Statement 对象
statementList.add(stmt);
batchResultList.add(new BatchResult(ms, sql, parameterObject));
}
// 基于 Statement#addBatch 方法添加批量 SQL 语句
handler.batch(stmt);
return BATCH_UPDATE_RETURN_VALUE;
}
上述方法中会判断当前执行的 SQL 模式(包含 ? 占位符的 SQL 语句)是否与前一次执行的相同,如果相同就会获取上次执行的 Statement 对象,并为之绑定实参;否则就会创建一个新的 Statement 对象,并记录本次执行的 SQL 模式,最后基于底层的数据库批处理方法 Statement#addBatch 添加批量 SQL 语句。由上述方法我们可以知道,对于连续同模式的批处理 SQL 操作会共享同一个 Statement 对象。
那么这些添加的批量 SQL 又是如何被执行的呢?这个过程位于 BatchExecutor#doFlushStatements 方法中,方法如下:
public List<BatchResult> doFlushStatements(boolean isRollback) throws SQLException {
try {
// 用于存储批量处理结果
List<BatchResult> results = new ArrayList<>();
if (isRollback) {
return Collections.emptyList();
}
// 遍历处理缓存的 Statement 集合
for (int i = 0, n = statementList.size(); i < n; i++) {
Statement stmt = statementList.get(i);
this.applyTransactionTimeout(stmt);
BatchResult batchResult = batchResultList.get(i);
try {
// 批量执行当前 Statement 蕴含的多条 SQL 语句,并记录每条 SQL 语句影响的行数
batchResult.setUpdateCounts(stmt.executeBatch());
MappedStatement ms = batchResult.getMappedStatement();
List<Object> parameterObjects = batchResult.getParameterObjects();
KeyGenerator keyGenerator = ms.getKeyGenerator();
if (Jdbc3KeyGenerator.class.equals(keyGenerator.getClass())) {
// 获取数据库生成的主键,并记录到 parameterObjects 中
Jdbc3KeyGenerator jdbc3KeyGenerator = (Jdbc3KeyGenerator) keyGenerator;
jdbc3KeyGenerator.processBatch(ms, stmt, parameterObjects);
} else if (!NoKeyGenerator.class.equals(keyGenerator.getClass())) { //issue #141
for (Object parameter : parameterObjects) {
keyGenerator.processAfter(this, ms, stmt, parameter);
}
}
// Close statement to close cursor #1109
this.closeStatement(stmt);
} catch (BatchUpdateException e) {
// ... 省略异常处理
}
// 记录封装当前 Statement 对象执行结果的 batchResult 到集合中
results.add(batchResult);
}
return results;
} finally {
// 关闭所有的 Statement 对象
for (Statement stmt : statementList) {
this.closeStatement(stmt);
}
currentSql = null;
statementList.clear();
batchResultList.clear();
}
}
方法会遍历我们在 BatchExecutor#doUpdate 中构造的 Statement 集合,分别执行集合中蕴含的 Statement 对象,并将执行的结果记录到 BatchResult 对象中(说明:在 BatchExecutor#doUpdate 方法中已经为每个 Statement 对象构造好了一个空的 BatchResult 对象,记录在 BatchExecutor#batchResultList 集合中),最后将 BatchResult 对象封装到集合中返回。因为都是数据库更新一类的操作,所以这里没有复杂的结果集映射,只需要记录每一条 SQL 语句执行所影响的行数即可。
由前面 Executor 的继承关系我们可以看到,CachingExecutor 相对于其它 Executor 实现来说似乎有其特别之处。CachingExecutor 直接实现了 Executor 接口,实际上它是一个 Executor 装饰器,用于为 Executor 提供二级缓存支持。该接口的属性定义如下:
/** 装饰的 {@link Executor} 对象 */
private final Executor delegate;
/** 用于管理当前使用的二级缓存对象 */
private final TransactionalCacheManager tcm = new TransactionalCacheManager();
其中第一个属性就是 CachingExecutor 具体修饰的 Executor 对象。我们来看一下第二个属性,TransactionalCacheManager 用来管理当前 CachingExecutor 对应的二级缓存对象,它的方法实现都比较简单,其中相对让人疑惑的是它的唯一一个属性:
/** key 为对应的 {@link CachingExecutor} 使用的二级缓存对象,value 为采用 {@link TransactionalCache} 装饰的二级缓存对象 */
private final Map<Cache, TransactionalCache> transactionalCaches = new HashMap<>();
该属性的 key 就是当前对应的二级缓存,而 value 则是对于该二级缓存对象采用 TransactionalCache 装饰后的对象。所以 key 和 value 本质上都映射到同一个缓存对象,只是 value 采用了 TransactionalCache 进行增强。TransactionalCache 也是一个缓存装饰器,在前面介绍缓存装饰器实现时特意留着没有说明,这里一起来分析一下。该装饰器的属性定义如下:
/** 被装饰的 {@link Cache} 对象(二级缓存) */
private final Cache delegate;
/** 是否在提交事务时清空缓存 */
private boolean clearOnCommit;
/** 用于缓存数据,当提交事务时会将其中的数据写入二级缓存 */
private final Map<Object, Object> entriesToAddOnCommit;
/** 缓存未命中的 key */
private final Set<Object> entriesMissedInCache;
对应的读缓存和写缓存操作,以及事务提交方法实现比较简单,读者可以自行阅读源码。
继续回来看 CachingExecutor 的实现,所有实现方法中只有 CachingExecutor#query 方法稍微复杂一些,该方法的实现如下:
public <E> List<E> query(MappedStatement ms,
Object parameterObject,
RowBounds rowBounds,
ResultHandler resultHandler) throws SQLException {
// 获取对应的 BoundSql 对象,并创建对应的 CacheKey
BoundSql boundSql = ms.getBoundSql(parameterObject);
CacheKey key = this.createCacheKey(ms, parameterObject, rowBounds, boundSql);
// 调用重载的 query 方法
return this.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
public <E> List<E> query(MappedStatement ms,
Object parameterObject,
RowBounds rowBounds,
ResultHandler resultHandler,
CacheKey key,
BoundSql boundSql) throws SQLException {
// 获取当前命名空间对应的二级缓存对象
Cache cache = ms.getCache();
// 判断是否启用了二级缓存
if (cache != null) {
// 依据配置决定是否清空二级缓存
this.flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
// 确保不是存储过程输出类型的参数
this.ensureNoOutParams(ms, boundSql);
// 查询二级缓存
@SuppressWarnings("unchecked")
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
// 二级缓存不命中,执行一级缓存查询,再不命中就查询数据库
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
// 缓存到 TransactionalCache#entriesToAddOnCommit 中
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
// 未启用二级缓存,则查询一级缓存,再不命中就查询数据库
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
正如我们一开始对于 MyBatis 缓存结构设计描绘的那样,上述方法首先在二级缓存中进行检索,如果二级缓存不命中则会执行被装饰的 Executor 对象的 Executor#query 方法。由前面的分析我们知道,Executor 的实现都自带一级缓存特性,所以接下去会查询一级缓存。只有在一级缓存也不命中的情况下,请求才会落库,并由数据库返回的结果对象更新一级缓存和二级缓存。
那么这里使用的二级缓存对象是在哪里创建的呢?实际上前面我们就定义说二级缓存是应用级别的,所以当应用启动时二级缓存就已经被创建了,这个过程发生在对映射文件进行解析时。在映射文件中我们会按照需要配置一定的 <cache/> 和 <cache-ref> 标签,而在解析 <cache/> 标签时会调用 MapperBuilderAssistant#useNewCache 方法创建对应的二级缓存对象。
本文对 MyBatis 执行 SQL 语句所涉及到的各个方面做了一个比较详细的分析。当我们基于 MyBatis 触发一次数据库操作时,首先需要开启一次数据库会话,然后获取目标 Mapper 接口,并调用相应的 Mapper 方法执行数据库操作,最后拿到操作结果。MyBatis 在这中间基于动态代理机制实现了 SQL 语句的检索、参数绑定、数据库操作,以及结果集映射等一系列操作,并引入了缓存机制优化数据库查询性能。
回过头来看,MyBatis 的整体设计还是非常巧妙的,却也很是直观且简单,是对动态代理机制的典型应用,其设计思想和对于设计模式的应用值得我们在实际开发中借鉴。
本文是 MyBatis 源码解析系列的最后一篇文章,由于时间仓促,再加上作者水平有限,整个系列的文章中不免有错误之处,还望批评指正!
标签:his params 获取 而不是 value 思路 集中 error rom
原文地址:https://www.cnblogs.com/1156184981651a/p/13195540.html