标签:mic load 传输 标记 忽略 情况下 embed 探索 获得
用于多领域端到端任务导向对话系统的动态融合网络
最近的研究表明,大多数神经模型都依赖于大型训练数据,这些数据仅可用于一定数量的任务域,例如导航和调度。这使得难以用有限的标好的数据进行新领域的扩展。但是,关于如何有效地使用来自所有域的数据来提高每个域以及未知域的性能的研究相对较少。为此,我们研究了可以显式利用领域知识并引入共享-专用网络以学习共享和特定知识的方法。此外,我们提出了一种新颖的动态融合网络(DF-Net),该网络可自动利用目标域与每个域之间的相关性。结果表明,我们的模型在多域对话中的表现优于现有方法,从而给出了文献中的最新技术。此外,在训练数据很少的情况下,我们的性能比以前的最佳模型平均高13.9%。
面向任务的对话系统帮助用户实现特定目标,例如餐厅预订或导航查询。近年来,文献中的端到端方法通常采用序列到序列(Seq2Seq)模型来产生对话历史的响应。以图1中的对话为例,为了回答驾驶员对“加油站”的查询,端到端对话系统会根据查询和相应的知识库(KB)直接生成系统响应。

图1
尽管端到端模型具有良好的性能,但它们依赖大量标记的数据,这限制了它们对新域和扩展域的实用性。实际上,我们无法为每个新域收集丰富的数据集。因此,重要的是考虑能够有效地将知识从具有足够标记数据的源域转移到具有有限标记数据或很少标记数据的目标域的方法。
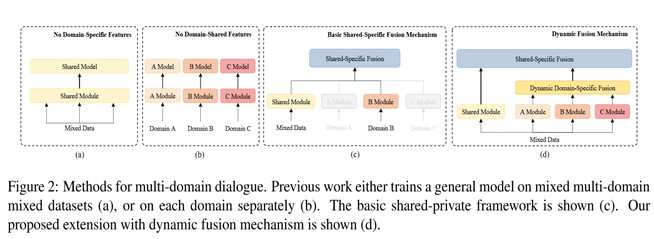
现有的方法可以被分为两类:
如图 (a) 所示,第一种是简单将各种领域的数据混合起来训练,这样的方法可以隐式地提取共享的特性,但是不能有效地捕获领域特定的知识。
第二种如图(b)所示,模型在每个领域上单独训练,这样能够更好的捕获领域特定的知识,但是却忽略了领域间共享的知识。
我们考虑通过显式地建模领域之间的知识联系来解决现有工作的局限性。
有一种简单的基线模型是将领域共享的和领域特有的特征在一个共享-私有框架中进行合并,图(c),它包括用于捕获域共享特性的共享模块和用于每个域的私有模块,该方法明确区分了共享知识和私有知识。然而这种框架依然存在两个问题:1)给定一个数据量很少的新领域,私有模块很难有效地提取出相应的领域知识;2)该框架忽略了跨特定领域子集的细粒度相关性(例如:schedule领域与navigation领域的相关性要超过weather领域)
为了解决上述问题,文中提出了一种动态融合网络,如图(d)所示,对比于共享-私有模型,该模型进一步引入动态融合模块显式地捕捉领域之间的相关性。特别地,利用一个门控机制自动寻找当前输入和所有的领域特定模型之间的相关性,以便为每个领域分配权重用于提取知识。编码器和解码器以及基于特征查询知识的记忆模块都用上了这种机制。另外,给定一个几乎没有训练数据的新领域时,我们扩展的动态融合框架可以利用细粒度的知识来获得所需的精度,这使得模型仍然可以充分适应现有域,这是基线模型做不到的。
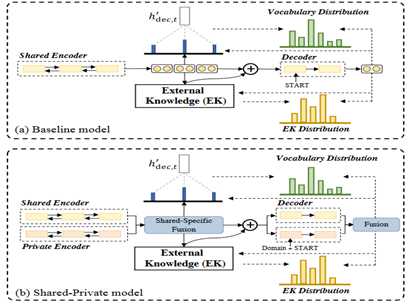
模型是基于seq2seq对话生成模型的,如下图(a)所示,为了显式集成领域认知,我们首先提出使用shared-private框架来学习共享的和相应的领域特定特征,如图(b)。
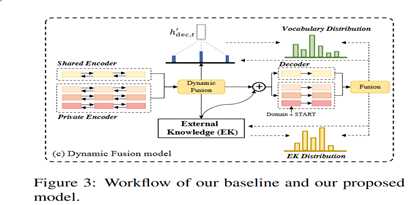
接下来,我们提出了使用一个动态融合网络来动态地利用所有领域之间的相关性以进行细粒度的知识传输,如图(c)。此外,我们还使用了对抗性训练来促使共享模块生成领域共享特征。
2.1 seq2seq对话生成
文中将seq2seq任务型对话生成任务定义为根据输入对话历史 X 和知识库 B 来寻找系统响应 Y。不同于典型的seq2seq模型,任务型对话系统中成功的会话依赖于精确的知识库查询。文中采用了global-to-local记忆指针机制(GLMP)来查询知识库中的实体。外部知识记忆用来存储知识库 B 和对话历史 X。KB 记忆是为知识库设计的,而对话记忆是用于直接复制历史词汇。外部知识记忆中的实体以三元组的形式表示,并存储在记忆模块中, 该模块可以表示为M= [B;X] =(m1,...,mb+T)。对于一个K-hop 记忆网络,外部知识是由一组可训练的embedding矩阵C=组成。为了增加模型和知识模块的交互,模型在编码和解码的过程中都会进行知识库查询。
在编码器中查询知识
使用最后一个隐层状态作为初始化的查询向量
在解码器中查询知识
使用一个 sketch 标签来表示相同类型的所有可能的slot 类型(例如,@address表示所有的 Address)。
2.2 shared-private 编解码器模型
之前提到的模型在混合的多领域数据集上进行训练,模型的参数在所有领域都是共享的,作者将这种模型称之为共享编解码器模型。这里作者提出了一个使用shared-private框架,包括一个共享的编解码器用于捕捉领域共享的特征和一个 private模型用于给每个领域显式捕捉领域特定的特征。每个实例 X 既要经过共享的编解码器也要经过相应的私有的编解码器。
增强的编码器
给定一个实例以及它所属的领域,shared-private编解码器产生一个编码序列,包含共享的和来自相应编码器的领域特定表示:
增强的解码器
2.3 用于查询知识的动态融合网络
上述的 shared-private 框架可以捕捉到相应的专有特征,但是却忽视了跨领域的子集中的细粒度相关性。作者进一步提出一个动态融合层来显式利用所有的领域知识,如图所示。从任意领域给定一个实例,作者首先将它放入多个私有的编-解码器中,以从所有领域中获得领域特定的特征。接下来,所有的领域特定的特征被一个动态领域特定特征融合模块所融合,然后通过shared-specific特征融合获得 shared-specific 特征。
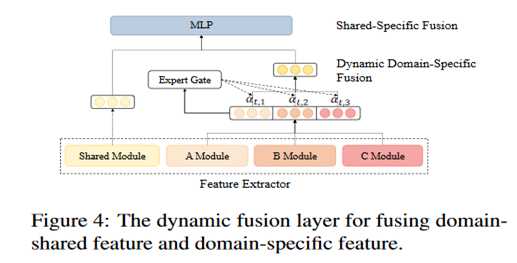
动态领域特定特征融合
给定所有领域的特征,一种 Mixture-of-Experts机制被用于在编码器和解码器中动态整合当前输入的所有的领域特定知识。
接下来详细描述如何融合解码的时间步t,编码器的融合过程也一样:expert gate E在第 t 个解码时间步给定所有的领域特征表示当作输入,输出一个 softmax 分数代表当前输入的token 于每个领域之间的相关程度。通过一个简单的前馈层来实现:
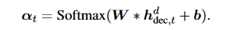
最终的领域特定的特征向量混合了所有领域的输出,取决于 expert gate 的权重.
以解码器为例,在训练期间,作者使用交叉熵损失作为监督信号让 expert gate来预测响应中每个 token 的领域,expert gate 输出的被多个专用解码器视为第 t 个 token 的领域概率分布预测值。因此,领域预测越准确,expert 得到的结果越正确.
Shared-specific 特征融合
用shprivate 操作来融合共享的和最终的 domain-specific 特征:
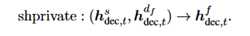
3.1 数据集
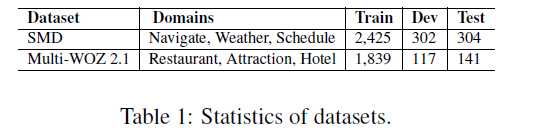
作者为SMD数据集和 Multi-WOZ 2.1 数据集构造了相应的 KB,数据的统计信息如图所示:
3.2 实验设置
Embedding 和 LSTM 隐层单元的维度为 128,dropout 从 {0.1,0.2}中选择,batch size 从{16,32}中选择,在框架中,作者还采用了权重类型技巧,优化器为 Adam。
3.3
Baselines
作者对比了他的模型和sota baselines:
3.3 实验结果
作者使用 BLEU 和 Micro Entity F1 作为评估指标。结果如图表所示:
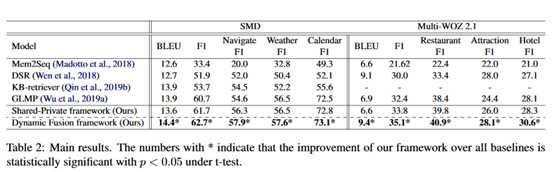
结论:1)基础的 Shared-Private框架表现要好于之前最好的模型 GLMP,这意味着领域共享和领域特有的特征结合起来之后比起仅使用隐式领域共享特征的模型,它能够更好的增强每个领域的表现;2)作者提出的框架在两个对领域任务型对话数据集上都获得了最好的表现。
3.4 实验分析
作者在 SMD 数据集上从几个方面研究了模型的强度。首先通过几个消融实验来分析不同部件的效果,接下来,构造了领域适应实验来验证模型在一个数据量很少或者没有的情况下模型的迁移能力。此外,作者还提供了动态融合层的可视化和实例研究,以便更好地理解模块如何影响和促进性能。
1. 消融实验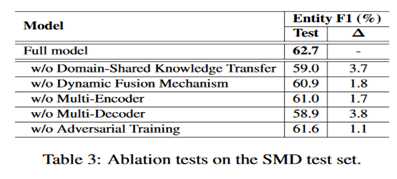
消融实验结果如表中所示,1)w/o Domain-Shared Knowledge Transfer 代表除去领域共享特征,仅使用领域特定特征来生成;2)w/o Dynamic Fusion Mechanism代表仅简单将所有的领域特定特征加起来,而不是使用 MOE 机制来动态融合;3)w/o Multi-Encoder 代表移除多编码器模块,只使用一个共享编码器;4)w/o Multi-Decoder 代表移除多解码器模块;5)w/o Adversarial Training 代表移除对抗训练的实验设置;
2. 领域适应
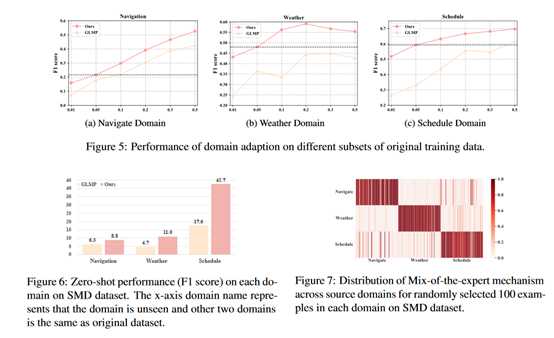
低资源设置 如图5所示。我们可以发现:(1)我们的框架在原始数据集的所有比率上均优于GLMP基线。当数据仅占原始数据集的5%时,我们的框架在所有域上的平均表现均优于GLMP 13.9%。 (2)与在某些领域使用50%训练数据集的GLMP相比,使用5%训练数据集训练的框架可以实现相当甚至更好的性能。这意味着我们的框架有效地从其他领域转移了知识,从而为低资源的新域实现了更好的性能。
零射击设置 特别地,在没有看到域的情况下,我们进一步评估了零触发设置下域适应能力的性能。从训练集中随机删除一个域,而其他域数据保持不变以训练模型。在测试过程中,看不见的域输入使用MoE来自动计算其他域与当前输入之间的相关性并获得结果。结果如图6所示,我们可以看到我们的模型在三个域上的性能明显优于GLMP,这进一步证明了我们框架的可移植性
3 案例学习
此外,我们为Navigationdomain及其相应的专家门分布提供了一种情况。 案例是在导航域中使用5%的训练数据生成的,而其他两个域的数据集保持不变,这可以更好地显示其他两个域如何将知识转移到低资源域。 如图8所示,计划域的专家值比天气域大,这表明计划对天气的贡献更大。在进一步的探索中,我们发现导航和计划域中都出现了“位置”和“集合”两个词, 这表明日程安排与导航比天气更紧密,这表明我们的模型成功地从最近的领域转移了知识

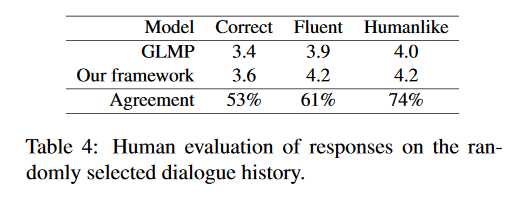
4 人类评估
我们对我们的框架和其他基准模型进行人工评估。 我们随机产生了100个响应。 这些响应基于对SMD测试数据的不同对话历史记录。 以下文等。 (2018)和Qin等。 (2019b),我们聘请了人类专家,并要求他们根据正确性,流畅性和人的相似性以1到5的等级来判断回答的质量。结果如表4所示。我们可以看到我们的框架在所有指标上均优于GLMP, 这与自动评估是一致的。
在本文中,我们建议使用共享专用模型来研究多域对话框的显式建模域知识。 此外,提出了一种动态融合层来动态捕获目标域和所有源域之间的相关性。 在两个数据集上的实验表明了所提出模型的有效性。 此外,我们的模型可以在几乎没有注释数据的情况下快速适应新领域。
Dynamic Fusion Network for Multi-Domain End-to-end Task-OrientedDialog
标签:mic load 传输 标记 忽略 情况下 embed 探索 获得
原文地址:https://www.cnblogs.com/xuechengmeigui/p/13206629.html