标签:适用于 效率 inf 提升性能 总结 标准 内存数据库 客服 tps
今天给大家分享第四范式在推荐系统大规模特征工程与Spark基于LLVM优化方面的实践,主要包括以下四个主题。推荐系统在新闻推荐、搜索引擎、广告投放以及最新很火的短视频App中都有非常广阔的应用,可以说绝大部分互联网企业和传统企业都可以通过推荐系统来提升业务价值。
我们对常见的推荐系统架构进行分层,离线层(Offline layer)主要负责处理存在HDFS的大规模数据进行预处理和特征抽取,然后使用主流的机器学习训练框架进行模型训练并且导出模型,模型可以提供给在线服务使用。流式层(Stream layer)我们也称近线层,是介于离线和在线的中间层,可使用流式计算框架如Flink进行近实时的特征计算和生成,结果保存在NoSQL或者关系型数据库中给在线服务使用。在线层(Online layer)就包括了与用户交互的UI以及在线服务,通过实时的方式提取流式特征和使用离线模型进行预估,实现推荐系统在线的召回和推荐功能,预估结构和用户反馈也可以通过事件分发器写会流失计算的队列以及离线的Hadoop存储中。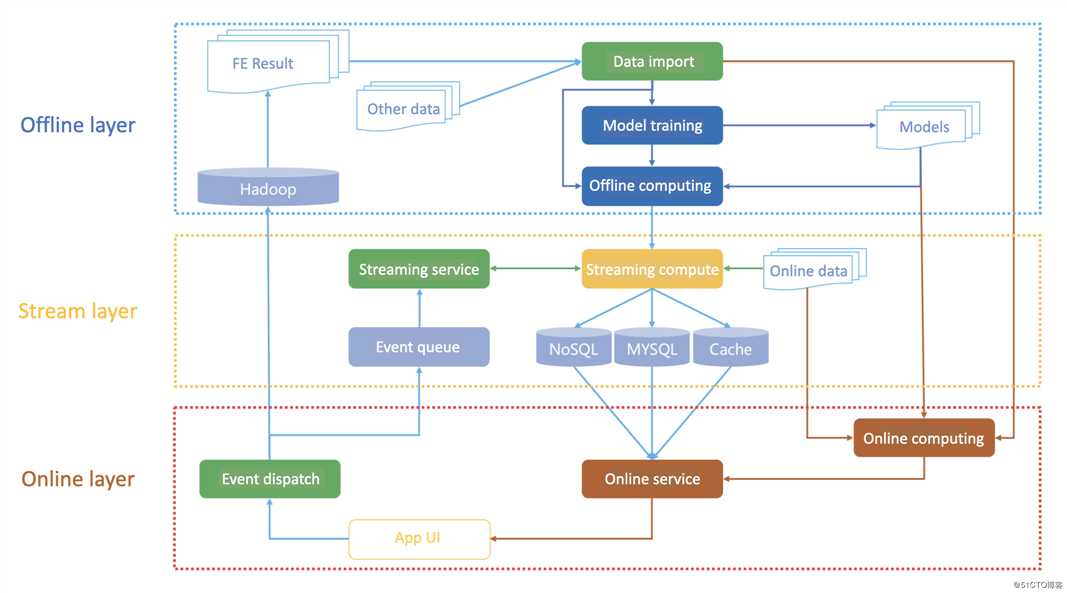
本次分享重点会介绍离线层的优化,在大规模的推荐系统中离线存储的数据可能到PB级,常用的数据处理有ETL(Extract, Transform, Load)和FE(Feature extraction),而编程工具主要是SQL和Python,为了能够处理大规模数据一般使用Hadoop、Spark、Flink这样的分布式计算框架,其中Spark因为同时支持SQL和Python接口在业界使用最广。
Spark刚发布了3.0版本,无论是性能还是易用性都有很大的提升,其中相比于Hadoop MapReduce就有一百倍以上的性能加速,能够处理PB级数据量,支持水平拓展的分布式计算和自动Failover,支持易用的SQL、Python、R以及流式编程(Spark Streaming)、机器学习(MLlib)和图计算(GraphX)接口,对于推荐系统来说内置的推荐算法模型也可以做到开箱即用。
业界使用Spark作为推荐系统离线数据处理框架的场景非常多,例如使用Spark来加载分布式数据集,使用Spark UDF和SQL来做做数据预处理和特征选择,使用MLlib来训练召回、排序模型。但是,在上线部分Spark就支持不了了。主要原因是Spark没有对long running service的支持,而driver-executor的架构只适合做离线的批处理计算,在Spark 3.0中推出了Hydrogen可以支持一些预先运行的task但也只适用于离线计算或者模型计算阶段,对于实时性要求更高但在线服务支持不好。Spark RDD编程接口也是适合于迭代计算,我们总结下Spark的优势主要是能批量处理大规模数据,而且支持标准的SQL语法,劣势是没有在线预估服务的支持,因此也不能保证离线和在线服务的一致性,对于AI场景的特征计算也没有特别多的优化。
第四范式自研的FESQL服务,是在SparkSQL的基础上,提供了针对AI场景特征抽取计算的性能优化,还从根本上解决了离线在线一致性的问题。传统的AI落地场景是先在离线环境通过机器学习训练框架建模导出AI模型文件,然后由业务开发者来搭建在线服务,由于离线使用了SQL、Python进行了数据预处理和特征抽取等功能,在线需要开发一套与之匹配的在线处理框架,两套不同的计算系统在功能上容易出现离线在线不一致的情况,甚至离线建模时就可能使用穿越特征导致在线部分无法实现。而FESQL的方案是使用统一的SQL语言,除了标准的SQL支持外还拓展了针对AI场景的计算语法以及UDF定义,离线和在线使用同一套高性能LLVM JIT代码生成,保证了无论是离线还是在线都执行相同的计算逻辑,从而保证机器学习中离线和在线的特征一致性。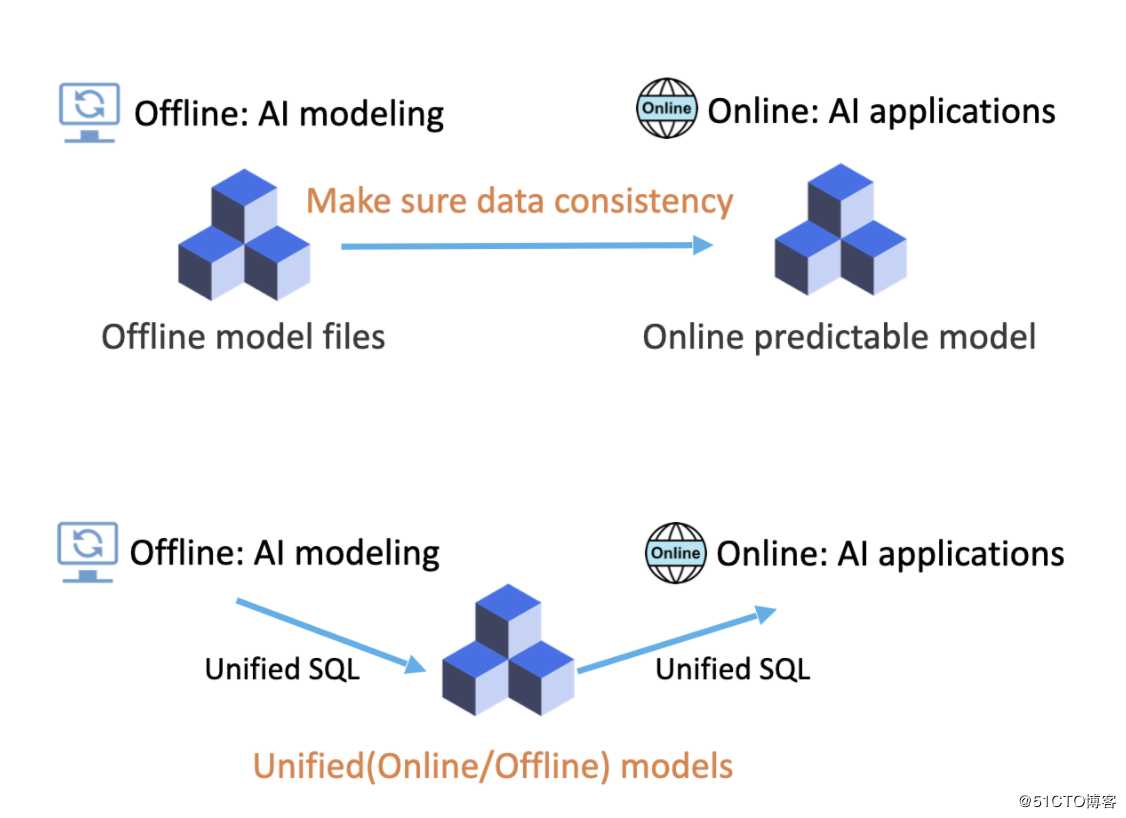
为了支持SparkSQL中无法支持的在线功能,FESQL在线部分实现一个自研的高性能全内存时序数据库,相比于其他通用的key-value内存数据库如Redis、VoltDB,在时序特征的存储上读写性能以及压缩容量都有很大的提升,并且比传统的时序数据库如OpenTSDB能够更好地满足在线服务超低延时的需求。而离线部分仍然借助Spark的分布式任务调度功能,只是在SQL解析和执行上使用了更高效的native执行引擎,通过C++实现的LLVM JIT代码生成技术,可以针对morden CPU使用更多intrinsic function实现向量化等指令集优化,甚至是特有硬件如FPGA、GPU等加速。通过同一套SQL执行引擎等优化,不仅提升了离线和在线的执行效率,还能从功能上保证离线建模的特征抽取方案迁移到在线服务而不需要额外的开发和比对工作。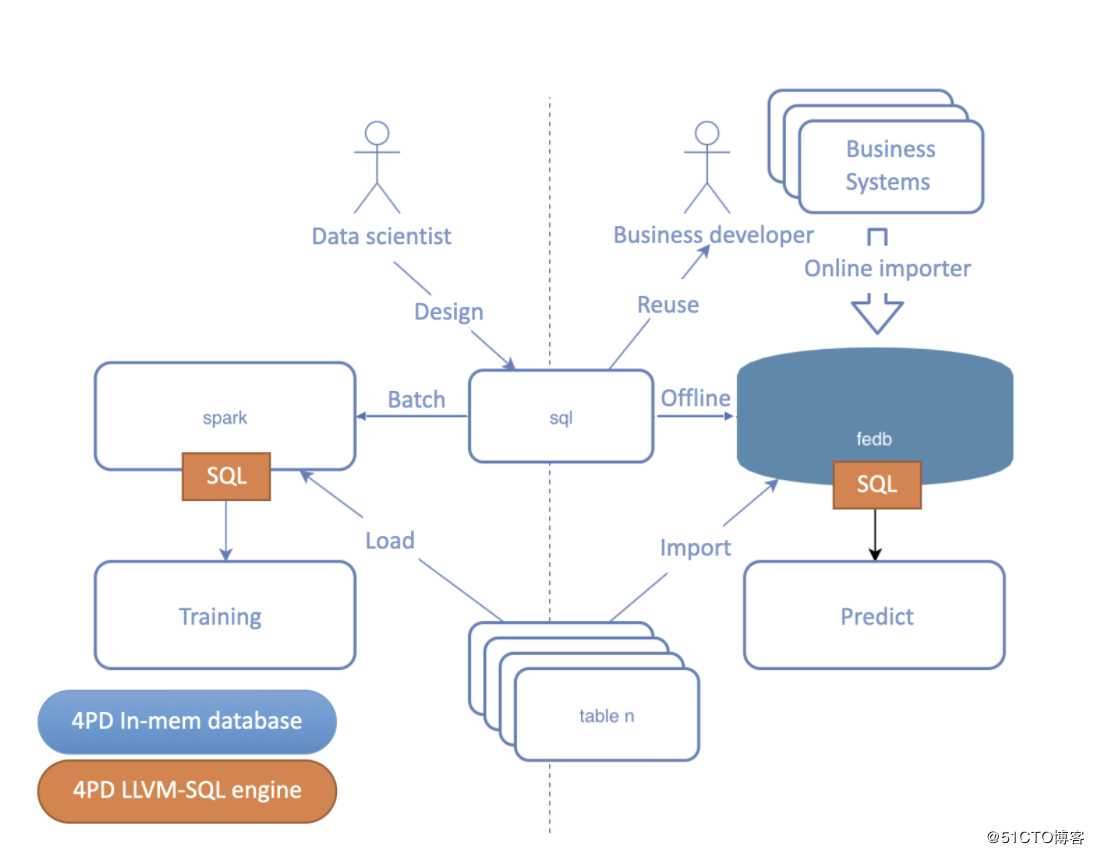
FESQL性能上对比同样是全内存的商业产品memsql,在针对机器学习的时序特征抽取场景中,同一个SQL在性能上相比memsql也有巨大的提升。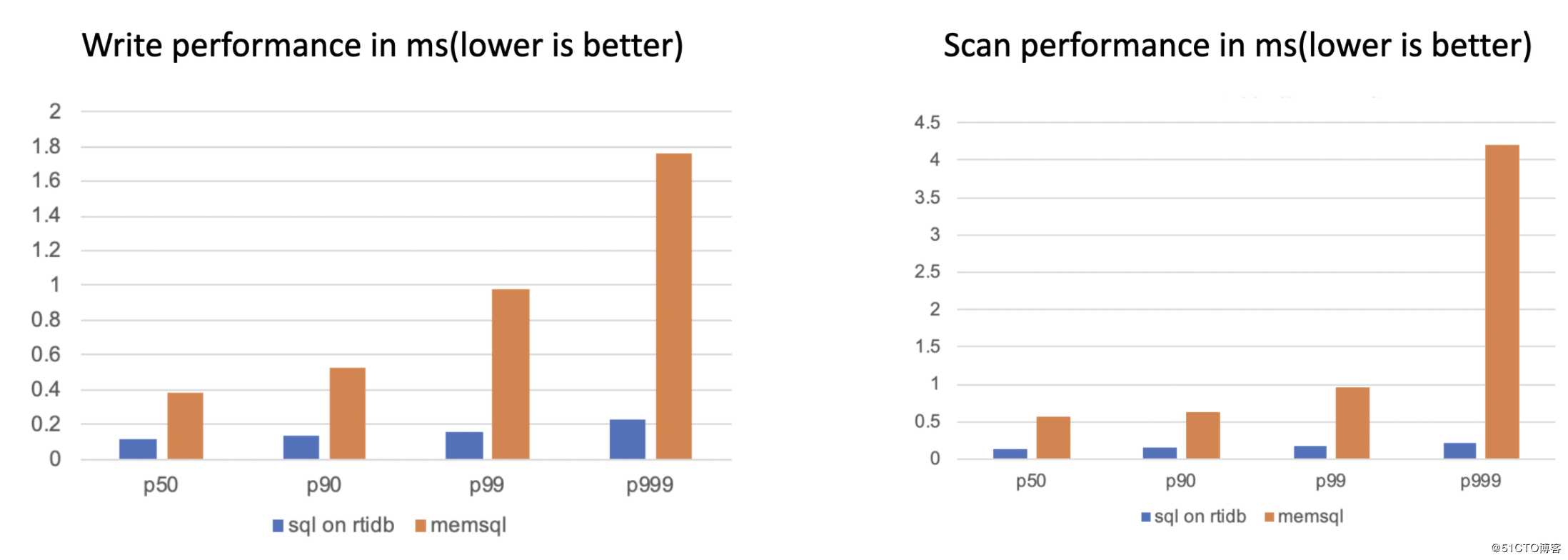
从Spark 2.0开始,开始使用了Catalyst和Tungsten项目对Spark以及SQL任务有了很大的性能优化。Catalyst通过对SQL语法进行词法解析、语法解析,生成了unresolved的抽象语法树数据结构,并且对抽象语法树进行了数十次的优化pass,生成的最终物理计划可以比普通SQL解析后直接执行快数十倍。Tungsten项目则是通过用Java unsafe接口实现了内部数据结构的堆外管理,在很大程度上降低了JVM GC的overhead,并且对多个物理节点、多个表达式可以实现whole stage codegen,直接生成Java bytecode并使用Janino内存编译器进行编译优化,生成的代码避免过多虚函数调用、提高CPU cache命中率,性能上比传统的火山模型解释执行快几倍并且非常接近由高级程序员手写Java代码的性能了。
那么Spark的Catalyst和Tungsten是否已经足够完美呢?我们认为还不够,首先Spak是基于Scala、Java实现的,就是是PySpark也是通过socket与JVM相连调用Java函数,因此所有代码都是在JVM上执行,这样不可避免就要接受JVM和GC的overhead,而且随着CPU硬件和指令集的更新要通过JVM来使用新硬件特性还是比较困难的,更不用说越来越流行的FPGA和GPU,对于高性能的执行引擎使用更底层的C或C++实现可以代码更好的性能提升。对于可并行的数据计算任务,使用循环展开等优化手段可以成倍地提升性能,对于连续的内存数据结构还可以做更多向量化优化以及利用上GPU数千个计算核并行优化,这些在目前最新的Spark 3.0开源版中仍不支持。而且在机器学习场景中常用SQL的window函数来计算时序特征,这部分功能对应Spark的物理节点WindowExec居然没有实现whole stage codegen,也就是说在做多表达式的划窗计算时无法使用Tungsten的优化,通过解释执行来计算每个特征,这样性能甚至比用户自己写的Java程序代码慢上不少。
为了解决Spark的性能问题,我们基于LLVM实现了Spark的native执行引擎,同时兼容了SparkSQL接口,相比与Spark会生成逻辑节点、生成Jave bytecode,以及基于JVM运行在物理机上,FESQL执行引擎也会解析SQL生成逻辑计划,然后通过JIT技术直接生成平台相关的机器码来执行,从架构上比Spark少了JVM虚拟机层的开销,性能也会有更大的提升。
LLVM是目前非常流行的编译系统工具链,其中项目就包括了非常著名的Clang、LLDB等,而机器学习领域TensorFlow主推的MLIR以及TVM都使用了LLVM的技术,它可以理解为生成编译器的工具,目前很流行的Ada、C、C++、D、Delphi、Fortran、Haskell、Julia、Objective-C、Rust、Swift等编程语言都提供了基于LLVM实现的编译器。
JIT则是与AOT的概念相对应,AOT(Ahead-Of-Time)表示编译是在程序运行前执行,也就是说我们常编写的C、Java代码都是先编译成binary或者bytecode后运行的,这就属于AOT compiling。JIT(Just-In-Time)则表示运行时进行编译优化,现在非常多的解释型语言如Python、PHP都有应用JIT技术,对于运行频率非常高的hot code使用JIT技术编译成平台优化的native binary,这种动态生成和编译代码技术也称为JIT compiling。
LLVM提供了高质量、模块化的编译、链接工具链,可以很容易实现一个AOT编译器,也可以集成到C++项目中实现自定义函数的JIT,下面就是实现一个简单add函数的例子,相比于直接用C来编写函数实现,JIT需要在代码中定义函数头、函数参数、返回值等数据结构,最终由LLVM JIT模块来生成平台相关的符号表和可执行文件格式。由于LLVM内置了海量的编译优化pass,自己实现的JIT编译器并不会比GCC或者Clang差很多,JIT可用于生成各种各样的UDF(User-Defined functions)和UDAF(User-Defined Aggregation Functions),而且LLVM支持多种backend,除了常见的x86、ARM等体系架构还可以使用PTX backend生成运行在GPU的CUDA代码,LLVM还提供底层的intrinsic functions接口让程序可以用上现代的CPU指令集,性能与手写C甚至是手写assembly相当。
在2020年Spark + AI Summit上,Databrick不仅release了Spark 3.0,还提到了内部的闭源项目Photon,作为Spark的native执行引擎可以加速SparkSQL等执行效率。Photon同样使用C++实现,从Databrick的实验数据可以看出,C++实现的字符串处理等表达式可以比Java实现的性能高出数倍,而且还有更多vectorized指令集支持。整体设计方案与FESQL非常类似,但Photon作为闭源项目目前只能在Databrick商业平台上使用,目前还在实验阶段需要联系客服手动开启,由于也没有更多实现细节公布因此不能确定Photon是否基于LLVM JIT实现,暂时官方也没有介绍有PTX或者CUDA的支持。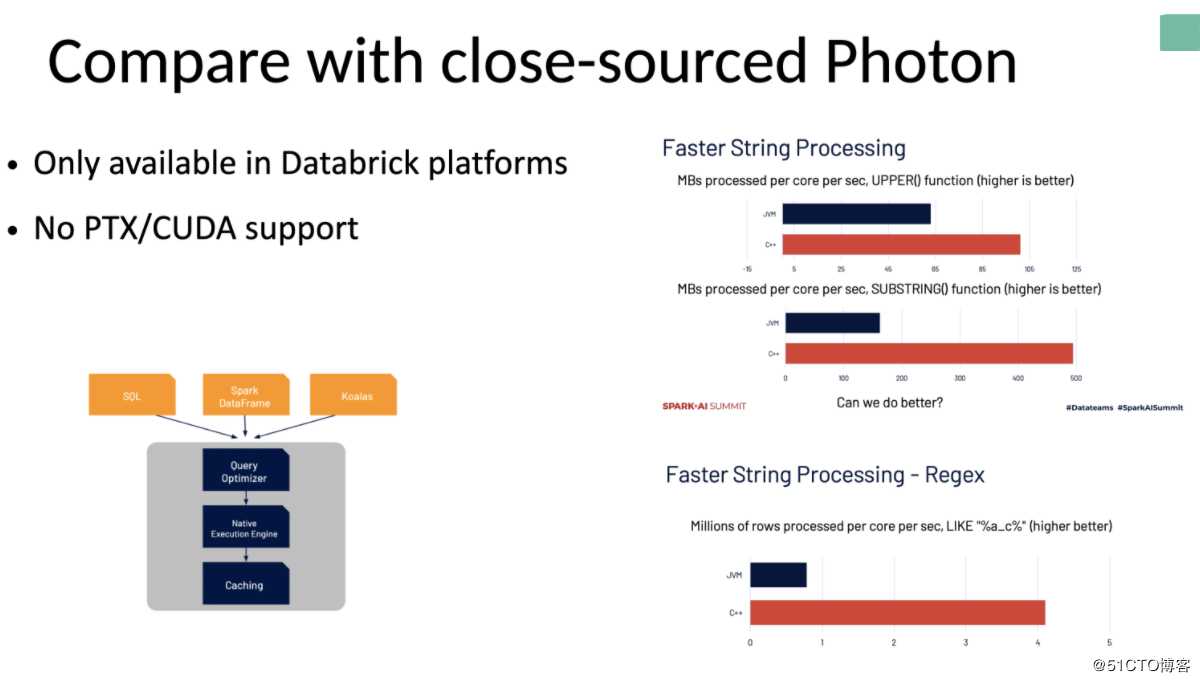
在FESQL提供的native执行引擎上,还应用了很多节点优化和表达式优化技术,例如在Project节点,使用SimpleProject可以优化掉未用到的列数据,介绍节点的运行数量以及节点间数据传输量,并且通过window node的whole stage codegen可以与Project节点直接合并,在一次迭代器运行中就可以得到所有需要的结果。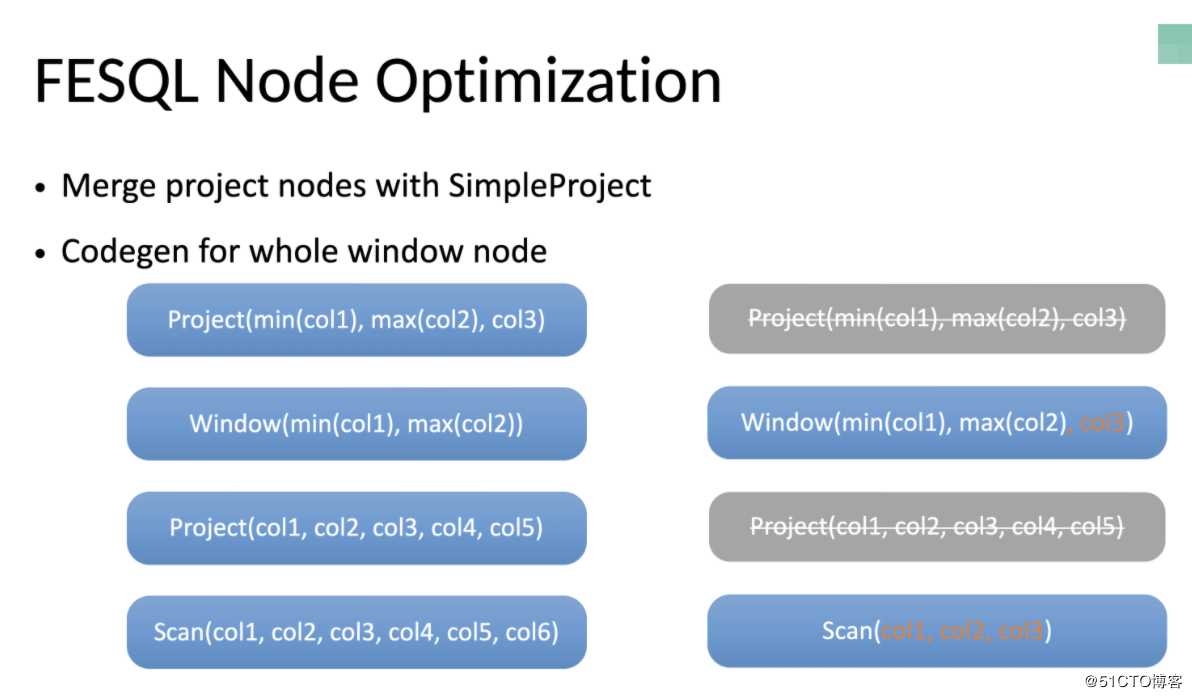
在表达式优化方面,主流和Limit、Where合并、Constant folding以及Filter、Cast、Upper、Lower简化都可以通过optimization pass来优化,生成最简洁的表达式计算从而大大减少CPU执行指令数,相关的SQL优化也就不一一赘述了,但只有经过逻辑节点优化、表达式优化、指令集优化、代码生成后才可能达到近于顶级程序员手写代码的性能。
在机器学习常用的时序特征抽取测试场景中,同一个SQL语句和测试数据,基于相同版本的Spark调度引擎,使用FESQL的native执行引擎性在单window下性能提升接近2倍,在更复杂的多window场景由于CPU计算更加密集性能可提升接近6倍,多线程下结果类似。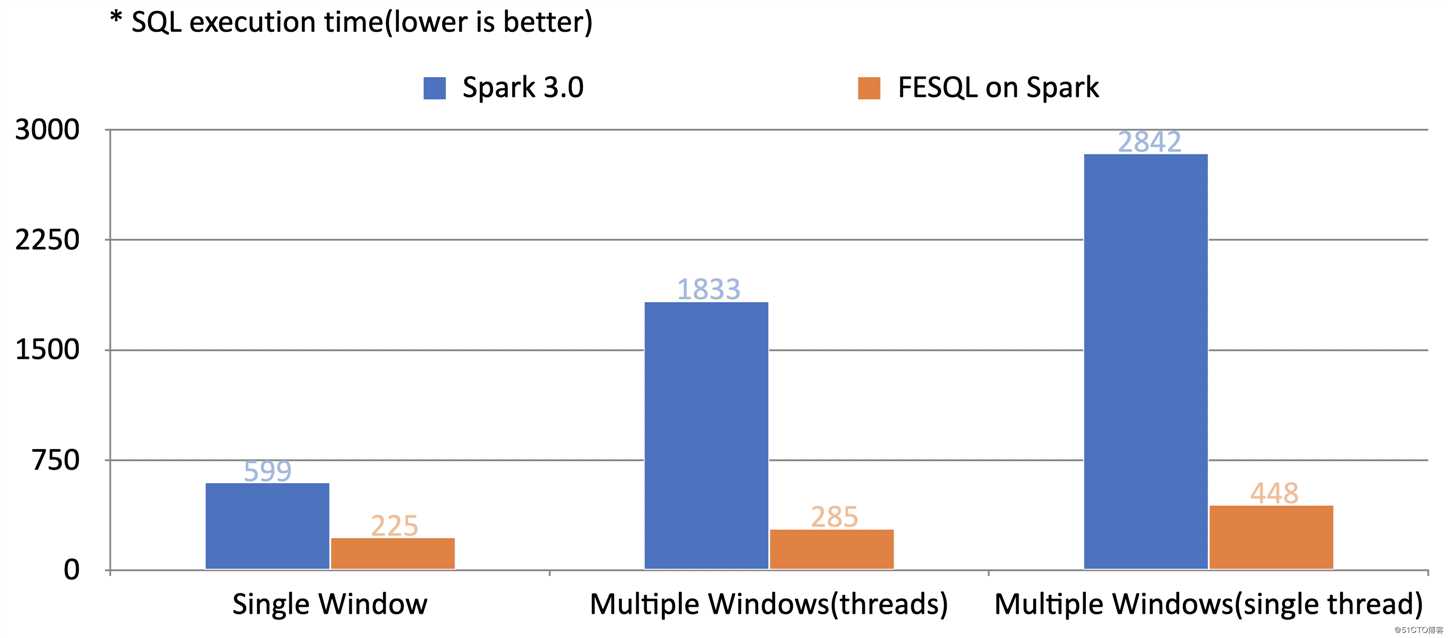
从结果上看,使用LLVM JIT的性能提升非常明显,使用相同的代码和SQL,不会修改任何一行代码只要替换SPARK_HOME下的执行引擎实现,就可以实现接近6倍甚至更大的性能提升。我们从生成的计算图以及火焰图找到性能提升的原因,首先在Spark UI上可以看到,在SparkSQL中window节点是没有实现whole stage codegen的,因此这部分是Scala代码的解释执行,而且SparkSQL的物理计划很长,每个节点间unsafe row的检查和生成都有一定的开销,而对比FESQL只有两个节点,读数据后直接执行LLVM JIT的binary代码,节点间的overhead减少很多。从火焰图分析,底层都是Spark调度器的runTask函数,SparkSQL在进行滑窗计算聚合特征时采样数和耗时都比较长,而FESQL是native执行,基本的min、max、sum、avg在编译器优化后CPU执行时间更短,左侧虽然有unsafe row的编解码时间但占比不大,整体时间比SparkSQL都少了很多。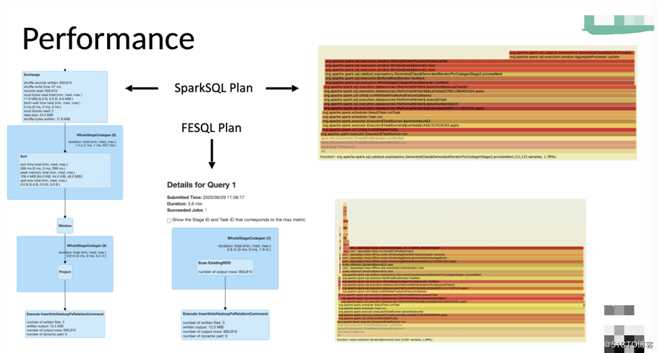
FESQL是目前少有的比开源Spark 3.0性能还更快数倍的native执行引擎,可以支持标准SQL以及集成到Spark中,与Photon仅能在Databrick内部使用不同,我们未来会发布集成LLVM JIT优化的LLVM-enabled Spark Distribution,不需要修改任何一行代码只要指定SPARK_HOME就可以得到极大的性能加速,也可以兼容目前已有的Spark应用,更多FESQL使用案例请关注Github项目 https://github.com/4paradigm/SparkSQLWithFeDB
最后总结我们在推荐系统与Spark优化的工作,首先大规模推荐系统必须依赖能够处理大数据计算的框架,例如Spark、Flink、ES(Elastic Search)以及FESQL等,Spark是目前最流行的大数据离线处理框架,但目前只适用于离线批处理,不能支持上线。FESQL是我们自研的SQL执行引擎,通过集成内部时序数据库可以实现SQL一键上线并且保证离线在线一致性,而内部通过LLVM JIT可以优化SQL执行性能比开源版Spark 3.0性能还能提升数倍。
更多FESQL使用案例请关注Github项目 https://github.com/4paradigm/SparkSQLWithFeDB
推荐系统大规模特征工程与FEDB的Spark基于LLVM优化
标签:适用于 效率 inf 提升性能 总结 标准 内存数据库 客服 tps
原文地址:https://blog.51cto.com/14858414/2510298