标签:readlines 提升 nodelist 必须 exce 源码 and ted tomat
数据驱动测试是自动化测试领域比较主流的设计模式之一,也是高级自动化测试工程师必备的技能之一。数据驱动框架是一种自动化测试框架,其目的在于可以让相同的脚本使用不同的测试数据,测试数据和测试行为(脚本)完全分离,便于测试的维护和扩展。
例如,测试登录操作时,需要用到多种用户来登录,然后验证系统的响应是否正确。这里,我们就可以先准备好要登录的用户数据(比如用户名和密码),只需一个自动化登录脚本即可实现。
数据驱动测试的一般步骤如下:
(1)编写脚本,脚本需要有可扩展性并且支持从对象、文件或者持久化数据库中读取测试数据。
(2)准备测试数据到文件或者数据库等外部介质中。
(3)循环调用介质中的数据库来驱动脚本执行。
(4)验证自动化测试结果。
在数据驱动框架中需要掌握 Python 对文件的基本操作等,在这一章中将详细讲解有关文件的相关操作。
Python 对文本文件的读取主要有三种模式:
1.read()
一次性读取文件,如果文件较大则占用内存较大。我们选择「w.txt」这个文件来做测试,如图 10.1 所示为内容截图:

图 10.1
测试代码如下:

测试结果如图 10.2 所示,read 函数也支持添加参数,比如输入参数 2 即为只输出前两个字符「ti」,返回值为字符串类型。这里需要注意,因为是读操作,所以文件权限设置为「r」。由于用到了 Python 中的字符串类「str」,所以可以使用单引号、双引号作为定界符。

图 10.2
2.readline()
特点是占用内存小、逐行读取、读取速度慢。我们以图 10.3 所示的文本文件内容为例,演示其用法,执行结果如图 10.4 所示。测试代码如下:

返回值为字符串类型。这种情况比较适合文本文件比较大的时候,因为文件越大,直接占用的内存就越大。

图 10.3
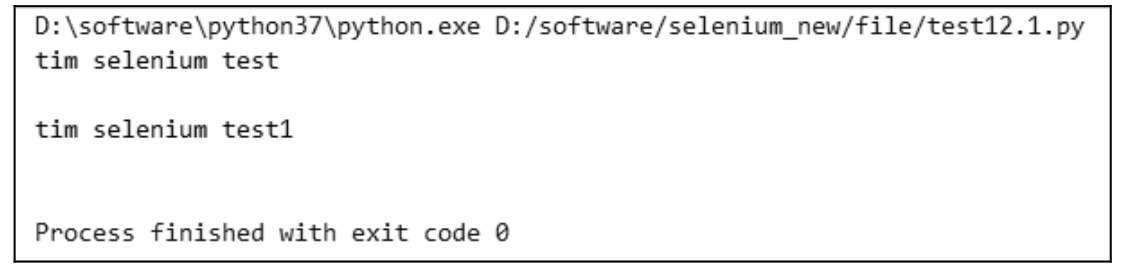
图 10.4
3.readlines()
其作用是一次性读取文本内容,并将结果存储在列表中。特点是,读取速度快,占用内存大。以上面的「w.txt」为例,改成用 readlines()之后,执行结果如图 10.5 所示。从返回数据也可以看出,readlines()的返回值是以列表形式进行存储的。

图 10.5
如要读取第一行数据,可以用 txt[0],相当于获取列表元素的第一个元素;如要读取第二行数据,需要用 txt[1]获取,以此类推。测试代码如下,执行结果如图 10.6 所示。


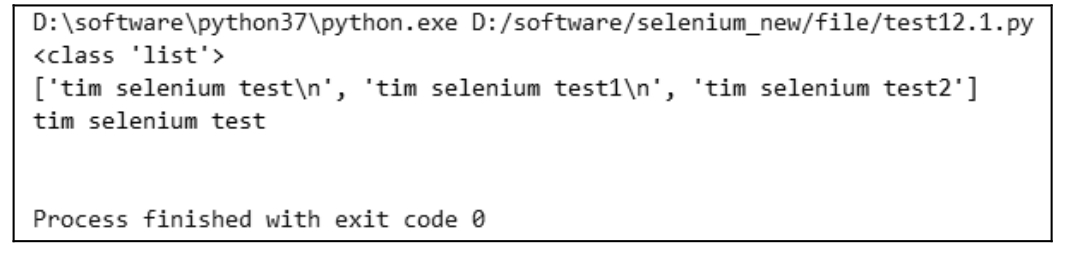
图 10.6
简单的文本文件写操作,以空文本文件「test.txt」为例进行测试,脚本源码及执行结果如图 10.7 所示,代码执行成功。在 test.txt 文件中添加的文本如图 10.8 所示为「testtest seleniumpython」。需要注意的是,这里打开文件所需要的文件权限为「w」。
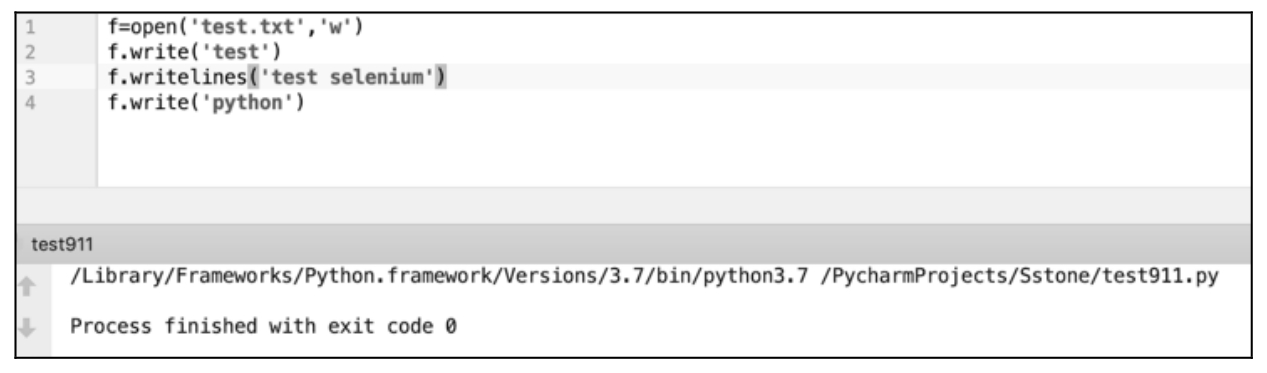
图 10.7

图 10.8
CSV 的英文全称是(Comma Separated Values)。很多测试文件和测试数据可能会保存在 CSV 文件中,所以在实施自动化测试的过程中,经常要处理 CSV 文件的请求。因此,我们要熟练掌握如何对 CSV 文件进行处理的技能。
在处理 CSV 文件时,首先需要导入 CSV 模块,语句如「import csv」。例如,业务场景是「读取 test.csv 文件,并打印出第一列数据」,如图 10.9 所示。
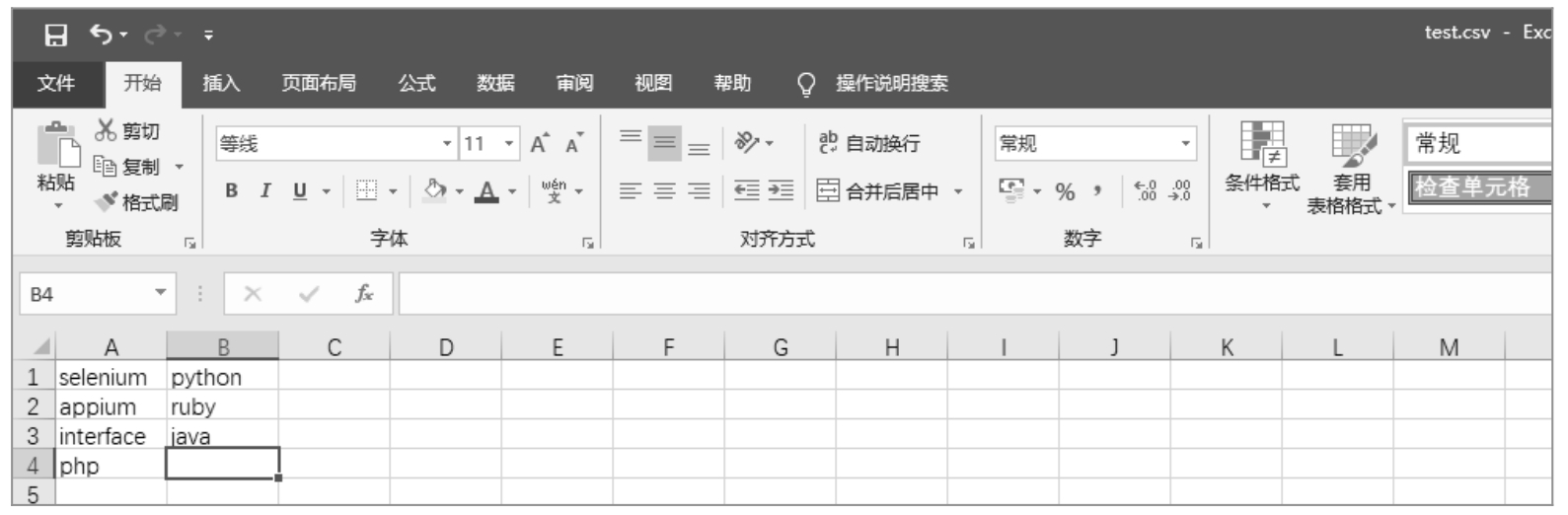
图 10.9
测试源码如下,执行结果如图 10.10 所示,在日志窗口成功输出了 CSV 文件中的第一列内容。


图 10.10
从测试结果可以看出,上述代码成功输出了 CSV 文件的第 1 列数据,并自动设置为字符串类型。
在实际测试的过程中,经常要获取 CSV 文件中的每个单元格的数据并用于测试。在这里,演示一下如何将 CSV 文件中的每个单元格的数据打印出来,代码如下所示。


执行结果如图 10.11 所示。可以看出输出内容包含 CSV 文件中所有的非空单元格。

图 10.11
上一节介绍了 CSV 文件的处理方法,本节开始讲 Excel 文件的处理方法。CSV 和 Excel 文件都可以用微软 Excel 打开,两者有哪些差别呢?
· Excel 文件是二进制文件,以工作簿的形式来管理工作表;而 CSV 是一个文本格式的文件,其中的一系列文本以逗号分隔。
· Excel 功能更强大,不仅存储数据,而且包含和数据相关的公式。而 CSV 就相对简单很多,它只是一个普通的文本文件,并不包含格式、公式和宏命令等。
· Excel 文件不能被文本编辑器打开,而 CSV 文件可以被文本编辑器打开。
· 基于编程语言的角度来分析,当处理解析这两种文件时,Excel 文件比 CSV 文件要复杂一些,且会花费更多的时间。
10.1.3.1 读取 Excel 操作
Python 要读取 Excel 文件,需要先安装 xlrd 库,可以直接在命令行窗口运行「pip install xlrd」命令,如图 10.12 所示。另外,也可以利用离线包安装,离线包的下载地址是「https://pypi.org/project/xlrd/」,现在最新版是 1.20 版本,如图 10.13 所示。
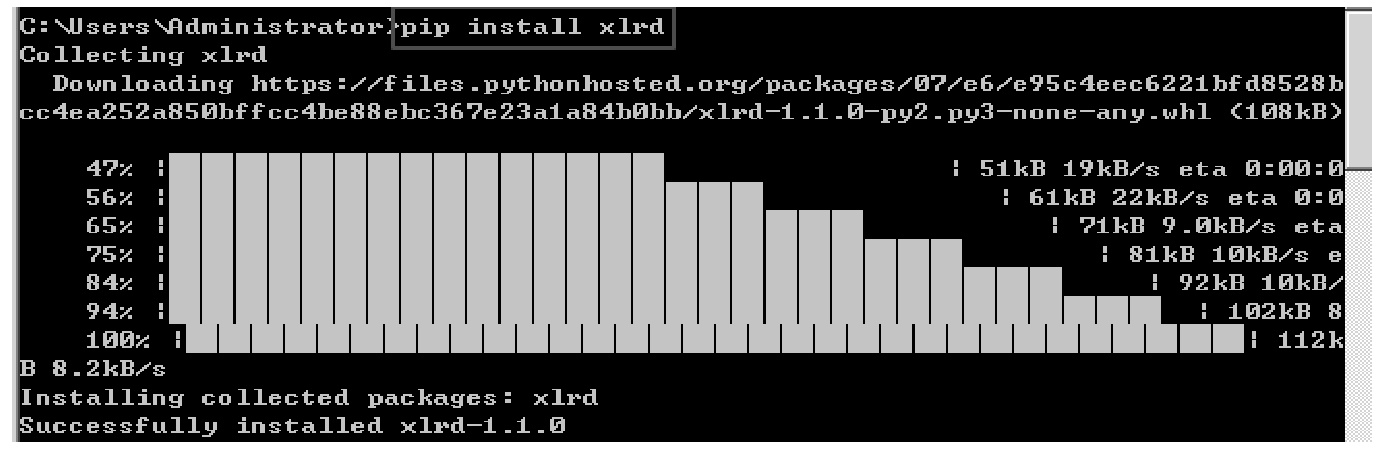
图 10.12
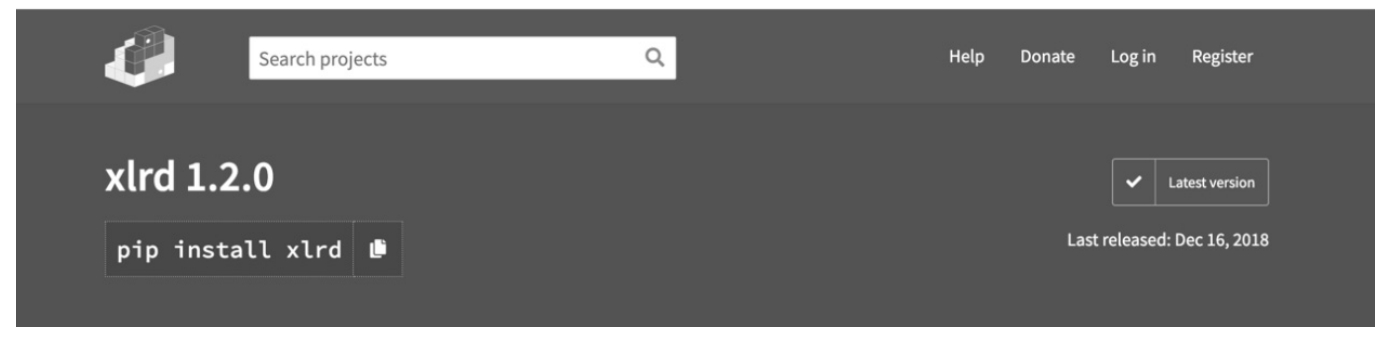
图 10.13
安装完 xlrd 库之后,就可以对 Excel 文件进行处理了。这里,以读取 Excel 文件 test.xlsx 为例,如图 10.14 所示,打开 Excel 文件可以直接用库中提供的 open_workbook()方法。除此之外,它还提供了以下三种获取 sheet 的方法。
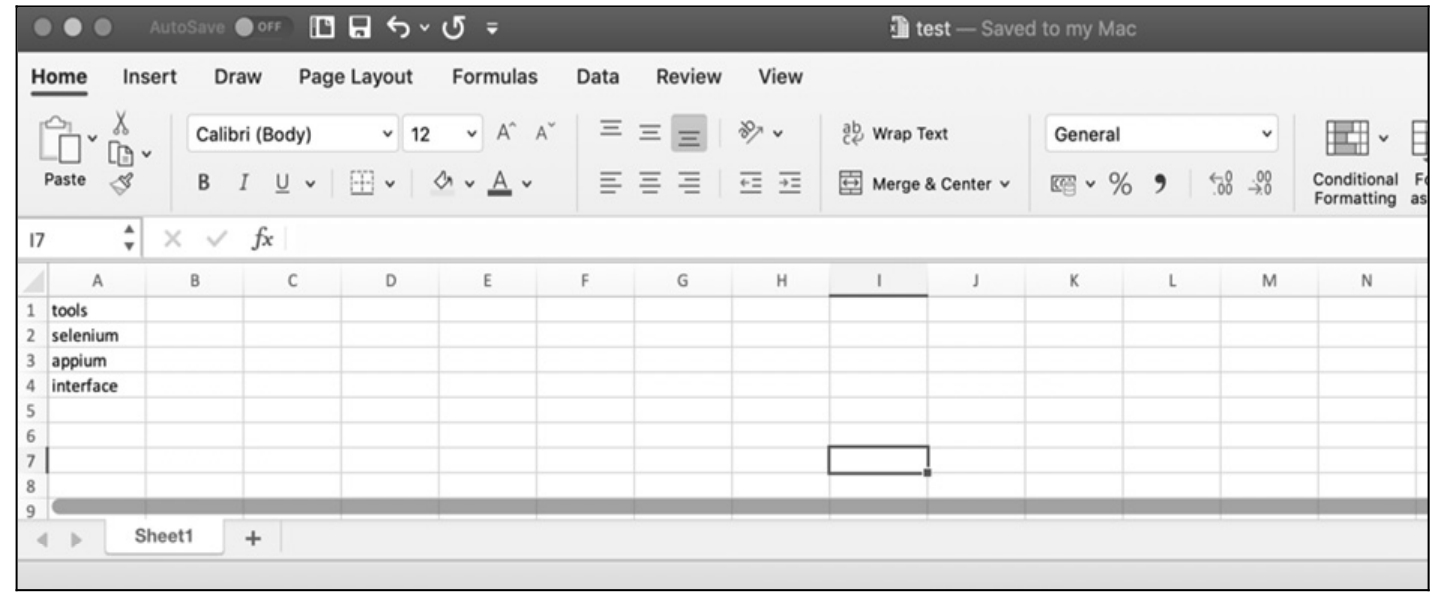
图 10.14
(1)通过 sheets()方法获取,名称为「Sheet1」的表获取方式是:sheets()[0]。
(2)通过 sheet 名称获取,名称为「Sheet1」的表获取方式是:sheet_by_name(‘Sheet1’)。
(3)通过 sheet 索引获取,名称为「Sheet1」的表获取方式是:sheet_by_index(0)。
下面介绍几种常用的读取 Excel 表格的方法:nrows 方法获取行数,ncols 方法获取总列数,row_values 方法可以获取单元格值。具体的实现方法和执行结果,如图 10.15 所示。

图 10.15
更进一步,若想获取所有的值可以用循环的形式,将 row_values 参数值设为变量,也就是将行、列数设置为变量,进行嵌套循环读取 Excel 表格中的单元格值。执行结果如图 10.16 所示。
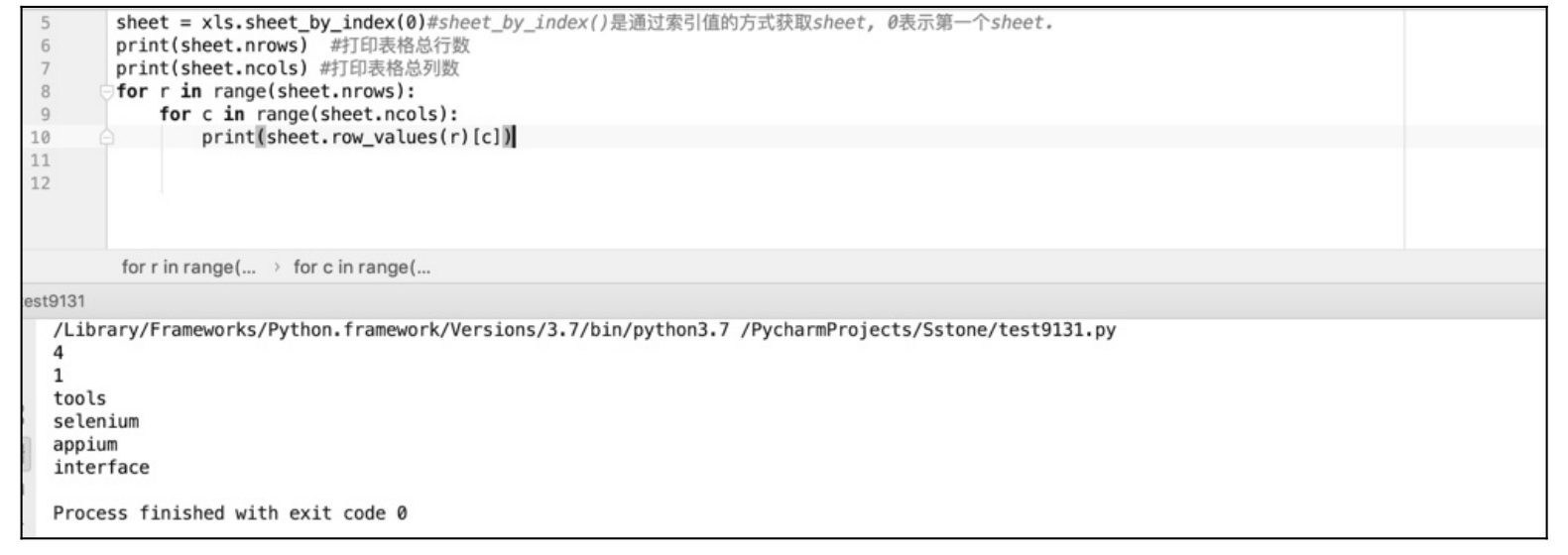
图 10.16
10.1.3.2 写入 Excel 操作
刚刚介绍的是 Excel 文件的读取操作,与之对应的就是 Excel 文件的写入操作。写操作需要安装 Python 库「xlwt」,安装方式和读取库类似,可以在命令行窗口执行命令「pip install xlwt」,安装过程如图 10.17 所示。也可以通过离线包的形式来安装,离线包下载地址为「https://pypi.org/project/xlwt/#files」。
图 10.17
同样,在运用「xlwt」时需要导入该类库「import xlwt」,这里介绍两种常用的方法。一种是 add_sheet()方法,作用是增加一个工作表 sheet;另一种是 write()方法,用于向 sheet 单元格中写入值,该方法有三个参数(行、列、具体值)。示例代码如下所示,运行结果如图 10.18 所示。

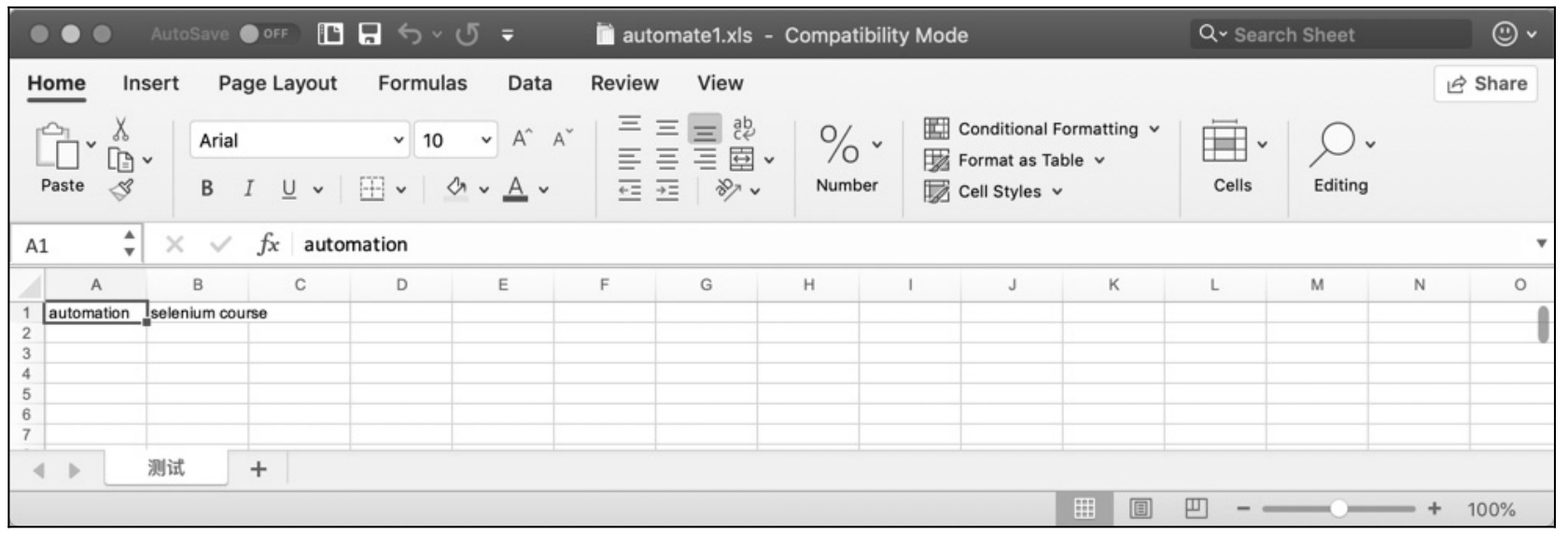
图 10.18
JSON 是一种轻量级的数据交换格式,它通过一种完全独立于编程语言的文本格式来存储和表示数据。JSON 的特点是,不仅可读性强,而且也有利于机器解析和生成,一般用于提升网络传输速率。
利用 Python 处理 JSON 这种格式的数据前,需要先导入 JSON 类库,如「import json」。
JSON 库有两个比较重要的方法:
(1)dumps()方法:将 Python 对象编码成 JSON 字符串。
(2)loads()方法:将 JSON 字符串编码成 Python 对象。
dumps 方法示例代码如下:

代码执行结果如图 10.19 所示,可以看出 JSON 格式数据字符串是双引号,而字典元素字符串为单引号。

图 10.19
loads()方法示例代码如下:

如图 10.20 所示,上例返回的数据是字典类型,通过转换表倒推可以发现,对应在 JSON 中的数据类型应该是 object 类型。之前通过 dump()方法得到的是「<class ‘str‘>」类型,它也是 object 的类型之一。

图 10.20
JSON 数据类型与 Python 数据类型转换如表 10.1 所示。
表 10.1

在上例中,返回的数据是字典类型。通过上表倒推,可以发现 JSON 应该是 object 类型。而通过反推发现,JSON 数据类型是「<class ‘str‘>」,它属于 object 类型。
接下来,举例说明如何读取 JSON 文件。先准备一个名为「test.json」的 JSON 文件,内容如下:
{"android":"appium","web":"selenium","interface":"python interface automation"}
代码如下:

执行结果如图 10.21 所示。

图 10.21
以上为 JSON 文件的读取操作,对 JSON 文件写操作代码如下:

执行成功后,会生成名为「ttt.json」的 JSON 文件,其内容如图 10.22 所示。

图 10.22
XML(可扩展标记语言),是互联网数据传输的重要载体,它不受系统和编程语言的限制。可以说,它是一个数据携带者且具有高级别通行证。XML 传递的具有结构化特征的数据是系统间、组件间得以沟通交互的重要媒介之一。
编程实践中,XML 不仅可以用来标记数据,还可以用来定义数据类型等。XML 提供统一的方法来描述和交换结构化数据。XML 具体的用途主要表现在配置应用程序和网站、数据交互等。如下源码是一个名为 user.xml 的 XML 文件示例:

根据以上 XML 源码,分析 XML 文件结果如下:
· XML 声明部分一般位于 XML 文件的第一行,且声明一般包括版本号和文档字符编码格式。如上例所示,XML 文件遵循的是 1.0 版本的标准,其字符编码格式为「UTF-8」。
· XML 文档的根元素必须是唯一的。它的开始标签位于文档最前面而结束标签位于文档最后。如上例中,<users> 和 </users> 是文档的根元素。
· 所有的 XML 元素都必须有结束标签。
· XML 标签对大小写敏感。
· 在 XML 文件中一些字符拥有特殊意义,不能够直接使用,容易造成文件格式错误,具体总结如表 10.2 所示。
表 10.2

读取 user.xml 中的用户信息,可以先用 DOM 解析 XML,再用 getElementsByTagName 方法获取 user 标签的内容。user.xml 中有两个 user,第一个 user 内容用 list[0],获取其(根元素)属性用 getAttribute 方法,子标签用 getElementsByTagName 方法。读取 XML 文件的源码如下:

源码执行结果如图 10.23 所示,与预期的结果一致。

图 10.23
如果要遍历 XML 文件中的所有值,源码如下所示:

源码执行结果如图 10.24 所示,与预期的结果一致。

图 10.24
这里,针对读取 XML 文件的过程中用到的一些重要函数,补充几点说明。
xml.dom.minidom.parse():返回文档节点对象。
getElementsByTagName():返回带有指定名称的所有元素的节点列表(NodeList)。
getAttributes():返回某一元素的属性值。
第 10 章 数据驱动测试 Selenium 3+Python 3 自动化测试
标签:readlines 提升 nodelist 必须 exce 源码 and ted tomat
原文地址:https://www.cnblogs.com/MarlonKang/p/13694632.html