标签:http 而且 虚线 第一个字符 字符串匹配 重复 详细 自己 执行
已经2年多没更新博客了,2年前这时候我还在准备考研,现在都研二了,时间过得可真快呀,研究生3年也转瞬即逝。最近稍微有点时间,于是在刷Leetcode,昨天遇到了一道题,是字符串匹配问题,我一看就知道用KMP算法,题目如下:
该题难度为easy,但我感觉KMP并不简单呀,难不成Leetcode现在大佬如云,KMP都是简单题了?并不是,我感觉大部分人看到这道题直觉上第一解法可能跟我下面一样:
(没有人比我更懂面向api编程??
但是这题原本明显是想让我们用KMP去解的,不过有一说一,STL实现效率是真的高,怪不得说leetcode上很多东西直接调库会比自己写代码效率高很多。
回归正题,今天来讨论一下KMP,我还记得4年前的自己也在这里写过KMP算法,当时自己只能说理解了KMP的一部分,就是得到了next数组之后,我知道怎么做后面的匹配部分,至于那段短短几行用来求解next数组的代码,我是看了很多遍都没看明白,第一次接触KMP算法还是大一数据结构课上听到的,当时完全没懂,一脸懵逼。第二次是自己大二自学数据结构时,当时看的是小甲鱼的视频,算是看懂了一点,但是还是没懂求next数组那部分是怎么求出来的,为什么要那么求。第三次是自己考研时看的王道数据结构,当时我还看了一些别人写的博客,我那时候理解了next数组本质是什么,会手动求next数组,因为考研不要求写求解next数组的代码,当时就没看代码。
直到今天,我又一次遇到了KMP,可谓是感慨颇多呀,折磨了我好几年,我今天终于彻底理解了,所以呀,混社会,欠下的帐该还是得还的??
我们今天要讨论以下几个问题:
1.为什么KMP比暴力算法更加高效?
2.next数组本质上代表什么?
3.求解next数组那几行代码到底是什么意思?
4.得到next数组后如何去做匹配?
对于问题1,相信很多人都已经理解的比较清晰了,假设S串为待匹配的串,T串为模式串,i指针指向S串当前比较位置,j指针指向T串当前比较位置。
暴力算法之所以暴力的原因,就是每次失配的时候,i指针和j指针都同时往左回溯,如下所示:

这似乎很符合人的直觉思维,因为让一个普通人去做这个匹配过程,他大概率也会这么做,但是,我们要知道的是,很多时候普通人的想法就等于暴力算法,我在考研机试时不会做就直接暴力算法,因为几乎不用怎么思考,太朴素的想法往往太暴力,时间复杂度比较高。
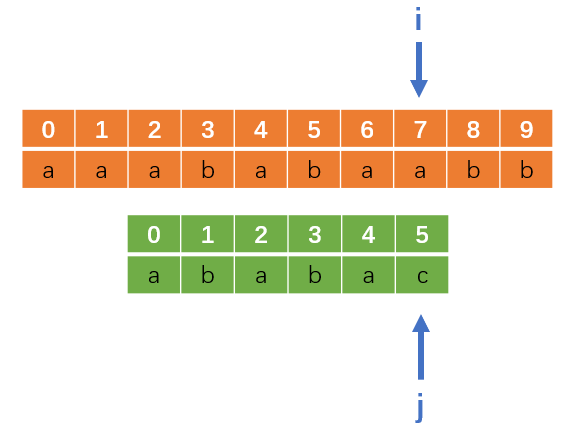
要理解KMP算法比暴力法更加高效,本质上就是要思考一个问题,当我们在做这种字符串匹配的时候,我们真的是仅仅在用T串去匹配S串吗,或者说在这个过程中如果我们用暴力算法去做时,我们难道就没有做很多重复的判断吗?下面讲个例子来说明这个问题(以下数组下标都从0开始,下面是T串,上面是S串):
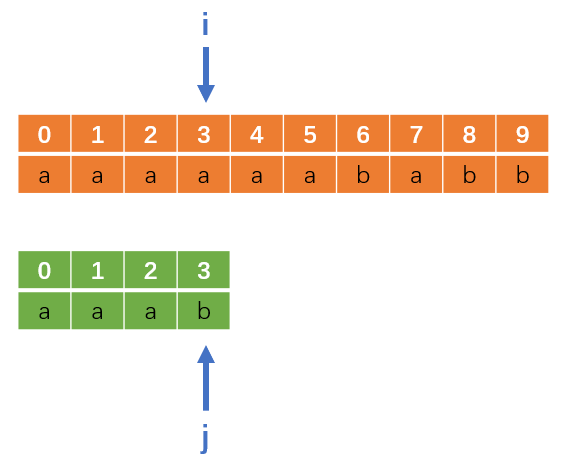
当我们进行第一趟匹配,i右移到下标3,j也右移到下标3,这时候发生失配。按照暴力算法,接下来应该按照如下方式回溯两个指针:

由于在第一次匹配过程中我们可以得知,
T[1] == S[1]
T[2] == S[2]
而我们在匹配之前就知道的信息有:
T[0] == T[1]
T[1] == T[2]
于是我们有:
T[0] == S[1]
T[1] == S[2]
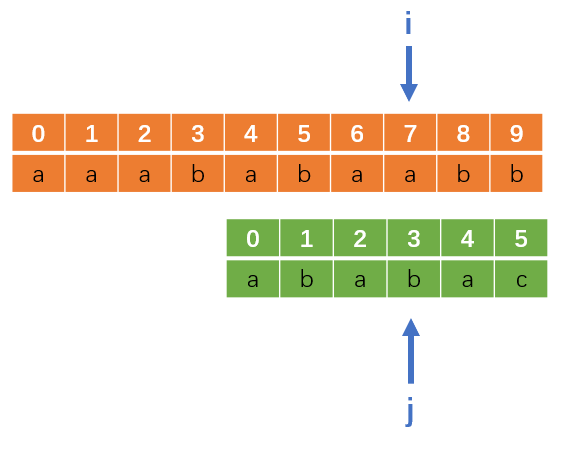
这时候你再去思考暴力法第一次失配后的指针回溯过程,你是不是发现了问题的关键,就是压根没必要把i指针回溯(往左移),j指针也不是每次都重置为0!
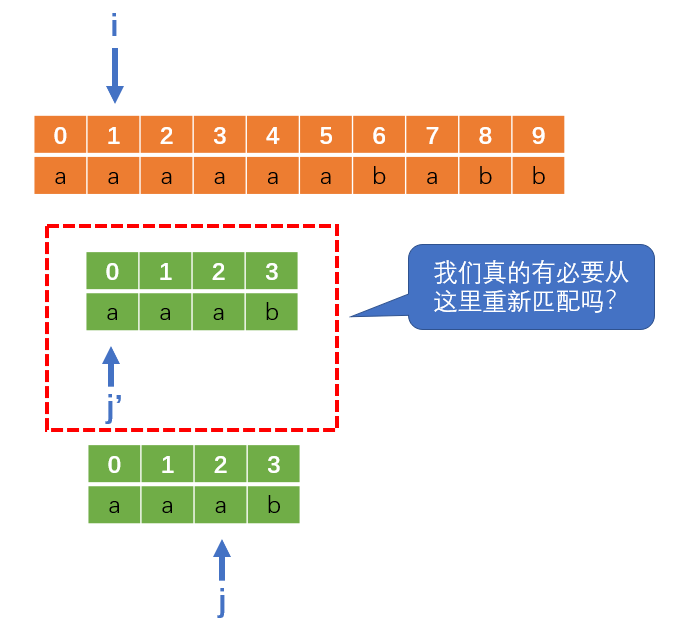
相反,我们在第一次失配后,i指针不要动,j指针往左回溯到合适的位置,如下:
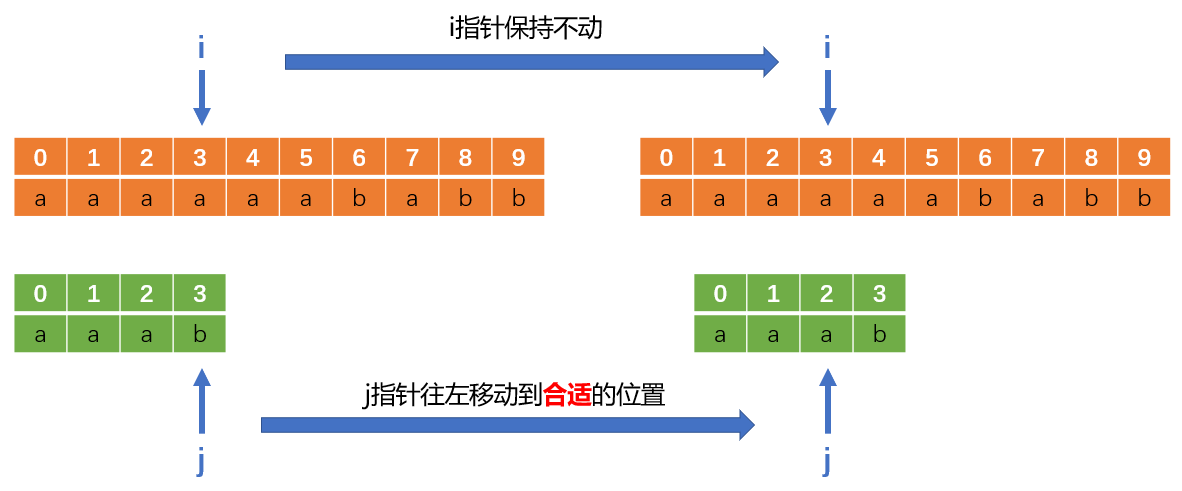
你会发现,j指针往左回溯过程关键一点就是移到那么一个“合适”的位置,使得可以跳过向上面那种没必要进行判断的过程。
问题来了,什么是合适的位置,就是每次失配时我应该往左移动多少个位置,还有就是,这个所需移动的距离是否和失配时 i指针 位置相关,还是说只和 j指针 的位置有关?
其实这个问题深入思考下去其实就是我们上面的第2个问题,那就是,next数组本质上代表什么?
下面我将从详细解释这个问题,先下一个结论,next数组正是记录着我们每次失配时应该把j指针移动到什么位置。
你从上面的过程会发现,为什么我们刚才失配后可以跳过一开始2个位置,我们说这个是因为
T[0] == T[1]
T[1] == T[2]
而且每次失配时,i指针之前的部分总是和j指针之前的部分已经完全匹配上了,所以我们可以跳过哪些不需要比较的位置,本质上取决于T串的结构,一般如下:
上面失配了,我们接下来应该将j移动到以下位置:
为什么这么移呢?还是跟上面一样,观察T的结构,在T失配位置j之前的部分,即T[0~4],如下所示:
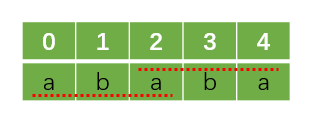
我们发现:
T[0] == T[2]
T[1] == T[3]
T[2] == T[4]
也就是说,我们可以在T[04]找到一个前缀aba(下标02)和一个后缀aba(下标2~4)使得它们两完全一样,这时候我们设这个长度为k,此处k=3,于是我们更新j为k,即j=3。
这里简单说一下前缀和后缀的概念(学过编译原理的应该对这个概念比较熟悉),
对于字符串"xyzabc",前缀有如下这些:
""(空前缀)
"x"
"xy"
"xyz"
"xyza"
"xyzab"
"xyzabc"
后缀有如下这些:
""(空后缀)
"c"
"bc"
"abc"
"zabc"
"yzabc"
"xyzabc"
有人可能会说最长能够完全重叠的前缀和后缀不应该是这个字符串本身吗,所以我们得说明一下,我们这里的最长是不能包含这个字符串全部字符的。
于是我们引出next数组的定义。对于字符串T,下标从0开始,其next数组长度和字符串本身是一样的,next数组求解只和T本身相关,因为next数组本质上反应的是T本身的结构。
next[i]表示T[0i]这个字串中前缀和后缀最大重合长度,注意这个前缀不能包括T[0i]的全部字符。
注意next[0]固定为0,因为T[0~0]只有T[0]一个字符,而前缀又不能包含全部字符,故next[0]只能是0
先不介绍具体求解next的代码,先学会手动求解next,手动求解next数组应该是很简单的,只需要看每个位置结尾的子串的最大前缀和后缀重合长度,例如:
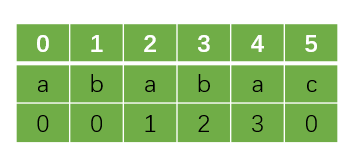
所以看到现在你应该能知道为什么KMP问题中要用到next数组,我发现很多地方在讲KMP算法时,都是先教你如何求解next数组,再讲如何进行接下来的匹配过程,其实,很多算法并不是我们理解不了,而是我们没有经历发明这个算法的那个大佬的思考过程,你如果也按照上面的过程去思考,你会很自然理解为什么要用到next数组,以及它的具体含义和作用。
那么接下来我们来讲问题3,即求解next数组的代码,说实话,这段代码毫不夸张,困扰了我好几年,当然主要还是因为我每次都是直接从代码本身去理解,这样只能看到那些值是如何变化的,却不理解这些值在变换过程代表着什么。我先贴上严蔚敏C语言版数据结构书上的代码,这本书也是我本科学数据结构用的书,说实话,里面很多代码对初学者不是很友好,至少我当时很多代码都没读懂,也许是因为我太菜了??

我当时就觉得这代码好精简呀,可能是因为太精简了,导致我一直不理解它是怎么求解出了next数组,我自己也写过一个很暴力的方法来求解next数组,其实就是把我们手动求解的过程写成了代码,所以还是那句话,我们很多朴素的想法往往都是那些很容易想出来,但是时间复杂度往往都很高的算法。
求解next数组一个核心的思想就是“迭代”。
迭代的意思就是你不要把求next数组每个位置的值当作一个独立的过程,而是前面求出来的值是可能被后面用到的,就有点像动态规划,动态规划前面一些子状态的值是要在后面求解某个状态的值的过程中要用到。在此处,我们是先已知next[0]的值,next[0]固定为0。然后我们再求next[1],再求next[2]。。。一直求完整个next数组。在我们求解next[i]时我们会用到next[i-1]的值,也可能用到next数组中前面某个已经求出来的值。
为了解释我们为什么可以用上next数组中前面某个位置已经计算出来的值,我们举如下例子:
假设现在我们已经求出next数组中以下位置的值
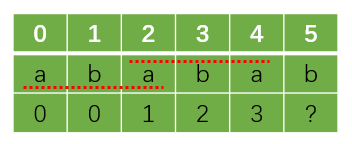
现在我们需要计算next[5],有人可能会忽视之前的计算结果而对这次计算过程单独进行,事实上,我们会发现,其实前面的next[4] = 3,意思就是说T[0~4]中最长的前缀和后缀重合长度是3
这个长度对应的前缀和后缀就是我上面虚线所画的部分,我们发现,如果这个前缀最后一个字符的下一个字符和我们正在求解的next[5]这个下标5所对应的字符相等,那么next[5] = next[4] + 1。
而这个前缀最后一个字符的下一个字符其实就是T[3],即T[next[4]],之所以这么巧,是因为我们所有的下标都是从0开始的,这与很多地方从1开始稍有区别。
有人可能会问,那当我们已经求出了next[i-1],而且当T[next[i-1]] == T[i]时,next[i] = next[i-1] + 1 真的是next[i]正确的解吗?换言之,next[i]可不可能更大呢?
其实要证明next[i]的最大值就是next[i-1] + 1也很好证明,因为如果next[i]要更大,一定要使得next[i-1]也要更大,而next数组的定义是最大的前缀后缀重叠长度,
说明一旦求出某个位置的next值的时候,就说明它已经是最大的了,并且不会在后面计算其他位置next值的时候被修改掉。
到这里都还比较好理解,接下来的一步就很关键了,也是我一开始没理解的地方,那就是当我们在计算next[i]时发现 T[next[i-1]] != T[i],这时候next[i]该如何计算
我一开始觉得,如果不相等,那是不是说明我们要重新去寻找T[0~i]最长的前缀后缀重叠长度,也就是说,我们是不是不能再用上之前计算出来的next[0]到next[i-1]的值?
非也,你始终要记住,求解next的过程是一个迭代的过程,就是后面计算过程会用到前面计算出来的结果。我们接下来通过一个例子说明这种情况:
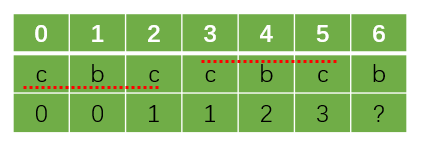
如上图所示,现在我们已经求出了next[0]到next[5]的值,接下来我们要计算next[6],于是我们先读取next[5]的值,令j = next[5] = 3
接下来比较T[j]即T[3]和T[6]是否相等,我们发现不相等,那么接下来我们读取next[j-1]即next[2]的值,令j = next[j-1] = next[2] = 1。
很多人也需要问了,你这个时候用next[2]的值干嘛呢,其实你想清楚了这一步,也就基本理解了整个next数组的求解过程。
我们现在要找T[02]这个字串的最长前缀后缀重合长度,假设这个最长的前缀是xyz(实际长度不一定是3,我只是为了说明一般情况),也就说明T[35]有一个后缀也是xyz,因为T[02]和T[35]正是上一步用到的next[5]对应的最长的前缀和后缀。
你现在看看,T[02]有一个前缀是xyz,T[35]有一个后缀也是xyz,这个xyz的长度就是T[02]前缀和T[35]后缀能够重叠的最大长度。
现在我们思考一下T[0~2]这个前缀xyz后一个字符(即z后面的一个字符)的下标是多少,没错,你会发现,其实跟上面计算方式是一样的,为j = next[2],而当前待计算的next的下标是6。
如果T[j] = T[6],那么next[6] = next[2] + 1。
如果T[j] != T[6],那么你会发现,接下来的过程就是重复上面的过程,即重复更新j = next[j-1],然后判断T[j]是否和当前的T[6]相等,相等就计算完了,不相等就继续。
那么上面的过程要是一直出现T[j] != T[6]会怎么样?
我们很容易知道,一旦出现T[j] != T[6],j就会往左移,j最多是变小成为0,如果T[0] != T[6],那说明什么问题?
仔细想想这个地方,没错,说明T[06]压根就没有前缀能和后缀匹配上,因为T[06]最短的前缀为T[0],最短的后缀为T[6](我们这个地方不考虑空的前缀和后缀)。
你在理解到了这个层面上最去看求解next数组的代码,是不是就能看懂了??,以下是我用C++写的代码,其实你会发现,基本上就是严蔚敏的代码。
vector<int> getNext(string T) {
//计算T串的next数组
if (T.empty()) return {};
int len_T = T.size();
vector<int> next(len_T, 0);//注意,此处的next数组的下标是从0开始的
int i = 1, j = 0;
while (i < len_T) {
if (T[i] == T[j]) {
next[i++] = ++j;
}
else {
if (j == 0) next[i++] = 0;
else j = next[j - 1];
}
}
return next;
}
上面循环过程中的i代表当前正在计算next[i],j的含义就是我上面所说的,一开始j为什么等于0呢,可能很多人没明白这个。
其实是因为next[0]是固定为0的,所以i是从下标1开始循环的,所以当第一次求解next[1]时,j是等于next[0]的,所以j一开始初始化为0。
对于循环里面的
if (T[i] == T[j]) {
next[i++] = ++j;
}
部分,可能也有不少人没理解,其实拆成3行代码更好理解
首先是
next[i] = j+1;//这个就是我上面解释的
然后因为next[i]求解完了,接下来我们要求解next[i+1],于是执行
i++;
很多人没明白,那为什么右边不是j+1,而是++j。
因为next[i] = ++j可以拆成
next[i] = j+1;
j++;
所以现在问题是我们计算出来了next[i]之后,为何j要自增1。
这个是因为你忘了我们为什么能执行这行语句,就是因为T[i] == T[j]
试想,当我们进行下一轮循环时,我们是要把T[i+1]的值和T[j]比较还是和T[j+1]比较?自然是和T[j+1]比较,因为这一轮T[i]已经等于T[j]了。
下面else里面的代码我就不解释了,应该都能看懂,只要理解了我上面的推导过程就行。
由此可见,求解next数组的代码确实十分精简,效率也非常高,这么简短的几行代码,确实蕴含着发明这个算法的人非常深刻的思考过程。我们回过头来想想,KMP名字的由来是什么?
KMP全称是Knuth-Morris-Pratt,它以三个发明者命名,起头的那个K就是著名科学家Donald Knuth。
Donald Knuth学计算机的应该都不陌生吧,照片就是下面这个,著名书籍《计算机程序设计的艺术》就是他写的,著名论文写作工具LaTex的前身Tex也是他开发的,光看这个发际线就知道有多么牛逼了。

接下来,就进入本篇最后一部分,就是我们在求解出next数组之后,该如何用模式串T去匹配主串(待匹配串)S。这部分应该来说是比较简单的,详细过程就是我上面第一部分解释的那样。
基本上几句话就能概括这个过程,用i指针指向S串第一个字符,j指针指向T串第一个字符,重复下面过程:
如果S[i] == T[j],那么i和j各自往右移动一个位置。如果j移到T串外边去了,说明匹配上了一次,记录下此处匹配i的起始位置,
如果S[i] != T[j],更新j为next[j-1],不过要注意的是如果发现j=0了,那么说明这个位置没法匹配了,直接i++。
这部分具体代码如下:
vector<int> KMP(string S, string T) {
int len_S = S.size(), len_T = T.size();
if (len_T > len_S || S.empty() || T.empty()) return {};
vector<int> next = getNext(T);
vector<int> res;
int i = 0, j = 0;
while(i <= len_S) {
if (S[i] == T[j]) {
i++;
j++;
if (j == len_T) {
res.push_back(i-j);
j = next[j - 1];
}
}else {
if (j > 0) j = next[j - 1];
else i++;
}
}
return res;
}
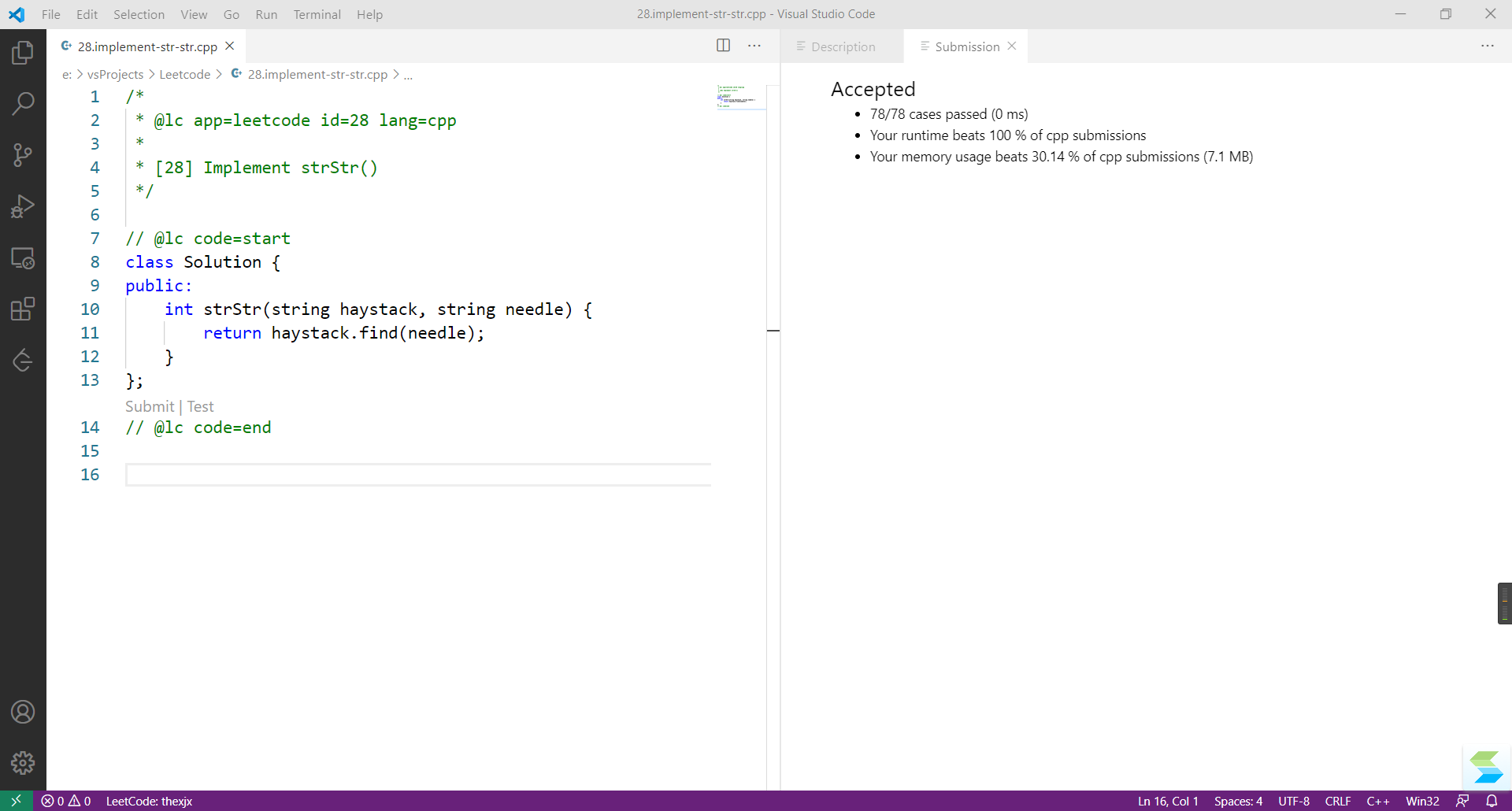
leetcode提交结果如下:
ok,终于全部讲完了!
写这篇文章主要是这个问题之前困扰我很久了,然后我自己也看过很多博客,感觉或多或少都有些地方没讲明白,所以写在这里,一是希望可以帮助曾经像我一样很难理解这个算法的人能更清晰地理解这个算法,二是自己以后要是忘了,能较快回忆起来。
如果有问题,还请大家提出来,我会加以修改,多谢!
参考文章:
https://www.geeksforgeeks.org/kmp-algorithm-for-pattern-searching/
https://blog.csdn.net/qq_37969433/article/details/82947411
标签:http 而且 虚线 第一个字符 字符串匹配 重复 详细 自己 执行
原文地址:https://www.cnblogs.com/njuxjx/p/13783413.html