标签:重点 运营 流程 png 隐藏 文章 margin 小问题 acl
易有太极,是生两仪,两仪生四象,四象生八卦。
——《易传·系辞上传》
《特征工程的黑色艺术》
想象一下,当今社会备受瞩目的人工智能和数据挖掘算法工程师每天大部分时间都在做什么呢?是花大量时间手推公式,还是思考各种trick对算法调参,还是一遍遍清洗数据和加工特征?实际上,大部分的数据挖掘/算法工程师在日常的工作流程中,80%以上的时间用于研究特征工程,而他们在算法设计和模型优化上分配的时间不到20%。特征工程为何如此重要,以至于数据挖掘/算法工程师甘愿把如此之多时间都花在这上面呢?
特征工程是连接数据和算法的桥梁
要想了解特征工程必须首先了解什么是机器学习,机器学习致力于研究如何通过计算的手段,利用经验来改善系统自身的性能。一个典型的机器学习框架可以用问题抽象,特征挖掘,模型选择和模型融合四个步骤进行概括,这其中特征工程是连接数据和算法的桥梁。从数学的角度讲,特征工程就是将原始数据空间变换到新的特征空间,处理后的数据会以一种机器更容易理解的方式表达数据背后的逻辑,模型能够更好学习数据表面和隐藏的规律。
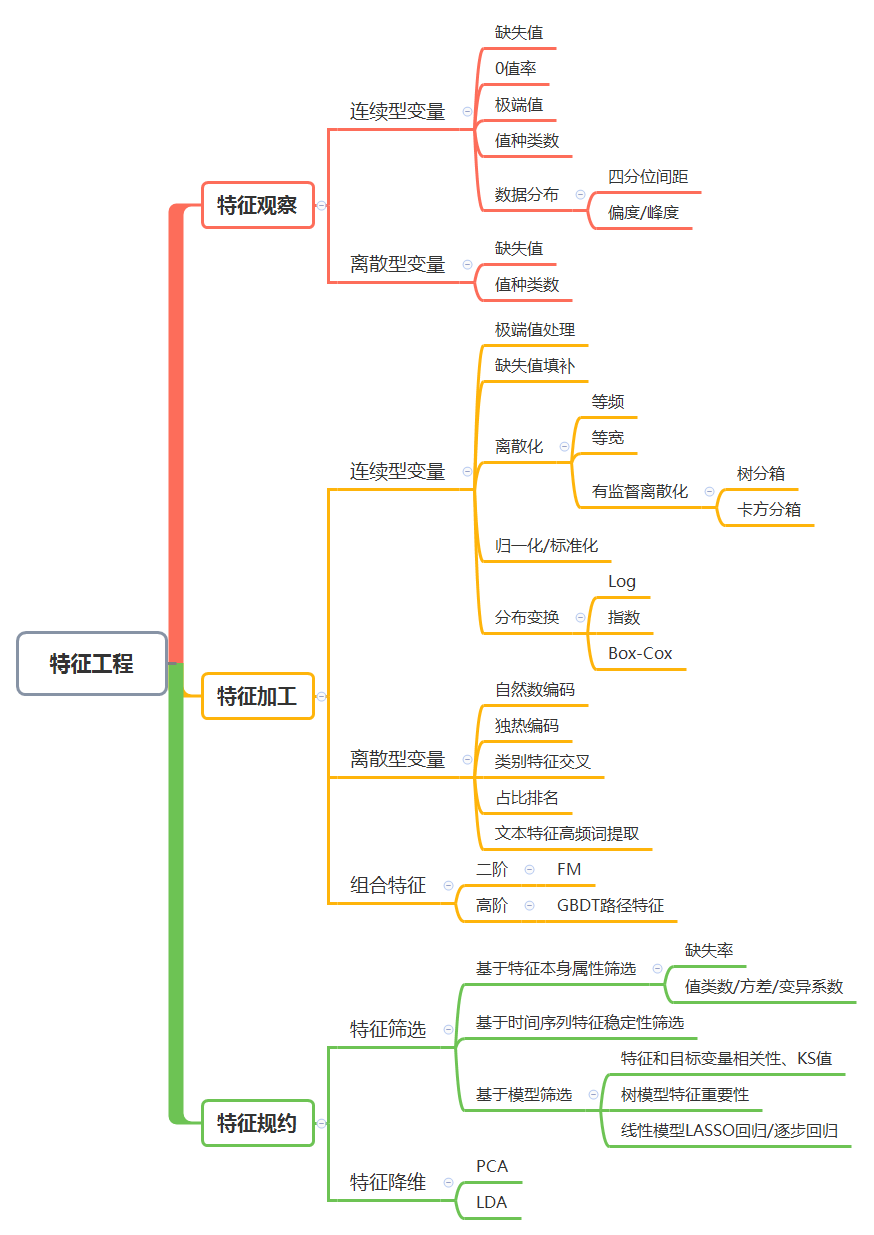
图:特征工程主要环节导图
1. 好的特征工程建立在好的数据质量
细节决定成败-缺失值处理
01
如XGBoost的一些机器学习算法可以在模型构建过程中对特征缺失值进行处置,但是俯视整个建模流程,我们并不能“放心的”把数据缺失问题直接交给算法。我们首先来回顾一下XGBoost是如何处理特征中的缺失值的:XGBoost论文中曾提及,缺失值会被分别分入左右子树,比较两者损失函数值下降的程度,然后选择最优的划分方式。这里缺失值其实是被看做一个不同于变量中任何值的值(例如:-9999)。那为什么说我们仍需在模型训练阶段之前处理缺失值?原因在于:我们需要考察值的缺失类型。谨慎加工防止数据穿越
02
稳定大于一切
03
2. 特征构造方法需要量体裁衣
在日常生活中,我们接触到的数据类型方方面面,近年来步入AI时代,人们对数据的探索视野已跳出二维数据框架,踏上对图像、声音或时空数据的探索征途。以下,我们将结合风控场景介绍三种特殊的数据类型构造方法:
时间序列特征
01
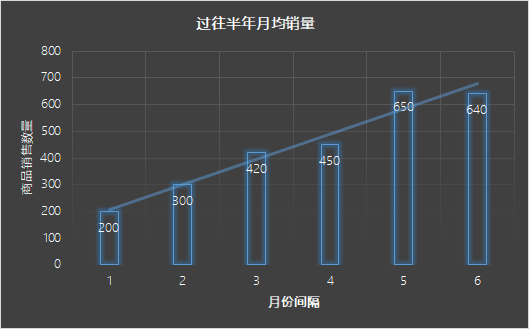
图:趋势类特征加工示意图
位置特征
02
文本特征
03
方法一
通过分词并统计词频计算TF-IDF,然后与响应变量交叉分析,选择Lift较高的关键词,进行统计汇总或直接用TF-IDF值作为向量,加入模型进行训练;方法二
将分词后的文本序列,通过word2vec或doc2vec等方法将词或句子表示成向量,和连续性变量一同通过wide&deep框架进行学习,如下图所示;特征筛选
04
建模前筛选 - 过滤式
建模前筛选的原则是:逐个考察特征属性,与后阶段采用的模型无关。进行筛选的角度则如上图所罗列的3个方面:① 信息量。特征的根本价值应作为首要考察角度,对于分类型变量,我们期望值类型不应该太多,这样做OneHot Encoder时数据不至于过度稀疏。② 稳定性。在上文“时间序列特征”,已经点明有些特征带有很强季节性,在实际建模过程中,我们会考察每个特征逐月PSI稳定性。③ 目标相关性。业界常用方式包括逐个考察特征和目标变量的KS值、IV值、相关性等。建模中筛选 - 模型嵌入式
将特征送入模型工厂,基本意味着特征分析阶段告一段落,用最终模型筛选特征,才是体现特征实际价值之时。在统计建模时代,逐步回归和Lasso回归就是对特征筛选的大杀器,大部分机器学习模型都有筛选特征的功能或指明特征重要性的指标,而本次着重点明的是交叉验证在特征筛选方面的重要性。交叉验证在模型训练阶段有不可替代的价值,除了做模型选择、模型调参外,其实配合特征重要性指标用在特征筛选阶段也可以同时考察特征稳定性。如果在对时间序列训练数据做交叉验证时不做随机化,那每个子集可以体现样本时间序列的差异,假如我们的训练数据中没有时间变量“加持”,那其实要求我们最终入模的特征在大多数子集中都应该有较好表现;例如我做10折交叉验证,可以考虑特征入模次数是否达到5次,以此作为特征稳定性+重要性的综合筛选依据。特征工程自动化修远兮却可期
通过前文我们了解了大量构造特征的方法,但找到适合场景的有效特征不太容易,需要广泛的数据探索和领域知识,这些知识的获得需要业务经验和平时积累,看似差别在毫厘之间实则差距在千里之外,这也是为什么特征工程又是艺术的原因。一,当前自动化特征工程仍处于基础阶段,在实际的应用中,对数据质量要求很高,数据的理解和分析仍然是最耗时部分,目前这部分仍然需要大量人工参与;
二,自动化特征工程衍生特征本质上是人工经验的提炼,能否提高模型效果,提高部分是否可信,仍然需要大量时间论证;
三,风控场景对于特征的可解释性,稳定性要求是重点,可解释性和稳定性仍然需要结合业务和专家经验进行判断;
尾章
读到此,想必您对特征工程已经有了大致的了解,体会了特征工程对于模型开发的重要性——好的模型效果建立在好的数据质量上,而且需要针对不同的数据采用不同的构造方法。在实际的工作中,我们只有结合数据处理和业务理解把特征工程做好,才能引爆特征工程隐藏的黑色艺术!最后,留几个小问题给您:
1. 噪声数据一定是坏的吗?
2. 相对线性模型如(LR),XGBOOST等树模型算法在特征工程上有什么不同?
3. 如何有效衍生特征?
参考文献
1. He, Xinran, et al. "Practical Lessons from Predicting Clicks on Ads at Facebook." international workshop on data mining for online advertising (2014): 1-9.
2. 周志华,机器学习,清华大学出版社,2016: 247-256
3. Chen, Tianqi, and Carlos Guestrin. "XGBoost: A Scalable Tree Boosting System." knowledge discovery and data mining (2016): 785-794.
4. Mikolov et al., 2013b. Mikolov, T., Yih, W.-t., and Zweig, G. (2013b). Linguistic regularities in continuous space word representations. In hlt-Naacl, volume 13, pages 746–751.
5. Halevy, Alon, Peter Norvig, and Fernando Pereira. "The Unreasonable Effectiveness of Data." IEEE Intelligent Systems 24.2 (2009): 8-12.








标签:重点 运营 流程 png 隐藏 文章 margin 小问题 acl
原文地址:https://www.cnblogs.com/cx2016/p/13798615.html