标签:discard you ret win turn cts build while day
一篇很不错的关于fat jar 的文章,参考资料https://product.hubspot.com/blog/the-fault-in-our-jars-why-we-stopped-building-fat-jars
HubSpot’s backend services are almost all written in Java. We have over 1,000 microservices constantly being built and deployed. When it comes time to deploy and run one of our Java applications, its dependencies must be present on the classpath for it to work. Previously, we handled this by using the maven-shade-plugin to build a fat JAR. This takes the application and all of its dependencies and bundles them into one massive JAR. This JAR is immutable and has no external dependencies, which makes it easy to deploy and run. For years this is how we packaged all of our Java applications and it worked pretty well, but it had some serious drawbacks.
Fat JAR Woes
The first issue we hit is that JARs are not meant to be aggregated like this. There can be files with the same path present in multiple JARs and by default the shade plugin includes the first file in the fat JAR and discards the rest. This caused some really frustrating bugs until we figured out what was going on (for example, Jersey uses META-INF/services files to autodiscover providers and this was causing some providers to not get registered). Luckily, the shade plugin supports resource transformers that allow you to define a merge strategy when it encounters duplicate files so we were able to work around this issue. However, it’s still an extra "gotcha" that all of our developers need to be conscious of.
The other, bigger issue we ran into is that this process is slow and inefficient. Using one of our applications as an example, it contains 70 class files totalling 210KB when packaged as a JAR. But after running the shade plugin to bundle its dependencies, we end up with a fat JAR containing 101,481 files and weighing in at 158MB. Combining 100,000 tiny files into a single archive is slow. Uploading this JAR to S3 at the end of the build is slow. Downloading this JAR at deploy time is slow (and can saturate the network cards on our application servers if we have a lot of concurrent deploys).
With over 100 engineers constantly committing, we usually do 1,000-2,000 builds per day. With each of these builds uploading a fat JAR, we were generating 50-100GB of build artifacts per day. And the most painful part is how much duplication there is between each of these artifacts. Our applications have a lot of overlap in terms of 3rd party libraries, for example they all use Guice, Jackson, Guava, Logback, etc. Imagine how many copies of these libraries we have sitting in S3!
Eventually we decided we had to find a better way to do this. One of the alternatives is to use the maven-dependency-plugin to copy all of the application’s dependencies into the build directory. Then when we tar up the build folder and upload it to S3 it will include all of the dependencies, so we still have the immutable builds that we want. This saves us the time of running the shade plugin and the complexity that it adds. However, it doesn’t reduce the size of the build artifacts so it still takes a while to upload the tarball at the end of the build, which also means we’re still wasting a huge amount of space storing these build artifacts, and then it still takes a long time to download these artifacts on deploy.
Using the example application from before, what if we just uploaded the 210KB JAR? Imagine how much faster the build would be (turns out it’s up to 60% faster). Imagine how much space we would save in S3 (over 99%). Imagine how much time and I/O we would save on deploys. In order to do this, we wrote our own Maven plugin called SlimFast. It binds to the deploy phase by default and uploads all of the application’s dependencies to S3 individually. On paper this actually makes the build slower, but the trick is that it only needs to do this if the dependency doesn’t already exist in S3. And since our applications’ dependencies don’t change very often, this step is usually a no-op. The plugin generates a JSON file with information about all of the dependency artifacts in S3 so that we can download them later. At deploy time, we download all of the application’s dependencies, but we cache these artifacts on each of our application servers so this step is usually a no-op as well. The net result is that at build time we just upload the application‘s thin JAR which is only a few hundred kilobytes. At deploy time we only need to download this same thin JAR which takes a fraction of a second.
After rolling this out, we went from producing 50-100GB of build artifacts per day to less than 1GB. In addition, not running the shade plugin and not uploading fat JARs to S3 had huge benefits in terms of build speed. Here‘s a graph showing build times before and after the change for some of our projects:
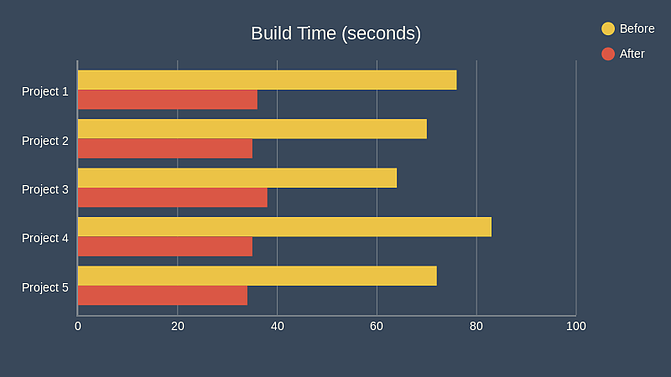
We‘ve been running this setup in production for over 4 months and it‘s been working great. Check out the SlimFast readme for more detailed information on how to get it set up and let us know how it works for you!
The Fault in Our JARs: Why We Stopped Building Fat JARs
标签:discard you ret win turn cts build while day
原文地址:https://www.cnblogs.com/rongfengliang/p/13851708.html