重构查询的方式
一个复杂查询还是多个简单查询
在传统实现中,总是强调数据库完成尽可能多的操作,这样做的逻辑在于以前总是认为网络通信,查询解析和优化是一件代价很高的事情;
但是这样的想法对于mysql并不适用,mysql在连接和断开设计的很轻量,在返回一个小的查询结果方面很高效
Mysql内部每秒能够扫描内存中数百万行数据,相比之下,mysql响应数据给客户端就慢得多,其他情况相同时,减少查询当然更好,但是有时候,将一个大查询分解成多个小查询是有必要的
切分查询
有时候对于一个大查询我们需要“分而治之”,将大查询切分成小查询,每个查询功能完全一样,只完成一小部分,每次只返回一小部分查询结果。
eg 将一个大的delete分成多个小的
分解关联查询
用分解关联查询的方式重构查询有以下优势:
1.让缓存效率更高
2.查询分解后,丹哥查询可以减少锁的竞争
3.应用层做关联,更容易对数据库进行拆分,更容易做高性能和扩展
4.减少冗余记录的查询寻
5.避免嵌套关联
查询执行的基础
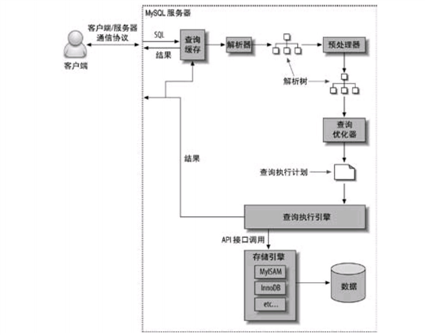
1. 客户端发送一条查询给服务器。
2. 服务器先检查查询缓存,如果命中了缓存,则立刻返回存储在缓存中的结果。否则进入下一阶段。
3. 服务器端进行SQL解析、预处理,再由优化器生成对应的执行计划。
4. MySQL根据优化器生成的执行计划,调用存储引擎的API来执行查询。
5. 将结果返回给客户端。
MySQL客户端/服务器通信协议
MySQL客户端和服务器之间的通信协议是“半双工”的。意味着,在任意时刻,要么服务器向客户端发送数据,要么客户端向服务端发送数据,两个动作不能同时进行。
多数连接mysql的库函数都可以获得全部结果集并缓存到内存中,还可以逐行获取需要的数据,默认是一般将获得全部结果集并缓存到内存后中.mysql通常会等到所有数据发送客户端才释放链接,所以接受结果全部缓存可以减少服务器压力,让查询早点结束,早点释放资源但使用内存又会带来另一个问题,因为库函数需要花很多时间和内存储存所有结果。
查询状态
SHOW FULL PROCESSLIST
Sleep
线程正在等待客户端发送新的请求。
Query
线程正在执行查询或者正在将结果发送给客户端。
Locked
在MySQL服务器层,该线程正在等待表锁。在存储引擎级别实现的锁,例如InnoDB的行锁,并不会体现在线程状态中。对于MyISAM来说这是一个比较典型的状态,但在其他没有行锁的引擎中也经常会出现。
Analyzing and statistics
线程正在收集存储引擎的统计信息,并生成查询的执行计划。
The thread is
线程正在对结果集进行排序。
Sending data
这表示多种情况:线程可能在多个状态之间传送数据,或者在生成结果集,或者在向客户端返回数据。
查询优化处理
重新定义关联表的顺序,将外连接转换内连接,使用等价变换规则,优化count() min() max(),预估并转化为常数表达式,使用覆盖索引扫描,子查询优化,提前终止查询,等值传播,列表in()比较
优化特定类型的查询
优化COUNT()查询
COUNT() 是一个特殊的函数,有两种非常不同的作用:它可以统计某个列值的数量,也可以统计行数。在统计列值时要求列值是非空的(不统计NULL )。如果在COUNT() 的括号中指定了列或者列的表达式,则统计的就是这个表达式有值的结果数
通常来说,COUNT() 都需要扫描大量的行(意味着要访问大量数据)才能获得精确的结果,因此是很难优化的。除了前面的方法,在MySQL层面还能做的就只有索引覆盖扫描了。如果这还不够,就需要考虑修改应用的架构,可以增加汇总表,或者增加类Memcached 这样的外部缓存系统。
优化关联查询
确保ON 或者USING 子句中的列上有索引。在创建索引的时候就要考虑到关联的顺序。当表A 和表B 用列c 关联的时候,如果优化器的关联顺序是B、A ,那么就不需要在B表的对应列上建上索引。没有用到的索引只会带来额外的负担。一般来说,除非有其他理由,否则只需要在关联顺序中的第二个表的相应列上创建索引。
确保任何的GROUP BY 和ORDER BY 中的表达式只涉及到一个表中的列,这样MySQL才有可能使用索引来优化这个过程。
当升级MySQL的时候需要注意:关联语法、运算符优先级等其他可能会发生变化的地方。因为以前是普通关联的地方可能会变成笛卡儿积,不同类型的关联可能会生成不同的结果等。
优化子查询
MySQL5.6或更新的版本或者MariaDB之前版本,尽可能使用关联查询代替。
优化GROUP BY 和DISTINCT
group by 通常使用查找表的标识进行分组效率更高
优化LIMIT分页
当偏移量特别大时,性能有很大影响
1.尽可能利用覆盖索引
2.尽可能转换成已知位置
3.通过主键id能确认更好