标签:ica 包括 查询语句 ref 文件 sch 崩溃恢复 数据恢复 mic
mysql -h$ip -P$port -u$user -p
查看命令:
show processlist;
空闲状态显示为sleep
长连接和短连接:
长连接的问题:
有些时候 MySQL 占用内存涨得特别快,这是因为 MySQL 在执行过程中临时使用的内存是管理在连接对象里面的。这些资源会在连接断开的时候才释放。所以如果长连接累积下来,可能导致内存占用太大,被系统强行杀掉(OOM),从现象看就是 MySQL 异常重启了
解决方案:
原理:
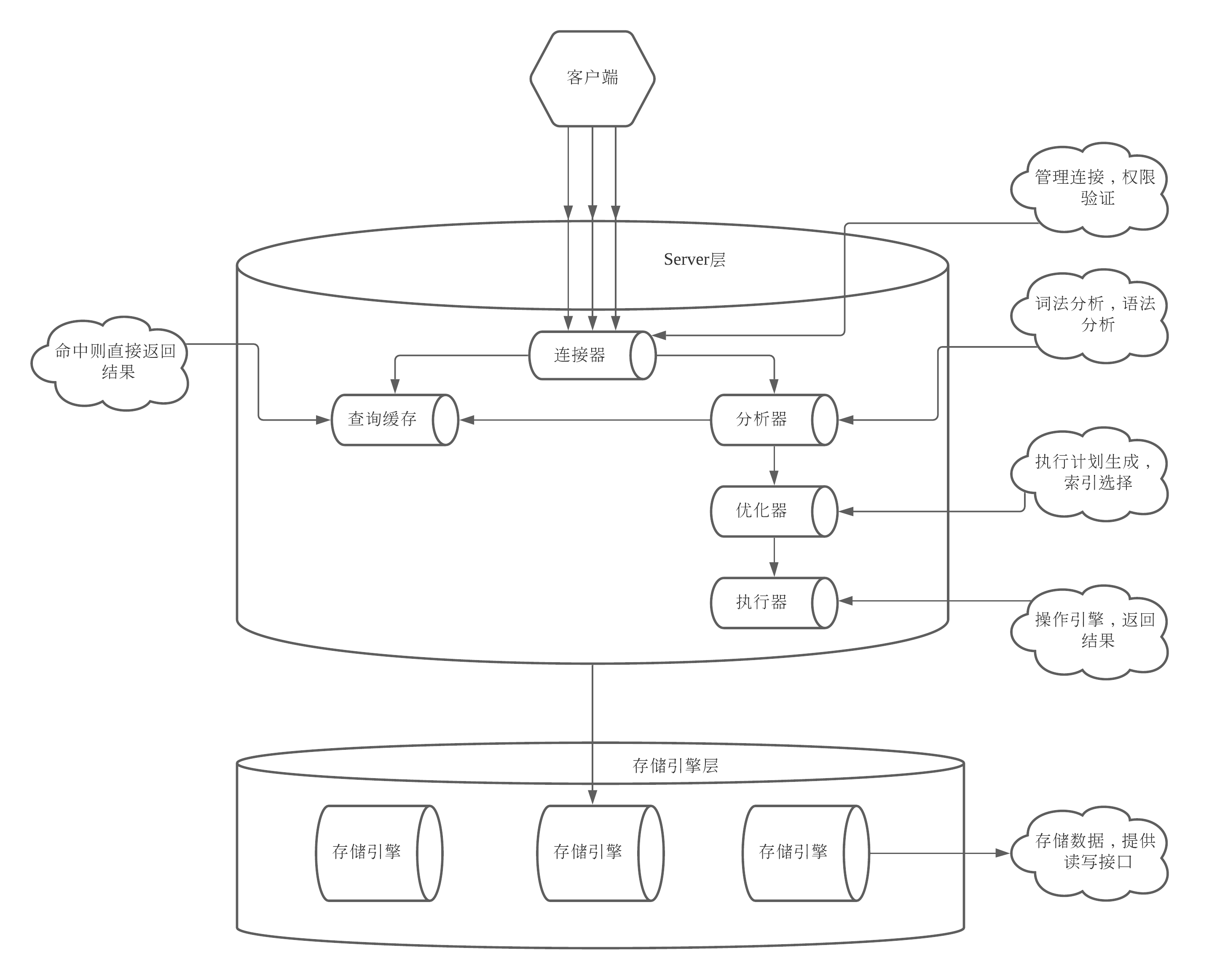
MySQL 拿到一个查询请求后,会先到查询缓存看看,之前是不是执行过这条语句。之前执行过的语句及其结果可能会以 key-value 对的形式,被直接缓存在内存中。key 是查询的语句,value 是查询的结果。如果你的查询能够直接在这个缓存中找到 key,那么这个 value 就会被直接返回给客户端
如果语句不在查询缓存中,就会继续后面的执行阶段。执行完成后,执行结果会被存入查询缓存中。你可以看到,如果查询命中缓存,MySQL 不需要执行后面的复杂操作,就可以直接返回结果,这个效率会很高
查询缓存的问题:
mysql> select SQL_CACHE * from T where ID=10;
适用场景:
你输入的是由多个字符串和空格组成的一条 SQL 语句,MySQL 需要识别出里面的字符串分别是什么,代表什么
MySQL 从你输入的"select"这个关键字识别出来,这是一个查询语句。它也要把字符串“T”识别成“表名 T”,把字符串“ID”识别成“列 ID”
根据词法分析的结果,语法分析器会根据语法规则,判断你输入的这个 SQL 语句是否满足 MySQL 语法
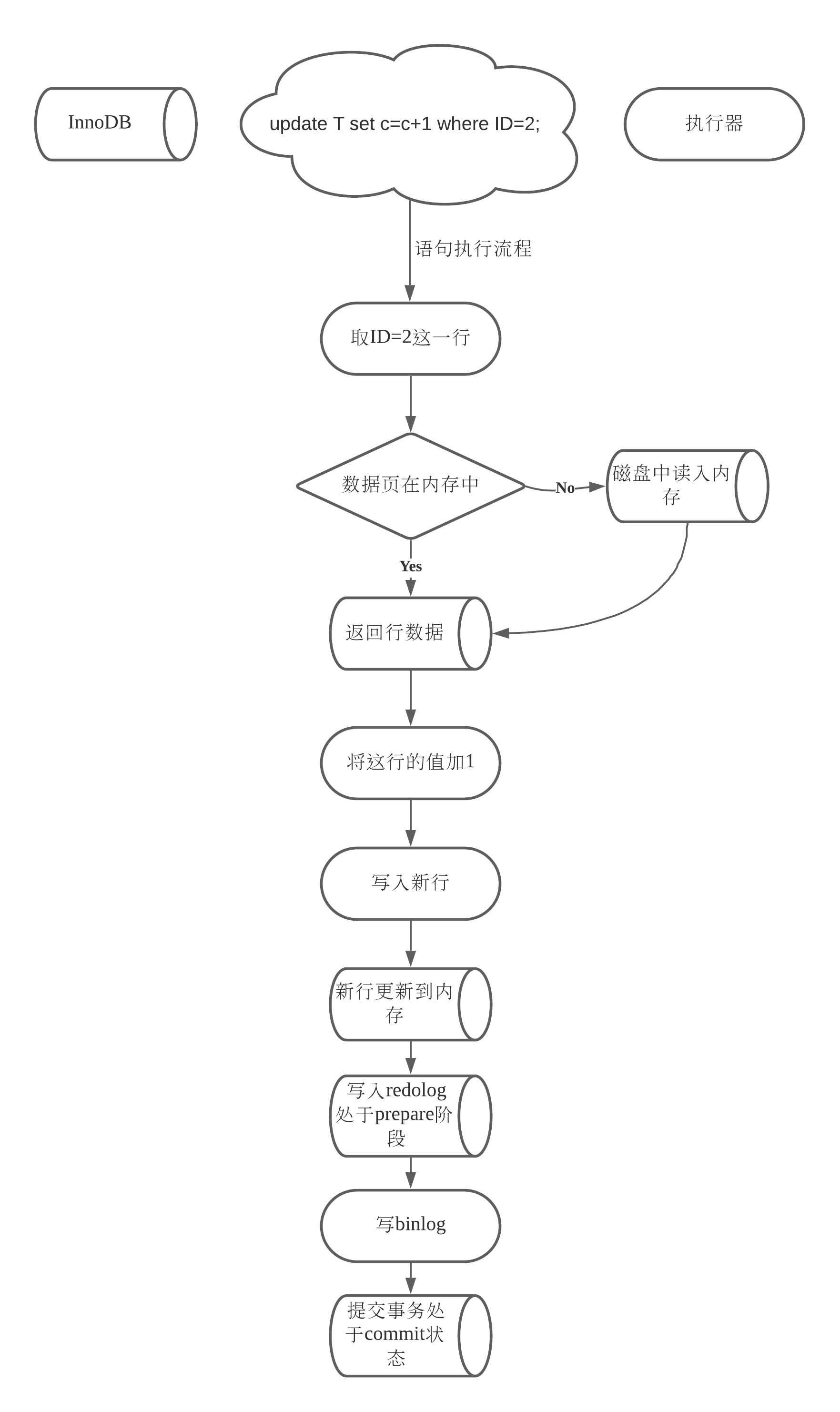
执行器执行流程(没有索引):
调用 InnoDB 引擎接口取这个表的第一行,判断 ID 值是不是 10,如果不是则跳过,如果是则将这行存在结果集中;
调用引擎接口取“下一行”,重复相同的判断逻辑,直到取到这个表的最后一行。
执行器将上述遍历过程中所有满足条件的行组成的记录集作为结果集返回给客户端。
执行器执行流程(有索引):
第一次调用的是“取满足条件的第一行”这个接口
之后循环取“满足条件的下一行”这个接口,这些接口都是引擎中已经定义好的。
更新流程除了查询流程还有两个日志模块:
目的:
如果每一次的更新操作都需要写进磁盘,然后磁盘也要找到对应的那条记录,然后再更新,整个过程 IO 成本、查找成本都很高
WAL技术 (Write-Ahead Logging)
redo log是固定大小,从头开始写,写到末尾就又回到开头循环写
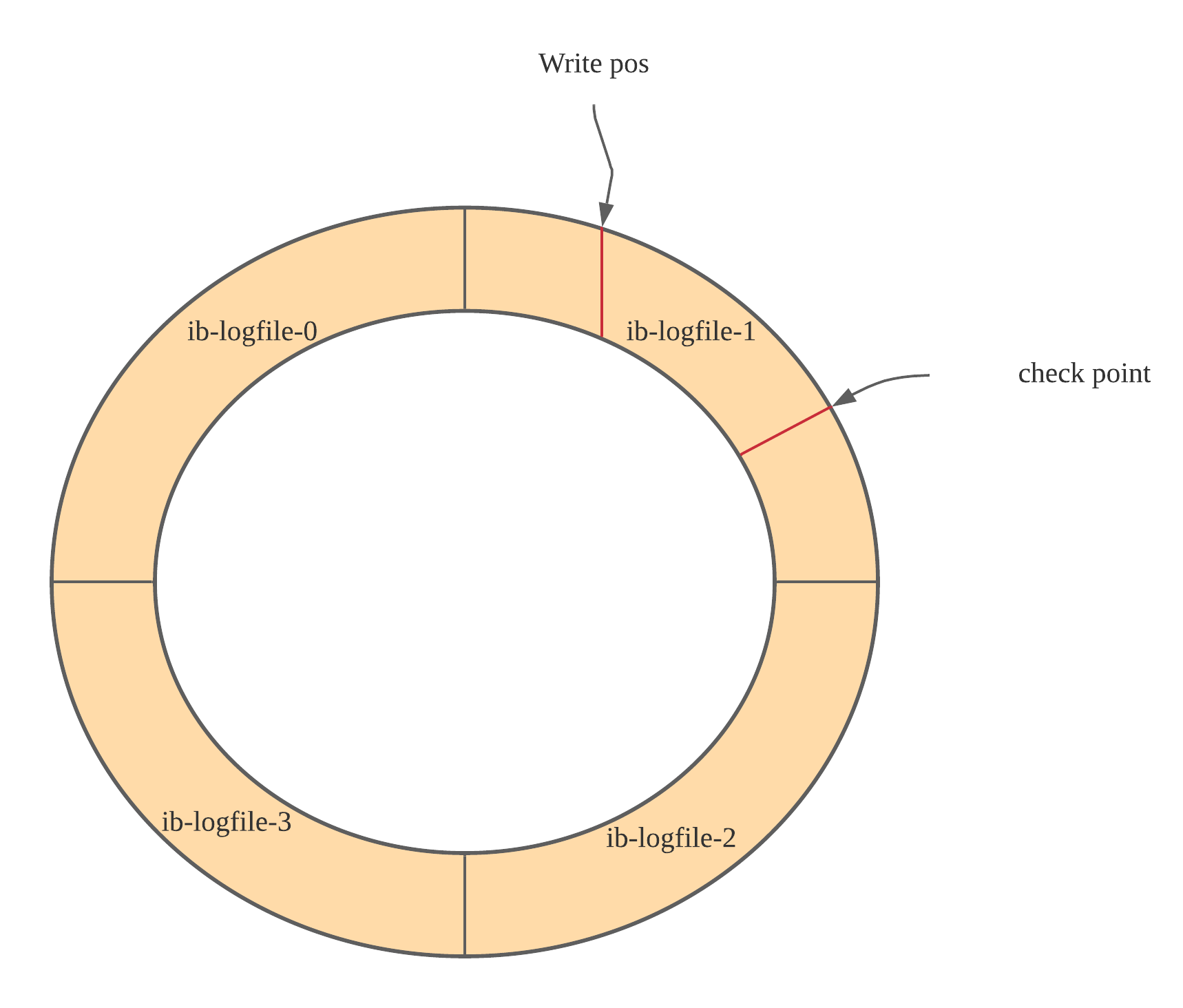
write pos 是当前记录的位置,一边写一边后移,写到第 3 号文件末尾后就回到 0 号文件开头
checkpoint 是当前要擦除的位置,也是往后推移并且循环的,擦除记录前要把记录更新到数据文件
红线之间的部分是空闲的空间,可以用来记录新的操作
如果 write pos 追上 checkpoint,不能再执行新的操作,需要先擦掉一些记录并推进checkpoint
这种设计可能会带来的问题:
设计解决方案:
Crash-safe - InnoDB依靠redo log可以保证即使数据库发生异常重启,之前提交的记录都不会丢失
innodb_flush_log_at_trx_commit 这个参数设置成 1 的时候,表示每次事务的 redo log 都直接持久化到磁盘 - 保证 MySQL 异常重启之后数据不丢失
为什么有两种日志:
因为最开始 MySQL 里并没有 InnoDB 引擎。MySQL 自带的引擎是 MyISAM,但是 MyISAM 没有 crash-safe 的能力,binlog 日志只能用于归档。而 InnoDB 是另一个公司以插件形式引入 MySQL 的,既然只依靠 binlog 是没有 crash-safe 能力的,所以 InnoDB 使用另外一套日志系统——也就是 redo log 来实现 crash-safe 能力
sync_binlog 这个参数设置成 1 的时候,表示每次事务的 binlog 都持久化到磁盘 - 保证 MySQL 异常重启之后 binlog 不丢失
REDO的写盘时间会直接影响系统吞吐,显而易见,REDO的数据量要尽量少。其次,系统崩溃总是发生在始料未及的时候,当重启重放REDO时,系统并不知道哪些REDO对应的Page已经落盘,因此REDO的重放必须可重入,即REDO操作要保证幂等。最后,为了便于通过并发重放的方式加快重启恢复速度,REDO应该是基于Page的,即一个REDO只涉及一个Page的修改。 熟悉的读者会发现,数据量小是Logical Logging的优点,而幂等以及基于Page正是Physical Logging的优点,因此InnoDB采取了一种称为Physiological Logging的方式,来兼得二者的优势。所谓Physiological Logging,就是以Page为单位,但在Page内以逻辑的方式记录。举个例子,MLOG_REC_UPDATE_IN_PLACE类型的REDO中记录了对Page中一个Record的修改,方法如下: (Page ID,Record Offset,(Filed 1, Value 1) ... (Filed i, Value i) ... ) 其中,PageID指定要操作的Page页,Record Offset记录了Record在Page内的偏移位置,后面的Field数组,记录了需要修改的Field以及修改后的Value
整库备份+binlog:
为了让两份日志之间的逻辑一致
先写 redo log 后写 binlog。假设在 redo log 写完,binlog 还没有写完的时候,MySQL 进程异常重启。由于我们前面说过的,redo log 写完之后,系统即使崩溃,仍然能够把数据恢复回来,所以恢复后这一行 c 的值是 1。但是由于 binlog 没写完就 crash 了,这时候 binlog 里面就没有记录这个语句。因此,之后备份日志的时候,存起来的 binlog 里面就没有这条语句。然后你会发现,如果需要用这个 binlog 来恢复临时库的话,由于这个语句的 binlog 丢失,这个临时库就会少了这一次更新,恢复出来的这一行 c 的值就是 0,与原库的值不同
先写 binlog 后写 redo log。如果在 binlog 写完之后 crash,由于 redo log 还没写,崩溃恢复以后这个事务无效,所以这一行 c 的值是 0。但是 binlog 里面已经记录了“把 c 从 0 改成 1”这个日志。所以,在之后用 binlog 来恢复的时候就多了一个事务出来,恢复出来的这一行 c 的值就是 1,与原库的值不同
标签:ica 包括 查询语句 ref 文件 sch 崩溃恢复 数据恢复 mic
原文地址:https://www.cnblogs.com/pengc931482/p/13896457.html