标签:span nbsp 转储 bsp 字节 逻辑 ima 应该 读取
人类使用文本,计算机使用字节序列
python3明确区分了人类可读的文本字符串和原始的字节序列。隐式地把字节序列转换成Unicode文本已成为过去。
把码位转换为字节序列的过程是编码,把字节序列转换成码位的过程是解码。
编码和解码
1 >>> s = "hello world" 2 >>> len(s) 3 11 4 >>> b = s.encode(‘utf8‘) 5 >>> b 6 b‘hello world‘ 7 >>> len(b) 8 11 9 >>> b.decode(‘utf8‘) 10 ‘hello world‘ 11 >>>
decode()和encode()的区别
可以把字节序列想成是晦涩难懂的机器磁芯转储,把Unicode字符串想象成‘人类可读’的文本。把字节序列变成人类可读的文本字符串就是解码,把字符串变成用于存储或者传输的字节序列就是编码。
处理文本文件
处理文本的最佳实践是"Unicode三明治".
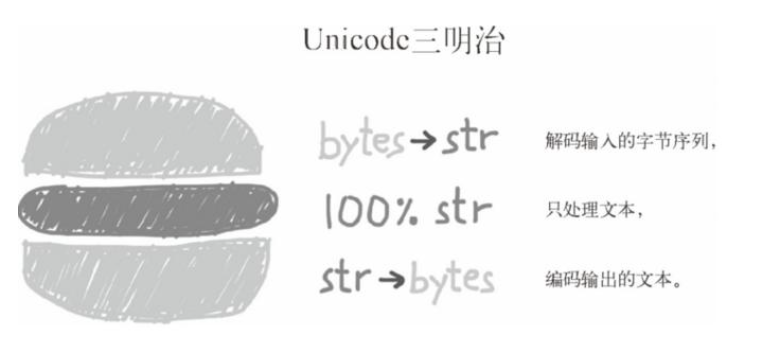
要尽早把输入(例如读取文件)的字节序列解码成字符串
程序的业务逻辑只能处理字符串对象
对输出来说,尽量晚地把字符串编码成字节序列
例如:在Django中,视图应该输出Unicode字符串,Django会负责把响应编码成为字节序列,而且默认使用UTF-8编码。
标签:span nbsp 转储 bsp 字节 逻辑 ima 应该 读取
原文地址:https://www.cnblogs.com/xiebinbbb/p/13767455.html