标签:exe turn ISE end 时间 on() 为什么 快速 client
为 aiohttp 爬虫注入灵魂
摄影:产品经理
与产品经理在苏州的小生活
听说过异步爬虫的同学,应该或多或少听说过aiohttp这个库。它通过 Python 自带的async/await实现了异步爬虫。
使用 aiohttp,我们可以通过 requests 的api写出并发量匹敌 Scrapy 的爬虫。
我们在 aiohttp 的官方文档上面,可以看到它给出了一个代码示例,如下图所示: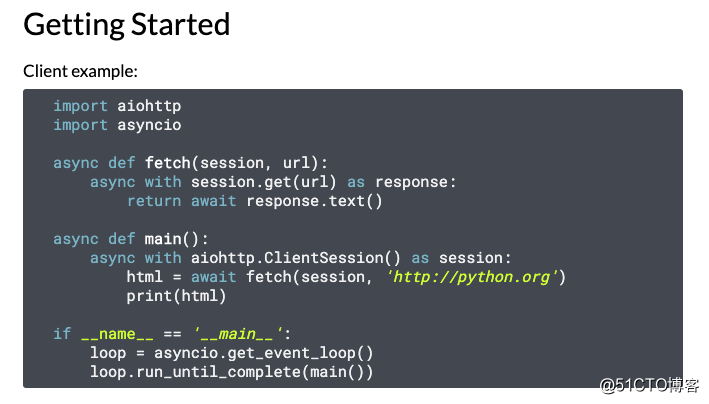
我们现在稍稍修改一下,来看看这样写爬虫,运行效率如何。
修改以后的代码如下:
import asyncio
import aiohttp
template = ‘http://exercise.kingname.info/exercise_middleware_ip/{page}‘
async def get(session, page):
url = template.format(page=page)
resp = await session.get(url)
print(await resp.text(encoding=‘utf-8‘))
async def main():
async with aiohttp.ClientSession() as session:
for page in range(100):
await get(session, page)
loop = asyncio.get_event_loop()
loop.run_until_complete(main())这段代码访问我的爬虫练习站100次,获取100页的内容。
大家可以通过下面这个视频看看它的运行效率:
可以说,目前这个运行速度,跟 requests 写的单线程爬虫几乎没有区别,代码还多了那么多。
那么,应该如何正确释放 aiohttp 的超能力呢?
我们现在把代码做一下修改:
import asyncio
import aiohttp
template = ‘http://exercise.kingname.info/exercise_middleware_ip/{page}‘
async def get(session, queue):
while True:
try:
page = queue.get_nowait()
except asyncio.QueueEmpty:
return
url = template.format(page=page)
resp = await session.get(url)
print(await resp.text(encoding=‘utf-8‘))
async def main():
async with aiohttp.ClientSession() as session:
queue = asyncio.Queue()
for page in range(1000):
queue.put_nowait(page)
tasks = []
for _ in range(100):
task = get(session, queue)
tasks.append(task)
await asyncio.wait(tasks)
loop = asyncio.get_event_loop()
loop.run_until_complete(main())在修改以后的代码里面,我让这个爬虫爬1000页的内容,我们来看看下面这个视频。
可以看到,目前这个速度已经可以跟 Scrapy 比一比了。并且大家需要知道,这个爬虫只有1个进程1个线程,它是通过异步的方式达到这个速度的。
那么,修改以后的代码,为什么速度能快那么多呢?
关键的代码,就在:
tasks = []
for _ in range(100):
task = get(session, queue)
tasks.append(task)
await asyncio.wait(tasks)在慢速版本里面,我们只有1个协程在运行。而在现在这个快速版本里面,我们创建了100个协程,并把它提交给asyncio.wait来统一调度。asyncio.wait会在所有协程全部结束的时候才返回。
我们把1000个 URL 放在asyncio.Queue生成的一个异步队列里面,每一个协程都通过 while True 不停从这个异步队列里面取 URL 并进行访问,直到异步队列为空,退出。
当程序运行时,Python 会自动调度这100个协程,当一个协程在等待网络 IO 返回时,切换到第二个协程并发起请求,在这个协程等待返回时,继续切换到第三个协程并发起请求……。程序充分利用了网络 IO 的等待时间,从而大大提高了运行速度。
最后,感谢实习生小河给出的这种加速方案。

标签:exe turn ISE end 时间 on() 为什么 快速 client
原文地址:https://blog.51cto.com/15023263/2558879