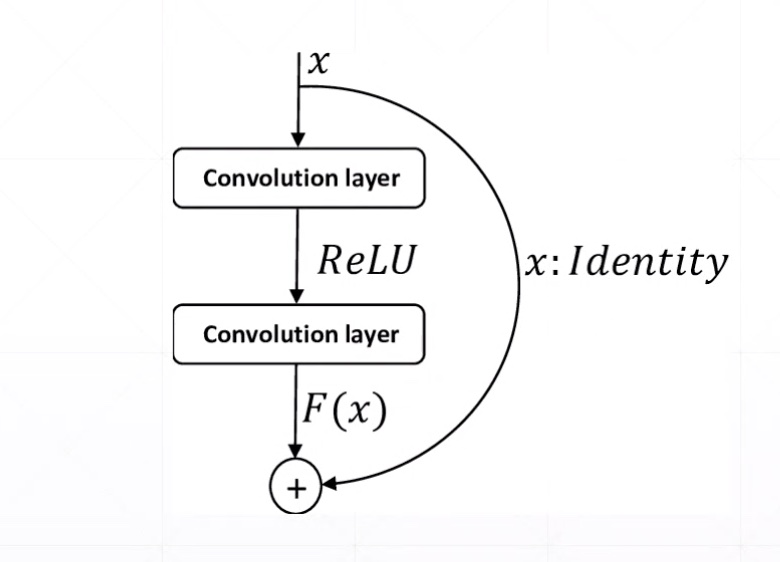
# Resnet.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, Sequential
class BasicBlock(layers.Layer):
def init(self, filter_num, stride=1):
super(BasicBlock, self).init()
self.conv1 = layers.Conv2D(filter_num, (<span class="hljs-number">3</span>, <span class="hljs-number">3</span>), strides=stride, padding=<span class="hljs-string">‘same‘</span>)
self.bn1 = layers.BatchNormalization()
self.relu = layers.Activation(<span class="hljs-string">‘relu‘</span>)
self.conv2 = layers.Conv2D(filter_num, (<span class="hljs-number">3</span>, <span class="hljs-number">3</span>), strides=<span class="hljs-number">1</span>, padding=<span class="hljs-string">‘same‘</span>)
self.bn2 = layers.BatchNormalization()
<span class="hljs-keyword">if</span> stride != <span class="hljs-number">1</span>:
self.downsample = Sequential()
self.downsample.add(layers.Conv2D(filter_num, (<span class="hljs-number">1</span>, <span class="hljs-number">1</span>), strides=stride))
<span class="hljs-keyword">else</span>:
self.downsample = <span class="hljs-keyword">lambda</span> x: x
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">call</span>(<span class="hljs-params">self, inputs, training=<span class="hljs-literal">None</span></span>):</span>
<span class="hljs-comment"># [b,h,w,c]</span>
out = self.conv1(inputs)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
identity = self.downsample(inputs)
output = layers.add([out, identity])
output = tf.nn.relu(output)
<span class="hljs-keyword">return</span> out
Res Block
ResNet18
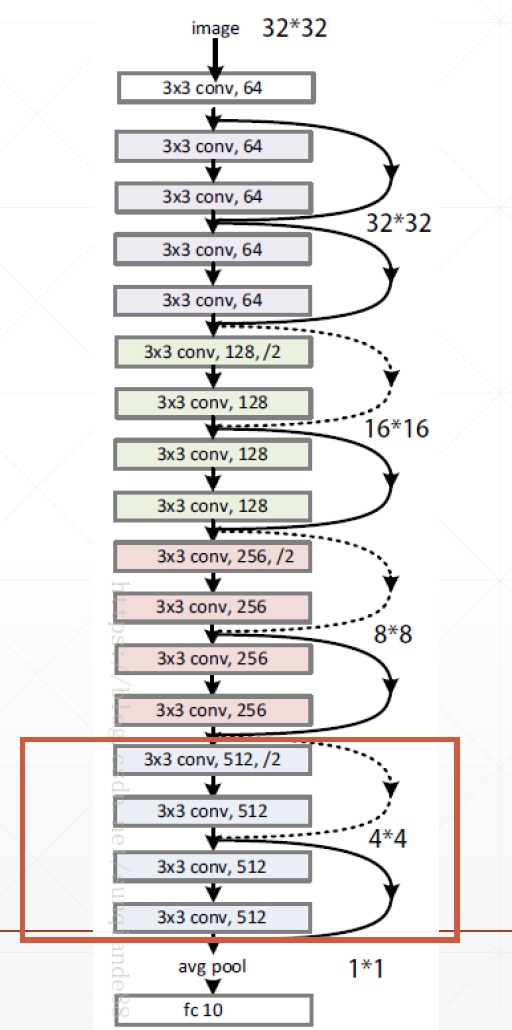
# Resnet.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, Sequential
class BasicBlock(layers.Layer):
def init(self, filter_num, stride=1):
super(BasicBlock, self).init()
self.conv1 = layers.Conv2D(filter_num, (<span class="hljs-number">3</span>, <span class="hljs-number">3</span>), strides=stride, padding=<span class="hljs-string">‘same‘</span>)
self.bn1 = layers.BatchNormalization()
self.relu = layers.Activation(<span class="hljs-string">‘relu‘</span>)
self.conv2 = layers.Conv2D(filter_num, (<span class="hljs-number">3</span>, <span class="hljs-number">3</span>), strides=<span class="hljs-number">1</span>, padding=<span class="hljs-string">‘same‘</span>)
self.bn2 = layers.BatchNormalization()
<span class="hljs-keyword">if</span> stride != <span class="hljs-number">1</span>:
self.downsample = Sequential()
self.downsample.add(layers.Conv2D(filter_num, (<span class="hljs-number">1</span>, <span class="hljs-number">1</span>), strides=stride))
<span class="hljs-keyword">else</span>:
self.downsample = <span class="hljs-keyword">lambda</span> x: x
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">call</span>(<span class="hljs-params">self, inputs, training=<span class="hljs-literal">None</span></span>):</span>
<span class="hljs-comment"># [b,h,w,c]</span>
out = self.conv1(inputs)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
identity = self.downsample(inputs)
output = layers.add([out, identity])
output = tf.nn.relu(output)
<span class="hljs-keyword">return</span> out
class ResNet(keras.Model):
def init(self, layer_dims, num_classes=100): # [2,2,2,2]
super(ResNet, self).init()
<span class="hljs-comment"># 根部</span>
self.stem = Sequential([layers.Conv2D(<span class="hljs-number">64</span>, (<span class="hljs-number">3</span>, <span class="hljs-number">3</span>), strides=(<span class="hljs-number">1</span>, <span class="hljs-number">1</span>,)),
layers.BatchNormalization(),
layers.Activation(<span class="hljs-string">‘relu‘</span>),
layers.MaxPool2D(pool_size=(<span class="hljs-number">2</span>, <span class="hljs-number">2</span>), strides=(<span class="hljs-number">1</span>, <span class="hljs-number">1</span>), padding=<span class="hljs-string">‘same‘</span>)
])
<span class="hljs-comment"># 64,128,256,512是通道数</span>
self.layer1 = self.build_resblock(<span class="hljs-number">64</span>, layer_dims[<span class="hljs-number">0</span>])
self.layer2 = self.build_resblock(<span class="hljs-number">128</span>, layer_dims[<span class="hljs-number">1</span>], stride=<span class="hljs-number">2</span>)
self.layer3 = self.build_resblock(<span class="hljs-number">256</span>, layer_dims[<span class="hljs-number">2</span>], stride=<span class="hljs-number">2</span>)
self.layer4 = self.build_resblock(<span class="hljs-number">512</span>, layer_dims[<span class="hljs-number">3</span>], stride=<span class="hljs-number">2</span>)
<span class="hljs-comment"># output: [b, 512, h, w]</span>
self.avgpool = layers.GlobalAveragePooling2D()
self.fc = layers.Dense(num_classes) <span class="hljs-comment"># 分类</span>
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">call</span>(<span class="hljs-params">self, inputs, training=<span class="hljs-literal">None</span></span>):</span>
x = self.stem(inputs)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
<span class="hljs-comment"># [b, c]</span>
x = self.avgpool(x)
<span class="hljs-comment"># [b]</span>
x = self.fc(x)
<span class="hljs-keyword">return</span> x
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">build_resblock</span>(<span class="hljs-params">self, filter_num, blocks, stride=<span class="hljs-number">1</span></span>):</span>
res_blocks = Sequential()
<span class="hljs-comment"># may down sample</span>
res_blocks.add(BasicBlock(filter_num, stride))
<span class="hljs-keyword">for</span> _ <span class="hljs-keyword">in</span> <span class="hljs-built_in">range</span>(<span class="hljs-number">1</span>, blocks):
res_blocks.add(BasicBlock(filter_num, stride=<span class="hljs-number">1</span>))
<span class="hljs-keyword">return</span> res_blocks
def resnet18():
return ResNet([2, 2, 2, 2])
def resnet34():
return ResNet([3, 4, 6, 3])
# resnet18_train.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import tensorflow as tf
from tensorflow.keras import layers, optimizers, datasets, Sequential
import os
from Resnet import resnet18
os.environ[‘TF_CPP_MIN_LOG_LEVEL‘] = ‘2‘
tf.random.set_seed(2345)
def preprocess(x, y):
# [-1~1]
x = tf.cast(x, dtype=tf.float32) / 255. - 0.5
y = tf.cast(y, dtype=tf.int32)
return x, y
(x, y), (x_test, y_test) = datasets.cifar100.load_data()
y = tf.squeeze(y, axis=1)
y_test = tf.squeeze(y_test, axis=1)
print(x.shape, y.shape, x_test.shape, y_test.shape)
train_db = tf.data.Dataset.from_tensor_slices((x, y))
train_db = train_db.shuffle(1000).map(preprocess).batch(512)
test_db = tf.data.Dataset.from_tensor_slices((x_test, y_test))
test_db = test_db.map(preprocess).batch(512)
sample = next(iter(train_db))
print(‘sample:‘, sample[0].shape, sample[1].shape,
tf.reduce_min(sample[0]), tf.reduce_max(sample[0]))
def main():
# [b, 32, 32, 3] => [b, 1, 1, 512]
model = resnet18()
model.build(input_shape=(None, 32, 32, 3))
model.summary()
optimizer = optimizers.Adam(lr=1e-3)
for epoch in range(500):
for step, (x, y) in enumerate(train_db):
with tf.GradientTape() as tape:
# [b, 32, 32, 3] => [b, 100]
logits = model(x)
# [b] => [b, 100]
y_onehot = tf.one_hot(y, depth=100)
# compute loss
loss = tf.losses.categorical_crossentropy(y_onehot, logits, from_logits=True)
loss = tf.reduce_mean(loss)
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
if step % 50 == 0:
print(epoch, step, ‘loss:‘, float(loss))
total_num = 0
total_correct = 0
for x, y in test_db:
logits = model(x)
prob = tf.nn.softmax(logits, axis=1)
pred = tf.argmax(prob, axis=1)
pred = tf.cast(pred, dtype=tf.int32)
correct = tf.cast(tf.equal(pred, y), dtype=tf.int32)
correct = tf.reduce_sum(correct)
total_num += x.shape[0]
total_correct += int(correct)
acc = total_correct / total_num
print(epoch, ‘acc:‘, acc)
if __name__ == ‘__main__‘:
main()
(50000, 32, 32, 3) (50000,) (10000, 32, 32, 3) (10000,)
sample: (512, 32, 32, 3) (512,) tf.Tensor(-0.5, shape=(), dtype=float32) tf.Tensor(0.5, shape=(), dtype=float32)
Model: "res_net"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
sequential (Sequential) multiple 2048
_________________________________________________________________
sequential_1 (Sequential) multiple 148736
_________________________________________________________________
sequential_2 (Sequential) multiple 526976
_________________________________________________________________
sequential_4 (Sequential) multiple 2102528
_________________________________________________________________
sequential_6 (Sequential) multiple 8399360
_________________________________________________________________
global_average_pooling2d (Gl multiple 0
_________________________________________________________________
dense (Dense) multiple 51300
=================================================================
Total params: 11,230,948
Trainable params: 11,223,140
Non-trainable params: 7,808
_________________________________________________________________
WARNING: Logging before flag parsing goes to stderr.
W0601 16:59:57.619546 4664264128 optimizer_v2.py:928] Gradients does not exist for variables [‘sequential_2/basic_block_2/sequential_3/conv2d_7/kernel:0‘, ‘sequential_2/basic_block_2/sequential_3/conv2d_7/bias:0‘, ‘sequential_4/basic_block_4/sequential_5/conv2d_12/kernel:0‘, ‘sequential_4/basic_block_4/sequential_5/conv2d_12/bias:0‘, ‘sequential_6/basic_block_6/sequential_7/conv2d_17/kernel:0‘, ‘sequential_6/basic_block_6/sequential_7/conv2d_17/bias:0‘] when minimizing the loss.
0 0 loss: 4.60512638092041
Out of memory
-
- decrease batch size
-
- tune resnet[2,2,2,2]
-
- try Google CoLab
-
- buy new NVIDIA GPU Card