标签:sea dsa 替代 print dal tag intel 小数 files
import re
text = "我一把把把把住了,tom差点就掉下去了,tom得救了"
data_list = re.findall(‘tom‘,text)
print(data_list)
[‘tom‘, ‘tom‘]
import re
text = "我一把把把把住了,tom差点就掉下去了,tom得救了"
data_list = re.findall(‘[把t救]‘,text)
print(data_list)
[‘把‘, ‘把‘, ‘把‘, ‘把‘, ‘t‘, ‘t‘, ‘救‘]
import re
text = "我一把把把把住了,tom差点就掉下去了,tom得救了"
data_list = re.findall(‘得[把t救]‘,text)
print(data_list)
[‘得救‘]
import re
text = "我一把把把把住了,tom差点就掉下去了,tom得救了"
data_list = re.findall(‘[^把t救]‘,text)
print(data_list)
[‘我‘, ‘一‘, ‘住‘, ‘了‘, ‘,‘, ‘o‘, ‘m‘, ‘差‘, ‘点‘, ‘就‘, ‘掉‘, ‘下‘, ‘去‘, ‘了‘, ‘,‘, ‘o‘, ‘m‘, ‘得‘, ‘了‘]
import re
text = "我一把把把把住了,tom差点就掉下去了,Tom得9了"
data_list = re.findall(‘[a-z0-9A-Z]‘,text)
print(data_list)
[‘t‘, ‘o‘, ‘m‘, ‘T‘, ‘o‘, ‘m‘, ‘9‘]
import re
text = "我一把把把把住了,tom差点就掉下去了,tom得9了"
data_list = re.findall(‘t.m‘,text)
print(data_list)
[‘tom‘, ‘tom‘]
import re
text = "我一把把把把住了,tom差点就掉下去了,tom得9了"
data_list = re.findall(‘t.+m‘,text) # 贪婪匹配,尽可能长的匹配
print(data_list)
[‘tom差点就掉下去了,tom‘]
import re
text = "我一把把把把住了,tom差点就掉下去了,tom得9了"
data_list = re.findall(‘t.+?m‘,text) # 非贪婪匹配,尽可能短的匹配
print(data_list)
[‘tom‘, ‘tom‘]
import re
text = "我一把把把把住了_ tom差点就掉下去了tom得9了"
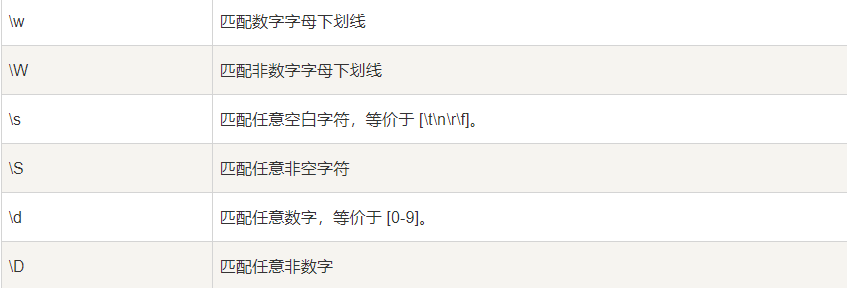
data_list = re.findall(‘\w+‘,text)
print(data_list)
[‘我一把把把把住了_‘, ‘tom差点就掉下去了tom得9了‘]
import re
text = "我一把把把把住了_ tom差点就掉下去了tom得9了"
data_list = re.findall(‘\w+‘,text,re.ASCII) # re.ASCII不匹配汉字
print(data_list)
[‘_‘, ‘tom‘, ‘tom‘, ‘9‘]
import re
text = "我一把把把把住了_ tom差点就掉下 去了tom得9了"
data_list = re.findall(‘t\w+\s\w+‘,text)
print(data_list)
[‘tom差点就掉下 去了tom得9了‘]
import re
text = "我一把把把把住了_ @$$$~tom差点就掉下去了tom得9了"
data_list = re.findall(‘\S+‘,text)
print(data_list)
[‘我一把把把把住了_‘, ‘@$$$~tom差点就掉下去了tom得9了‘]
import re
text = "我一把88把住了tom差点就掉下去了tom得9了"
data_list = re.findall(‘\d+‘,text)
print(data_list)
[‘88‘, ‘9‘]
import re
text = "我一把把把把住了tom差点就掉下去了,后来就住在一起了"
data_list = re.findall(‘把*住‘,text)
print(data_list)
[‘把把把把住‘, ‘住‘]
import re
text = "我一把把把把住了tom差点就掉下去了,后来就住在一起了"
data_list = re.findall(‘把+住‘,text)
print(data_list)
[‘把把把把住‘]
import re
text = "我一把把把把住了tom差点就掉下去了,后来就住在一起了"
data_list = re.findall(‘把?住‘,text)
print(data_list)
[‘把住‘, ‘住‘]
import re
text = "我一把把把把住了tom差点就掉下去了,后来就住在一起了"
data_list = re.findall(‘把{2}住‘,text)
print(data_list)
[‘把把住‘]
import re
text = "我一把把把把住了tom差点就掉下去了,多亏把住了"
data_list = re.findall(‘把{1,}住‘,text)
print(data_list)
[‘把把把把住‘, ‘把住‘]
import re
text = "我一把把把把住了tom差点就掉下去了,多亏把住了"
data_list = re.findall(‘把{1,2}住‘,text)
print(data_list)
[‘把把住‘, ‘把住‘]
import re
text = "我的qq邮箱是10002000@163.com现在需要向leishen@126.com邮箱发邮件"
data_list = re.findall(‘(\w+(@\w+\.\w+))‘,text,re.ASCII)
print(data_list)
[(‘10002000@163.com‘, ‘@163.com‘), (‘leishen@126.com‘, ‘@126.com‘)]
import re
text = "我的qq邮箱是10002000@163.com现在需要向leishen@126.com邮箱发邮件,我还有555@88.cn"
data_list = re.findall(‘(\w+@(163\.\w+|88\.\w+))‘,text,re.ASCII)
print(data_list)
[(‘10002000@163.com‘, ‘163.com‘), (‘555@88.cn‘, ‘88.cn‘)]
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
import re
print(re.match(‘www‘, ‘www.runoob.com‘)) # 在起始位置匹配
print(re.match(‘com‘, ‘www.runoob.com‘)) # 不在起始位置匹配
print(re.match(‘www‘, ‘www.runoob.com‘).group())
<_sre.SRE_Match object; span=(0, 3), match=‘www‘>
None
www
re.search 扫描整个字符串并返回第一个成功的匹配。
import re
print(re.search(‘www‘, ‘www.runoob.com‘).span()) # 在起始位置匹配
print(re.search(‘com‘, ‘www.runoob.com‘).span()) # 不在起始位置匹配
(0, 3)
(11, 14)
Python 的re模块提供了re.sub用于替换字符串中的匹配项。
import re
phone = "2004-959-559 # 这是一个电话号码"
# 删除注释
num = re.sub(r‘#.*$‘, "", phone)
print ("电话号码 : ", num)
num = re.sub(r‘\D‘, "", phone)
print ("电话号码 : ", num)
电话号码 : 2004-959-559
电话号码 : 2004959559
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。
注意: match 和 search 是匹配一次 findall 匹配所有。
import re
result1 = re.findall(r‘\w+‘,‘runoob_123 google浏览器 456‘)
result1
[‘runoob_123‘, ‘google浏览器‘, ‘456‘]
re.split(‘\s‘,‘hello word 12 231‘)
[‘hello‘, ‘word‘, ‘12‘, ‘231‘]
import re
text = ‘kkkdm41018519960222192809998098dsabfkbdfas98393119880329933x4whfqehf‘
context = re.finditer(‘\d{6}(?P<年>\d{4})(?P<月>\d{2})(?P<日>\d{2})\d{3}[\d|xX]‘,text)
for data in context:
print(data.groupdict())
{‘年‘: ‘1996‘, ‘月‘: ‘02‘, ‘日‘: ‘22‘}
{‘年‘: ‘1988‘, ‘月‘: ‘03‘, ‘日‘: ‘29‘}
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。
import re
pattern = re.compile(r‘([a-z]+) ([a-z]+)‘, re.I) # re.I 表示忽略大小写
m = pattern.match(‘Hello World Wide Web‘)
print( m.groups())
(‘Hello‘, ‘World‘)
import requests
import re
headers = {
‘User-Agent‘:‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36‘
}
url = ‘http://sc.chinaz.com/tag_tupian/YaZhouMeiNv.html‘
page_text = requests.get(url,headers=headers).text #获取字符串形式的响应数据
#通过正则进行图片地址的解析
ex = ‘<a.*?<img src2="(.*?)" alt.*?</a>‘
img_src_list = re.findall(ex,page_text,re.S)#re.S处理回车
print(img_src_list)
[‘//scpic1.chinaz.net/Files/pic/pic9/202101/apic30041_s.jpg‘, ‘//scpic1.chinaz.net/Files/pic/pic9/202012/apic29961_s.jpg‘, ‘//scpic1.chinaz.net/Files/pic/pic9/202101/apic30021_s.jpg‘, ‘//scpic1.chinaz.net/Files/pic/pic9/202101/apic30020_s.jpg‘, ‘//scpic1.chinaz.net/Files/pic/pic9/202101/apic30015_s.jpg‘, ‘//scpic1.chinaz.net/Files/pic/pic9/202101/apic30111_s.jpg‘, ‘//scpic1.chinaz.net/Files/pic/pic9/202101/apic30006_s.jpg‘, ‘//scpic1.chinaz.net/Files/pic/pic9/202101/apic29991_s.jpg‘, ]
一、校验数字的表达式
数字:^[0-9]*$
n位的数字:^\d{n}$
至少n位的数字:^\d{n,}$
m-n位的数字:^\d{m,n}$
零和非零开头的数字:^(0|[1-9][0-9]*)$
非零开头的最多带两位小数的数字:^([1-9][0-9]*)+(\.[0-9]{1,2})?$
带1-2位小数的正数或负数:^(\-)?\d+(\.\d{1,2})$
正数、负数、和小数:^(\-|\+)?\d+(\.\d+)?$
有两位小数的正实数:^[0-9]+(\.[0-9]{2})?$
有1~3位小数的正实数:^[0-9]+(\.[0-9]{1,3})?$
非零的正整数:^[1-9]\d*$ 或 ^([1-9][0-9]*){1,3}$ 或 ^\+?[1-9][0-9]*$
非零的负整数:^\-[1-9][]0-9"*$ 或 ^-[1-9]\d*$
非负整数:^\d+$ 或 ^[1-9]\d*|0$
非正整数:^-[1-9]\d*|0$ 或 ^((-\d+)|(0+))$
非负浮点数:^\d+(\.\d+)?$ 或 ^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$
非正浮点数:^((-\d+(\.\d+)?)|(0+(\.0+)?))$ 或 ^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$
正浮点数:^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ 或 ^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$
负浮点数:^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ 或 ^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$
浮点数:^(-?\d+)(\.\d+)?$ 或 ^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$
二、校验字符的表达式
汉字:^[\u4e00-\u9fa5]{0,}$
英文和数字:^[A-Za-z0-9]+$ 或 ^[A-Za-z0-9]{4,40}$
长度为3-20的所有字符:^.{3,20}$
由26个英文字母组成的字符串:^[A-Za-z]+$
由26个大写英文字母组成的字符串:^[A-Z]+$
由26个小写英文字母组成的字符串:^[a-z]+$
由数字和26个英文字母组成的字符串:^[A-Za-z0-9]+$
由数字、26个英文字母或者下划线组成的字符串:^\w+$ 或 ^\w{3,20}$
中文、英文、数字包括下划线:^[\u4E00-\u9FA5A-Za-z0-9_]+$
中文、英文、数字但不包括下划线等符号:^[\u4E00-\u9FA5A-Za-z0-9]+$ 或 ^[\u4E00-\u9FA5A-Za-z0-9]{2,20}$
可以输入含有^%&‘,;=?$\"等字符:[^%&‘,;=?$\x22]+
禁止输入含有~的字符:[^~\x22]+
三、特殊需求表达式
Email地址:^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$
域名:[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(\.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+\.?
InternetURL:[a-zA-z]+://[^\s]* 或 ^http://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$
手机号码:^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$
电话号码("XXX-XXXXXXX"、"XXXX-XXXXXXXX"、"XXX-XXXXXXX"、"XXX-XXXXXXXX"、"XXXXXXX"和"XXXXXXXX):^(\(\d{3,4}-)|\d{3.4}-)?\d{7,8}$
国内电话号码(0511-4405222、021-87888822):\d{3}-\d{8}|\d{4}-\d{7}
电话号码正则表达式(支持手机号码,3-4位区号,7-8位直播号码,1-4位分机号): ((\d{11})|^((\d{7,8})|(\d{4}|\d{3})-(\d{7,8})|(\d{4}|\d{3})-(\d{7,8})-(\d{4}|\d{3}|\d{2}|\d{1})|(\d{7,8})-(\d{4}|\d{3}|\d{2}|\d{1}))$)
身份证号(15位、18位数字),最后一位是校验位,可能为数字或字符X:(^\d{15}$)|(^\d{18}$)|(^\d{17}(\d|X|x)$)
帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
密码(以字母开头,长度在6~18之间,只能包含字母、数字和下划线):^[a-zA-Z]\w{5,17}$
强密码(必须包含大小写字母和数字的组合,不能使用特殊字符,长度在 8-10 之间):^(?=.*\d)(?=.*[a-z])(?=.*[A-Z])[a-zA-Z0-9]{8,10}$
强密码(必须包含大小写字母和数字的组合,可以使用特殊字符,长度在8-10之间):^(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$
日期格式:^\d{4}-\d{1,2}-\d{1,2}
一年的12个月(01~09和1~12):^(0?[1-9]|1[0-2])$
一个月的31天(01~09和1~31):^((0?[1-9])|((1|2)[0-9])|30|31)$
钱的输入格式:
有四种钱的表示形式我们可以接受:"10000.00" 和 "10,000.00", 和没有 "分" 的 "10000" 和 "10,000":^[1-9][0-9]*$
这表示任意一个不以0开头的数字,但是,这也意味着一个字符"0"不通过,所以我们采用下面的形式:^(0|[1-9][0-9]*)$
一个0或者一个不以0开头的数字.我们还可以允许开头有一个负号:^(0|-?[1-9][0-9]*)$
这表示一个0或者一个可能为负的开头不为0的数字.让用户以0开头好了.把负号的也去掉,因为钱总不能是负的吧。下面我们要加的是说明可能的小数部分:^[0-9]+(.[0-9]+)?$
必须说明的是,小数点后面至少应该有1位数,所以"10."是不通过的,但是 "10" 和 "10.2" 是通过的:^[0-9]+(.[0-9]{2})?$
这样我们规定小数点后面必须有两位,如果你认为太苛刻了,可以这样:^[0-9]+(.[0-9]{1,2})?$
这样就允许用户只写一位小数.下面我们该考虑数字中的逗号了,我们可以这样:^[0-9]{1,3}(,[0-9]{3})*(.[0-9]{1,2})?$
1到3个数字,后面跟着任意个 逗号+3个数字,逗号成为可选,而不是必须:^([0-9]+|[0-9]{1,3}(,[0-9]{3})*)(.[0-9]{1,2})?$
备注:这就是最终结果了,别忘了"+"可以用"*"替代如果你觉得空字符串也可以接受的话(奇怪,为什么?)最后,别忘了在用函数时去掉去掉那个反斜杠,一般的错误都在这里
xml文件:^([a-zA-Z]+-?)+[a-zA-Z0-9]+\\.[x|X][m|M][l|L]$
中文字符的正则表达式:[\u4e00-\u9fa5]
双字节字符:[^\x00-\xff] (包括汉字在内,可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1))
空白行的正则表达式:\n\s*\r (可以用来删除空白行)
HTML标记的正则表达式:<(\S*?)[^>]*>.*?|<.*? /> ( 首尾空白字符的正则表达式:^\s*|\s*$或(^\s*)|(\s*$) (可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式)
腾讯QQ号:[1-9][0-9]{4,} (腾讯QQ号从10000开始)
中国邮政编码:[1-9]\d{5}(?!\d) (中国邮政编码为6位数字)
IP地址:((?:(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d)\\.){3}(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d))
标签:sea dsa 替代 print dal tag intel 小数 files
原文地址:https://www.cnblogs.com/tianming66/p/14263178.html