标签:src 时间 png stress 查看 hog pat 百分比 后台进程
[root@VM-4-16-centos ~]#ps -aux USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND root 1 0.0 0.3 43596 3440 ? Ss Jan08 0:16 /usr/lib/systemd/systemd --switched-root --syst root 2 0.0 0.0 0 0 ? S Jan08 0:00 [kthreadd] #----------每个参数表示的意思-------------- USER # 启动进程的用户 PID # 进程运行的ID号 %CPU # 进程占用CPU的百分彼 %MEM # 进程占用内存百分比 VSZ # 进程占用虚拟内存大小(单位KB) RSS # 进程占用物理内存实际大小(单位KB) TTY # 进程是由哪个终端运行启动的tty1、pts/0等 ?表示内核程序与终端无关(远程连接会通过tty打开一个bash:tty) STAT # 进程运行过程中的状态,主要有以下几种状态 ‘‘‘ R #进程运行 S #可中断睡眠 s #进程是控制进行,Ss进程的领导者,也就是父进程 < #高优先级 S< #较高优先级 N #低优先级 SN #较低优先级 T #暂停状态 D #不可中断睡眠 + #进程正在运行 Z #僵尸进程 I #进程是多线程 SI 进程是以线程方式运行 ‘‘‘ START #进程启动时间 TIME #进程占用CPU的总时间 COMMAND #程序的运行指令,[]属于内核态的进程,没有[]的是用户态进程
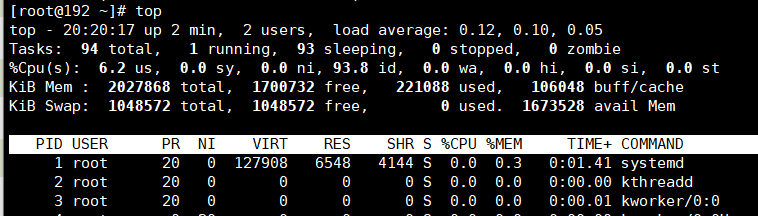
top一些常用指令(top执行后,再执行指令,就可以)
‘‘‘ h # 查看帮助 l # 数字1,显示所有CPU核心的负载 z # 以高亮显示数据 b # 高亮显示处于R(进行中)状态的进程 M # 按内存使用百分比排序输出 P # 按CPU使用百分比排序输出 q # 退出top ‘‘‘
扩展:
# 第三方top htop,top高级:yum install htop -y iftop网卡流量:yum install iftop -y glances,直观的显示:yum install glances -y -rz上传文件,可以动态看到,网卡情况
(1)kill -l 查看系统当前支持的信号
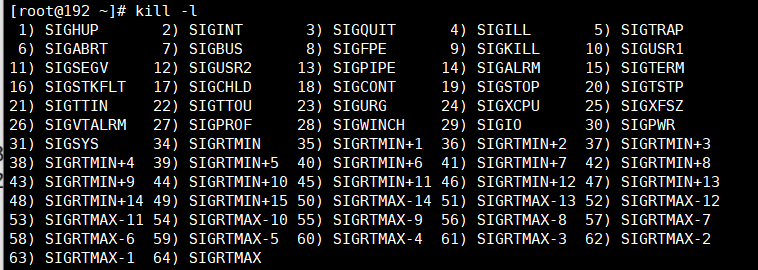
最常用的信号有以下3个信号

# 杀死进程(本质发送终止进程的信号给对应的进程) kill pid # 本质是 kill -15 pid(因为kill默认使用SIGTERM信号量) # 发送信号 kill -信号量 PID # pkill 杀死同名的进程 [root@192 ~]# pkill vi # killall 杀死同名的进程 [root@192 ~]# killall vi # pkill 和 killall 相比于kill 省去了查询哪一步。
# 挂起后台 & [root@192 ~]# sleep 30000 & [root@lqz ~]# jobs #查看后台作业 [1]- Running sleep 3000 & [2]+ Stopped sleep 4000 ‘‘‘ bg # 将进程挂到后台运行 fg # 将进程调回前台 ‘‘‘ [root@lqz ~]# bg %2 #让作业 2 在后台运行 [root@lqz ~]# fg %1 #将作业 1 调回到前台 [root@lqz ~]# kill %1 3kill 1,终止 PID 为 1 的进程
# 1、安装 [root@192 ~]# yum install screen # 2、开启一个screen窗口,指定名字 [root@192 ~]# screen -S wget_mysql # wget_mysql 窗口名字 # 3、在screen窗口中执行任务 [root@192 ~]# sleep 3000 # 4、退出,鼠标滑动/或者平滑退出,注意:使用exit才算关闭窗口 # 5、查看当前正在运行的screen [root@192 ~]# screen -list # 6、进入正在运行的screen [root@192 ~]# screen -r screen名字 [root@192 ~]# screen -r 22058 #22058是screen的id号 # 7、退出/停止是exit或者ctrl+d
进程的优先级可以通过更改进程的nice的值来改变静态优先级,进程的nice值在-20 ~ 19之间,nice值越低,优先级越高。
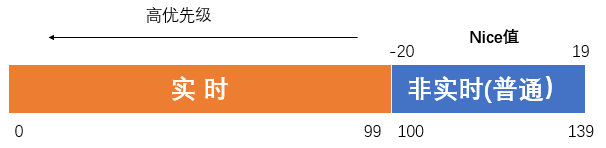
(1)查看进程优先级
# top命令 ‘‘‘ NI:nice值 PR:优先级 ‘‘‘
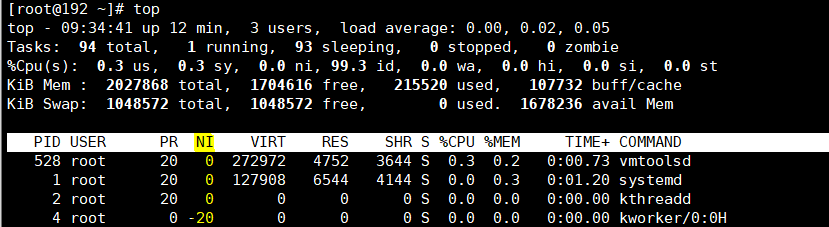
#也可以使用ps查看进程的优先级 [root@192 ~]# ps axo command,nice | grep sshd | grep -v grep # grep -v grep 是去除grep的进程行,避免造成干扰 /usr/sbin/sshd -D 0 sshd: root@pts/0 0 sshd: root@pts/2 0
(2)设置nice值
#命令:nice -n nice值 进程名字 [root@192 ~]# nice -n -10 vi & [1] 1318 [root@192 ~]# ps axo pid,command,nice | grep 1318 #类似数据库查表,只显示表的一部分字段 1318 vi -10 1320 grep --color=auto 1318 0 [1]+ Stopped nice -n -10 vi
(3)修改正在运行进程的优先级
# 命令格式:renice -n 优先级数字 进程pid [root@192 ~]# renice -n -20 1318 1318 (process ID) old priority -11, new priority -20 [root@192 ~]# ps axo pid,command,nice | grep 1318 1318 vi -20 1326 grep --color=auto 1318 0 [root@192 ~]#
平均负载:是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就平均活跃进程数。
cpu的使用率:是指单位时间内cpu使用情况。
平均负载:是单位时间内进程活跃数
如:cpu密集型进程,使用大量cpu会导致平均负载升高
IO密集型进程,等待I/O也会导致平均负载升高,但cpu使用率不一定很高
当大量等待cpu的进程调度也会导致平均负载升高,那么cpu的使用率也会比较高。
总结:两者并没有直接联系。
(1) CPU密集型进程
#1、先模拟一个cpu使用率100%的场景 [root@192 ~]# stress --cpu 1 --timeout 600 stress: info: [1245] dispatching hogs: 1 cpu, 0 io, 0 vm, 0 hdd #2、在另一个终端查看平均负载的变化情况 [root@192 ~]# watch -d uptime #watch -d表示高亮显示变化的区域 Every 2.0s: uptime 17:27:44 up 2 days, 3:11, 3 users, load average: 1.10, 0.30, 0.17 #3、在另一个终端查看cpu的使用率变化情况 # -P ALL 表示监控所有 CPU,后面数字 5 表示间隔 5 秒后输出一组数据 [root@192 ~]# mpstat -P ALL 5 Linux 3.10.0-1160.el7.x86_64 (192.168.92.2.centos) 01/15/2021 _x86_64_ (1 CPU) 08:41:58 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 08:42:03 PM all 96.21 0.00 3.59 0.00 0.00 0.20 0.00 0.00 0.00 0.00 08:42:03 PM 0 96.21 0.00 3.59 0.00 0.00 0.20 0.00 0.00 0.00 0.00 08:42:03 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 08:42:08 PM all 99.80 0.00 0.20 0.00 0.00 0.00 0.00 0.00 0.00 0.00 08:42:08 PM 0 99.80 0.00 0.20 0.00 0.00 0.00 0.00 0.00 0.00 0.00 #4、查看那个进程导致了CPU的使用率为100% [root@192 ~]# pidstat -u 5 1 Linux 3.10.0-1160.el7.x86_64 (192.168.92.2.centos) 01/15/2021 _x86_64_ (1 CPU) 08:43:49 PM UID PID %usr %system %guest %CPU CPU Command 08:43:54 PM 0 1246 98.61 0.00 0.00 98.61 0 stress 08:43:54 PM 0 1247 0.00 0.20 0.00 0.20 0 sshd 08:43:54 PM 0 1270 0.00 0.20 0.00 0.20 0 watch #总结:从上面几个结果可以看出,cpu的使用率100%,但是它的iowait是0,因此可以看出,平均负载慢慢增加是因为cpu使用率升高导致
(2) I/O密集型进程
#1、先模拟一个I/O压力的场景(不停执行sync) [root@192 ~]# stress --io 1 --timeout 600 stress: info: [2428] dispatching hogs: 0 cpu, 1 io, 0 vm, 0 hdd #2、在另一个终端查看平均负载的变化情况 [root@192 ~]# watch -d uptime #watch -d表示高亮显示变化的区域 Every 2.0s: uptime 21:04:44 up 45 min, 4 users, load average: 1.28, 0.88, 0.58 #3、在另一个终端查看cpu的使用率变化情况 # -P ALL 表示监控所有 CPU,后面数字 5 表示间隔 5 秒后输出一组数据 [root@192 ~]# mpstat -P ALL 5 Linux 3.10.0-1160.el7.x86_64 (192.168.92.2.centos) 01/15/2021 _x86_64_ (1 CPU) 09:05:14 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 09:05:19 all 0.20 0.00 82.45 17.35 0.00 0.00 0.00 0.00 0.00 0.00 09:05:19 0 0.20 0.00 82.45 17.35 0.00 0.00 0.00 0.00 0.00 #4、查看iowait高的原因 [root@192 ~]# pidstat -u 5 1 Linux 3.10.0-1160.el7.x86_64 (192.168.92.2.centos) 01/15/2021 _x86_64_ (1 CPU) 09:06:14 PM UID PID %usr %system %guest %wait %CPU CPU Command 09:06:19 PM 0 127259 32.60 0.20 0.00 67.20 32.80 0 stress 09:06:19 PM 0 127261 4.60 28.20 0.00 67.20 32.80 0 stress 09:06:19 PM 0 127262 4.20 28.60 0.00 67.20 32.80 0 stress #总结:结果可以看出是平均负载高是因为stress进程的sys跟iowait太高导致,cpu跟内核打交道的sys也很高
(3)大量进程
#1、先模拟一个4个进程的场景(不停执行sync) [root@192 ~]# stress -c 1 --timeout 600 stress: info: [2428] dispatching hogs: 0 cpu, 1 io, 0 vm, 0 hdd #2、在另一个终端查看平均负载的变化情况 [root@192 ~]# watch -d uptime #watch -d表示高亮显示变化的区域 Every 2.0s: uptime 21:28:44 up 1:10, 4 users, load average: 4.28, 2.38, 1.28 #3、在另一个终端查看cpu的使用率变化情况 # -P ALL 表示监控所有 CPU,后面数字 5 表示间隔 5 秒后输出一组数据 [root@192 ~]# mpstat -P ALL 5 Linux 3.10.0-1160.el7.x86_64 (192.168.92.2.centos) 01/15/2021 _x86_64_ (1 CPU) Average: UID PID %usr %system %guest %wait %CPU CPU Command Average: 0 130290 24.55 0.00 0.00 75.25 24.55 - stress Average: 0 130291 24.95 0.00 0.00 75.25 24.95 - stress Average: 0 130292 24.95 0.00 0.00 75.25 24.95 - stress Average: 0 130293 24.75 0.00 0.00 74.65 24.75 - stress #4、查看iowait高的原因 [root@192 ~]# pidstat -u 5 1 Linux 3.10.0-1160.el7.x86_64 (192.168.92.2.centos) 01/15/2021 _x86_64_ (1 CPU) 09:06:14 PM UID PID %usr %system %guest %wait %CPU CPU Command 09:06:19 PM 0 127259 32.60 0.20 0.00 67.20 32.80 0 stress 09:06:19 PM 0 127261 4.60 28.20 0.00 67.20 32.80 0 stress 09:06:19 PM 0 127262 4.20 28.60 0.00 67.20 32.80 0 stress #总结:从结果可以看出,4个进程在争1个进程,每个进程都在等待CPU时间,也就是wait接近70%,导致CPU过载,引起平均负载过高,
标签:src 时间 png stress 查看 hog pat 百分比 后台进程
原文地址:https://www.cnblogs.com/nq31/p/14269580.html