标签:返回 manifest 源码分析 除了 二层 pac layer 运行 value
LSM Tree(Log-Structured Merge-Trees),即日志合并树的应用相当广泛。和其他索引结构(如B-Tree)相比,LSM Tree主要优点是它使用缓冲和仅追加存储实现了顺序写操作。在B树中小的更新会带来较多的随机写,为了提高性能,LSM Tree可以批量处理(基于缓冲)key-value对,然后将它们顺序写入(基于仅追加存储)。
LSM-Tree的核心思想就是将写入推迟(Defer)并转换为批量(Batch)写,首先将大量写入缓存在内存,当积攒到一定程度后,将他们批量写入文件中,这要一次I/O可以进行多条数据的写入,充分利用每一次I/O。
由于不可变的追加导致重复内容是允许的,LSM树必须进行类似于归并排序(merge sort)的方法合并树的内容,即LSM中的合并(Merge)一词的意义。
LevelDB作为存储系统,数据记录存储的介质包含内存以及磁盘文件。对应LSM Tree的架构图如下。
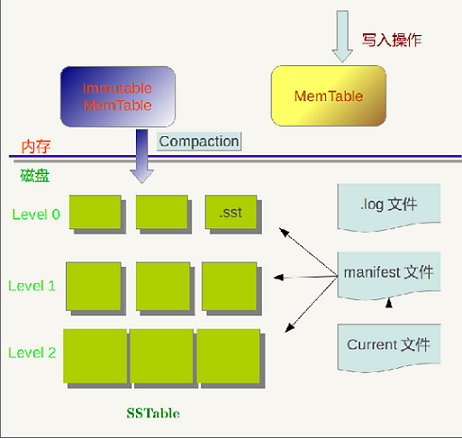
从图中可以看出,构成 LevelDB 静态结构的包括六个主要部分:内存中的 MemTable 和 Immutable MemTable 以及磁盘上的几种主要文件:Current文件,Manifest文件,log文件以及 SSTable 文件。当然,LevelDB 除了这六个主要部分还有一些辅助的文件,但是以上六个文件和数据结构是 LevelDB 的主体构成元素。
MemTable缓冲数据记录,充当读写操作的目标。当大小达到一个可配阈值时,memtable中的内容会被持久化到磁盘。memtable的更新不需要访问磁盘,没有相应的IO开销,。但我们需要一个单独的预写日志WAL保证数据记录的持久性。即当应用写入一条Key:Value记录的时候,LevelDb会先往log文件里写入,成功后将记录插进Memtable中,这样基本就算完成了写入操作,因为一次写入操作只涉及一次磁盘顺序写和一次内存写入,所以这是为何说LevelDb写入速度极快的主要原因。
MemTable在刷写之前必须进行memtable切换:
这两个操作必须被原子的执行。
在旧的memtable刷写完成后,该memtable可以丢弃,同时记录对旧memtable操作的日志可以删除。
MemTable维护的一个允许并发访问的有序数据结构。可以有多种实现,LevelDB使用的是SkipList。
LevelDB对于压实操作采用的是层级压实。
SSTable 就是由内存中的数据不断导出并进行 Compaction 操作后形成的,而且 SSTable 的所有文件是一种层级结构,第一层为Level 0,第二层为Level 1,依次类推,层级逐渐增高。SSTable 中的文件(后缀为.sst)是 key 有序的,就是说在文件中小 key 记录排在大 key 记录之前,除了 level 0,各个 level 的 SSTable 都是如此。
0层是通过直接刷写memtable创建,因此0层表可能存在重叠的键范围,如下图。0层上表数量只要达到某个阈值,他们的内容就会合并,常见一个层级为1的新表。

1层和所有更高层都没有键范围的重叠。0层到1层往往是消耗最大的。上述0层合并到1层。

1层及更高层的合并,是从将当前层的表与键范围重叠的下一层的表合并。
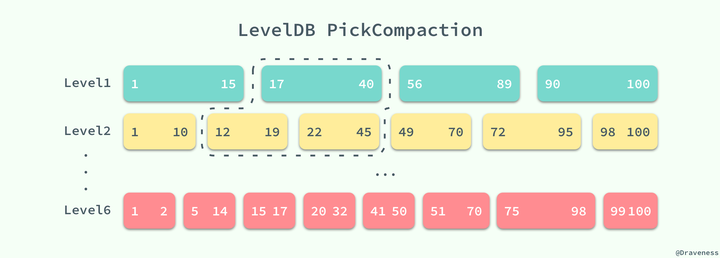
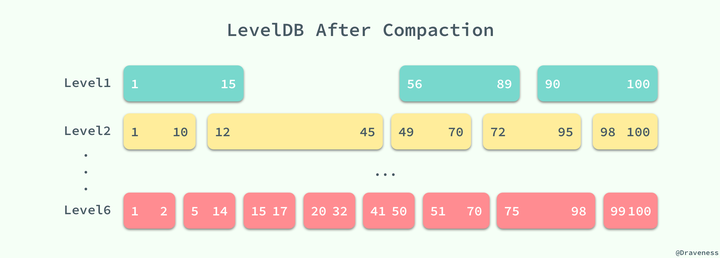
这样分 level 管理 sstable,对于非 level-0,sstable 不存在 overlap,所以查找时最多处理一个sstable。
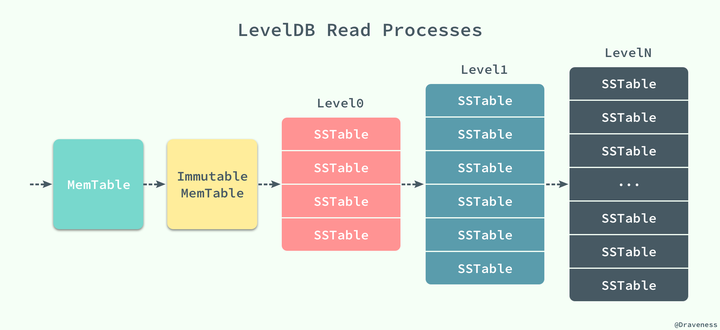
SSTable 中的某个文件属于特定层级,而且其存储的记录是 key 有序的,那么必然有文件中的最小 key 和最大 key,这是非常重要的信息,LevelDB 应该记下这些信息。manifest 就是干这个的,它记载了 SSTable 各个文件的管理信息,比如属于哪个 level,文件名称叫啥,最小 key 和最大 key 各自是多少。下图是 manifest 所存储内容的示意:

图中只显示了两个文件(manifest 会记载所有 SSTable 文件的这些信息),即 level 0 的 Test1.sst 和 Test2.sst 文件,同时记载了这些文件各自对应的 key 范围,比如 Test1.sst 的 key 范围是 “abc” 到 “hello”,而文件 Test2.sst 的 key 范围是 “bbc” 到 “world”,可以看出两者的 key 范围是有重叠的。
这个文件的内容只有一个信息,就是记载当前的 manifest 文件名。因为在 LevleDB 的运行过程中,随着 compaction 的进行,SSTable 文件会发生变化,会有新的文件产生,老的文件被废弃,manifest 也会跟着反映这种变化,此时往往会新生成 manifest 文件来记载这种变化,而 current 则用来指出哪个 manifest 文件才是我们关心的那个 manifest文件。
LevelDB 源码分析(二):主体结构 | 陈浩的个人博客
标签:返回 manifest 源码分析 除了 二层 pac layer 运行 value
原文地址:https://www.cnblogs.com/yyjjtt/p/14401563.html