标签:空间不足 行数据 访问 数组 算法 lazy 性能 缺点 易用
以删除操作为例,删除操作分为2种情况:
因为我们可以记录上次查找的位置p,每一次查询时,根据要查找的值与p的大小关系,决定是往前还是往后查找,所以平均只需要查找一半的数据。
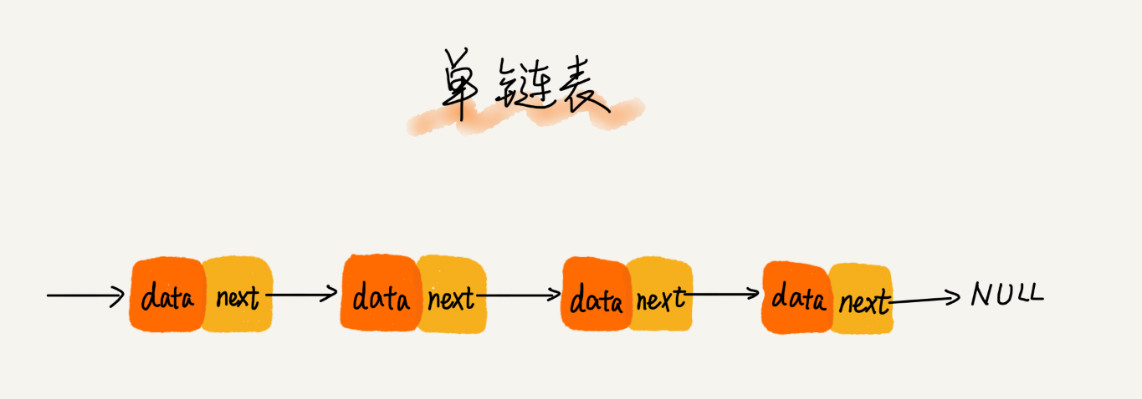
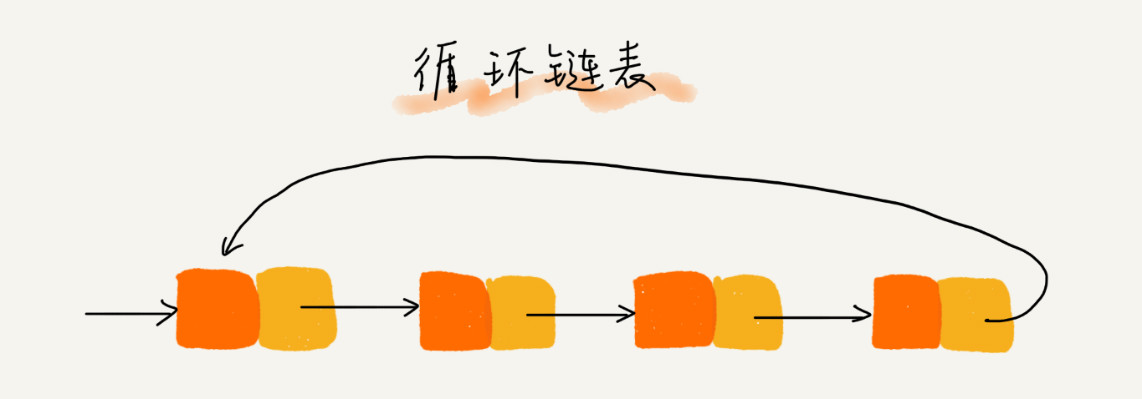
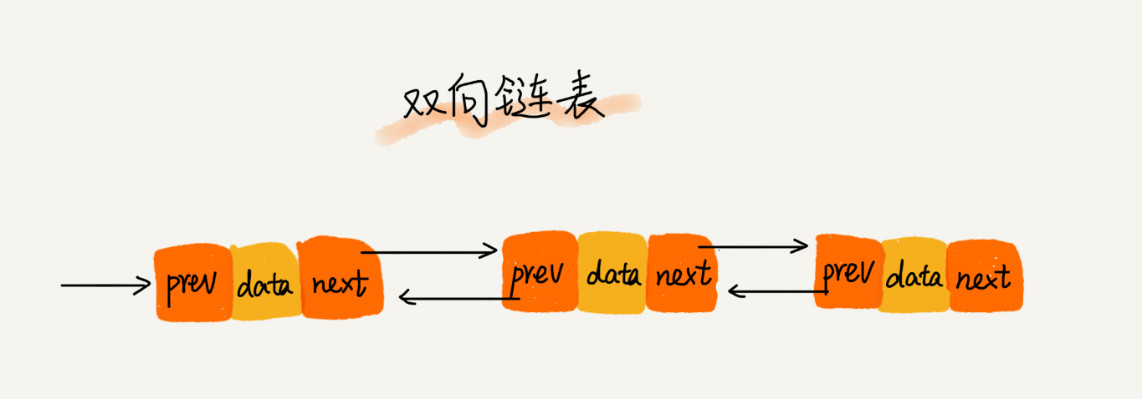
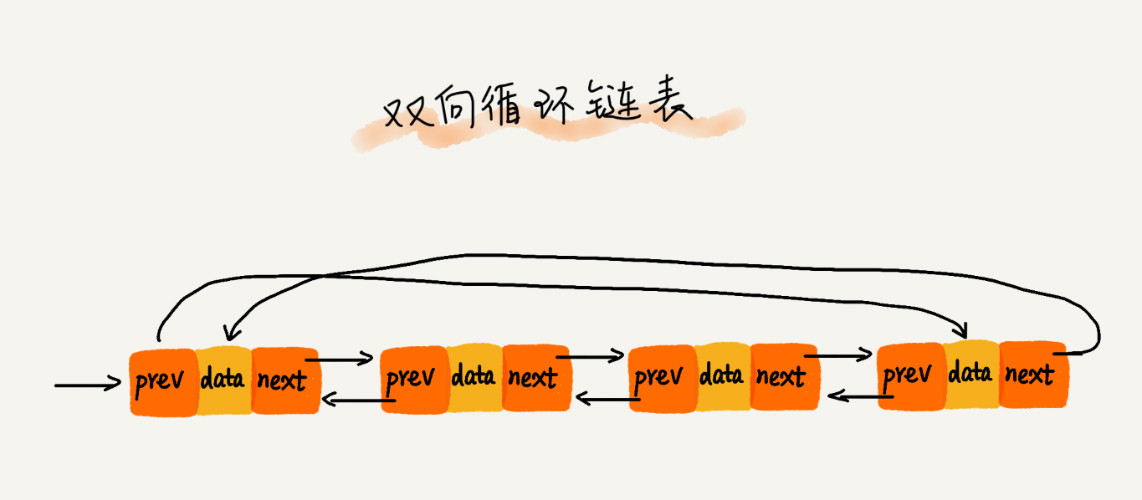
04 链表(上):如何实现LRU缓存淘汰算法?
原文地址:https://www.cnblogs.com/zyl1994/p/14800018.html