标签:调用 数据流 封装 数据库 之间 进一步 设置 line 发送
Scrapy框架架构图
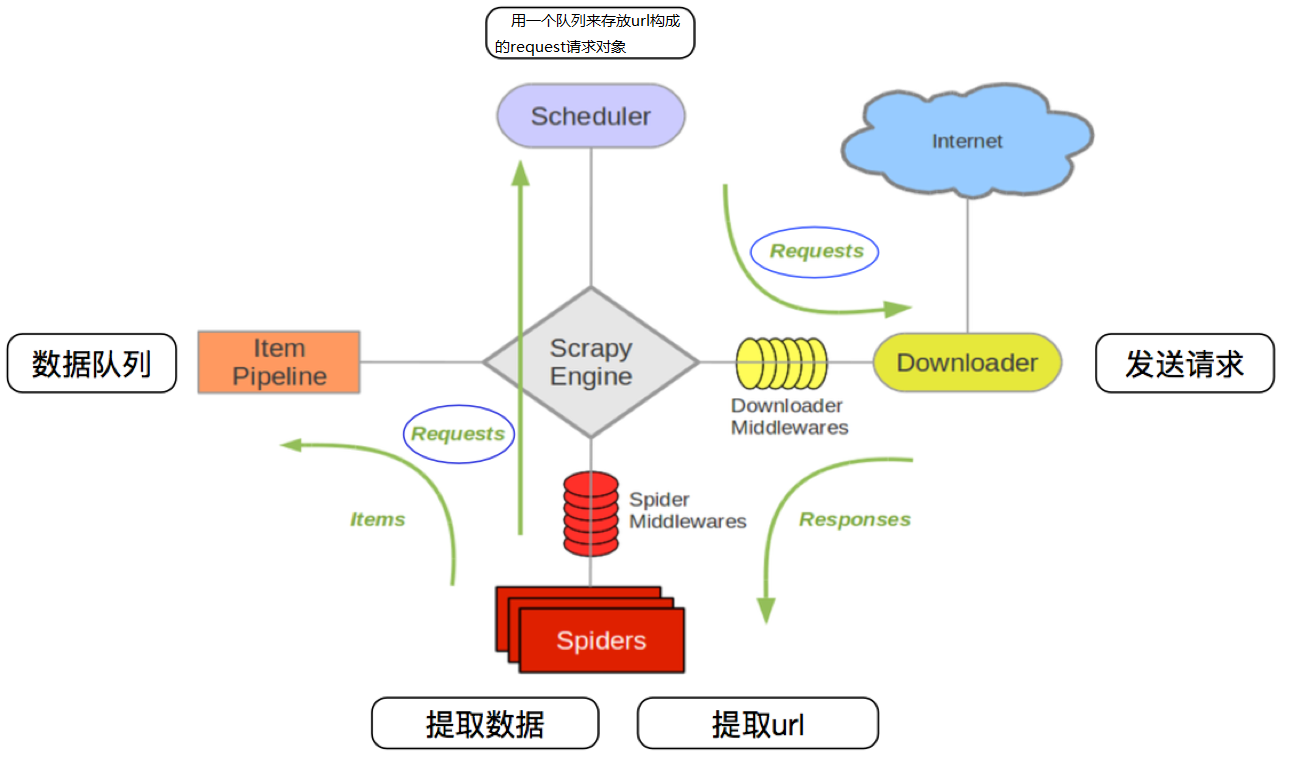
Scrapy框架主要由六大组件组成,分别为:
? 调度器(Scheduler),下载器(Downler),爬虫(Spiders),中间件(Middwares),管道(Item Pipeline)和Scrapy引擎(Scrapy Engine)
Scarpy框架模块功能
1. Schedule(调度器):调度器从引擎接受request并将他们入队,以便之后引擎请求他们时提供给引
2. Downloader(下载器):下载器负责获取页面数据并提供给引擎,而后提供给spider
3. Spiders(爬虫):Spider是Scrapy用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站
4. Item Pipeline(管道):Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存储到数据库中)
5. Scrapy Engine(引擎):引擎负责控制数据流在系统的所有组件中流动,并在相应动作发生时触发事
6. Downloader Middwares(下载中间件):下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能
7. Spiders Middwares(爬虫中间件):Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能
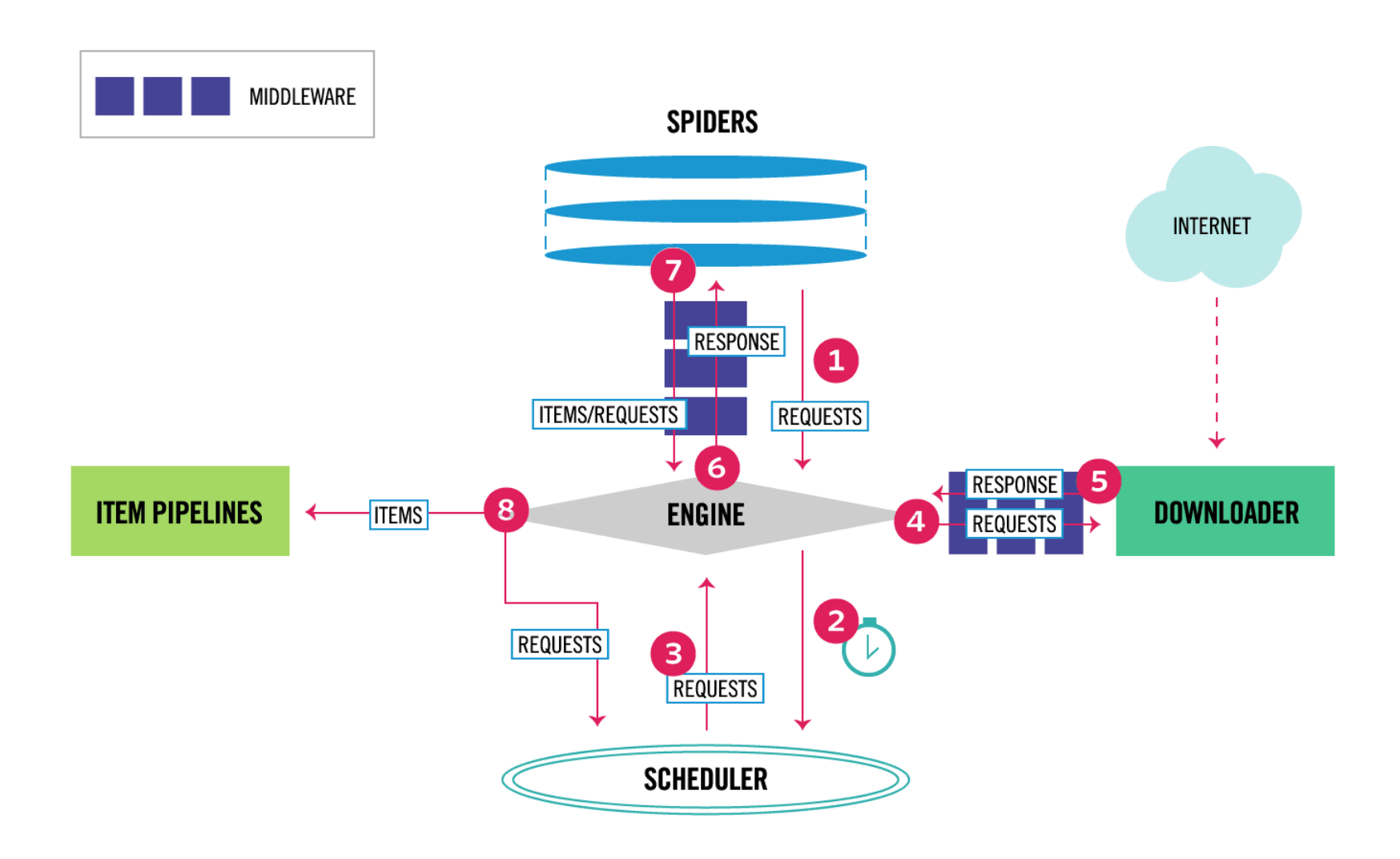
Scrapy工作流程
1. 当爬虫(Spider)要爬取某URL地址的页面时,使用该URL初始化Request对象提交给引擎(Scrapy Engine),并设置回调函数。 Spider中初始的Request是通过调用start_requests() 来获取的。start_requests() 读取start_urls 中的URL,并以parse为回调函数生成Request 。
2. Request对象进入调度器(Scheduler)按某种算法进行排队,之后的每个时刻调度器将其出列,送往下载器。
3. 下载器(Downloader)根据Request对象中的URL地址发送一次HTTP请求到网络服务器把资源下载下来,并封装成应答包(Response)。
4. 应答包Response对象最终会被递送给爬虫(Spider)的页面解析函数进行处理。
5. 若是解析出实体(Item),则交给实体管道(Item Pipeline)进行进一步的处理。由Spider返回的Item将被存到数据库(由某些Item Pipeline处理)或使用Feed exports存入到文件中。
6. 若是解析出的是链接(URL),则把URL交给调度器(Scheduler)等待抓取。以上就是Scrapy框架的运行流程,也就是它的工作原理。Request和Response对象是血液,Item是代谢产物。标签:调用 数据流 封装 数据库 之间 进一步 设置 line 发送
原文地址:https://www.cnblogs.com/moyiwang/p/14828790.html