标签:主机 数据库 恢复 通过 提升 应用 机制 节点 mamicode
在众多的Mysql高可用架构中,MHA架构目前属于现在比较成熟且岁数比较年长的架构之一了,目前,在Mysql的业界比较流行的高可用架构除了MHA,还有官方的MGR高可用架构、Percona公司出品的PXC(percona XtraDB Cluster)高可用架构以及Galera Cluster,MGR架构和PXC架构也会在本系列的高可用架构中一一讲解。
MHA架构主要是由日籍工程师youshimaton开发的,是一套在Mysql高可用性环境下进行故障切换或主从提升的优秀软件。在Mysql故障切换过程中,MHA能做到在0~30s之内自动完成数据库的故障切换操作,并且在故障切换的过程中,最大程度地保证数据的完整性和一致性,已达到真正意义上的高可用。
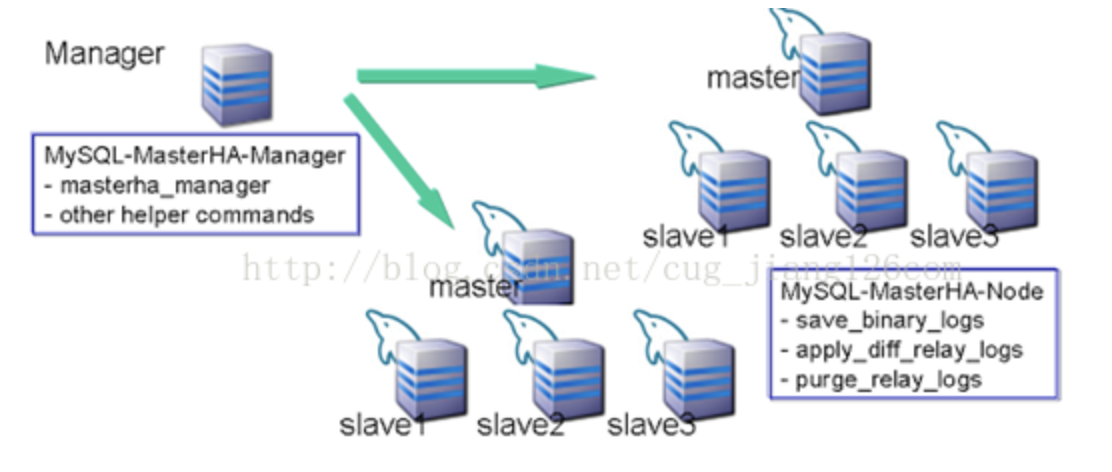
其实,MHA高可用架构主要是通过脚本进行实现设计的,其中MHA软件主要有两部分组成,即Manager工具包和Node工具包。
Manager工具包主要包含以下几个工具(脚本)
Node工具包(这些工具通常有MHA Manager的脚本触发,无须人为操作),主要包括如下一个工具(脚本)
总结:通过以上两种复制模式下的自动故障恢复对比可得出:传统复制模式和GTID复制模式,处理方式有些不同,也就是说如果启用了GTID,
需要打开从库的log-slave-updates以减少数据丢失的风险。
log-slave-updates:该参数用来配置从库上的更新操作是否写二进制,默认是off,即不写binlog(在Mysql8.0.23版本后,默认值是on),
如果这个从库同时也要作为其他服务器的主库,搭建一个链式的复制,或者在高可用的环境下(比如开启GTID模式下的MHA),那么就需要打开这个选项,
这样它的从库将获得它的二进制日志以进行同步操作。该参数需要和-log-bin结合使用,即如果没有开启--log-bin,即使将该参数设置ON,也不会写二进制。
1. 基于GTID和非GTID模式下的MHA自动故障转移,首先是基于GTID模式下的复制通常我们一般会用增强半同步复制(5.7版本或以后),
该复制方式保证了主库的binlog数据在传到slave节点时数据不丢失(数据一致性)的特点。因此不管基于任何时间点主节点宕机
(无论是Mysql服务宕机还是服务器宕机),主库的binlog日志一定会传到其中的一个备库中(或者)全部。
2.传统复制模式下MHA,当主节点宕机后,备节点还可以通过ssh连接主节点时,MHA试图从宕掉的主机的服务器上保存二进制,最大程度地保证数据不丢失。
也就是说将主库的binlog日志拷贝到各个节点上(有点的说是拷贝到管理节点上?)。
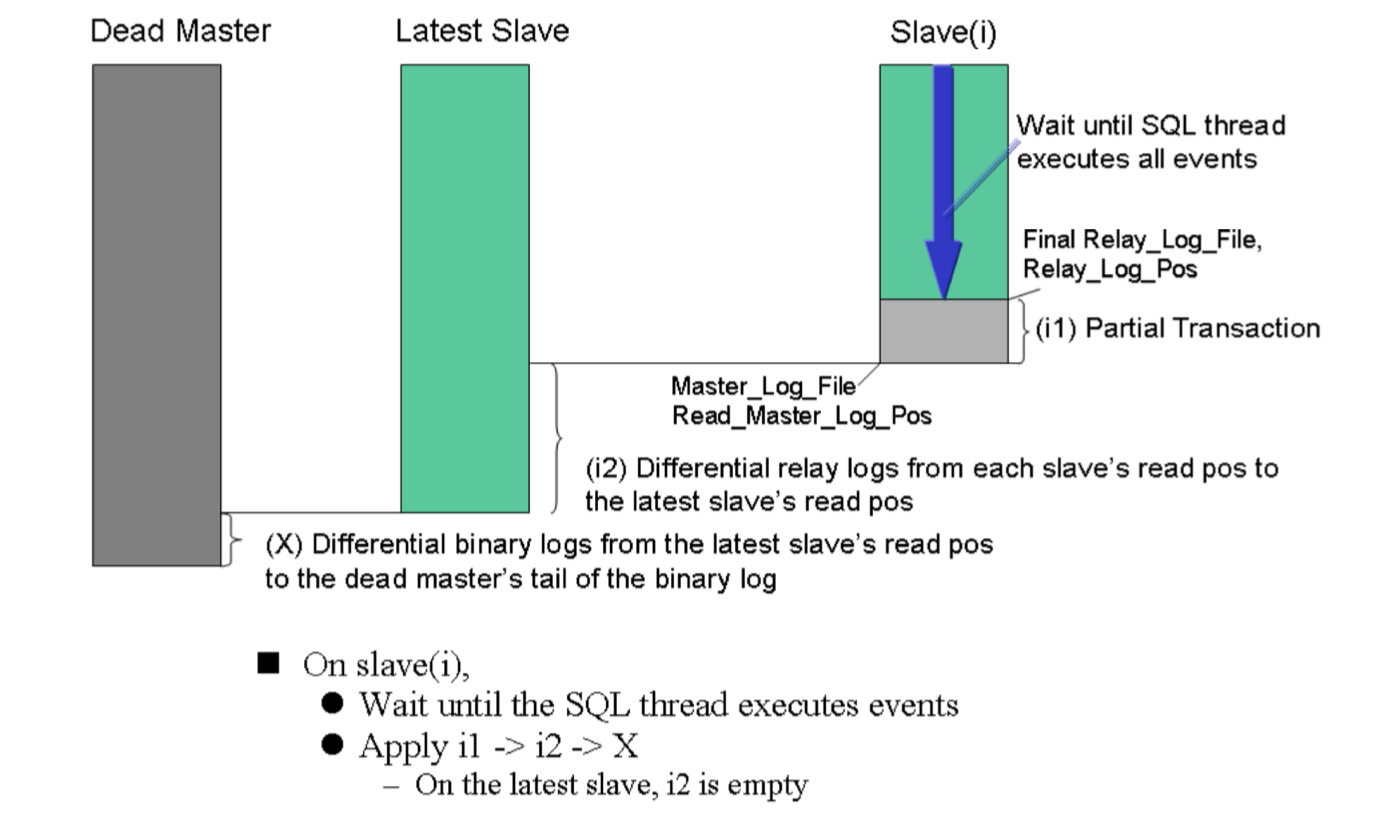
3.总结:纯属于个人的看法:第一步:当主节点宕机后,由于管理节点发出的探测接受不到主节点存活的状态信息后(这里有个检测机制),
立即通过ssh协议保存主节点的binlog日志到各个从节点,最大程度地保证数据不丢失(注意:这里如果是服务器宕机了,ssh就能使用了,则第一步就可以跳过了),
第二步:然后选最新更新的slave,也可以称做备选主机(这里有选择策略,见下文),第三步:应用差异的中继日志到其他的slave节点上,
第四步:应用从master保存下来的binlog日志(如果第一步跳过了,这一步也不会执行),第五步:把第二步这个最新更新的slave节点提升为新的master节点,
第六步:使其它的slave节点连接到这个新的master节点上进行复制。
4.选主策略:
算法一: 读取配置文件中是否有强制选主的参数? candidate_master=1 ###设置为候选master,如果设置该参数以后,发生主从切换以后会将此从库提升为主库,即使这个主库不是集群中事件最新的slave check_repl_delay=0 ### 默认情况下如果一个slave落后master 100M的relay logs 的话,MHA将不会选择该slave作为一个新的master,
因为对于这个slave的恢复需要花费很长时间, 通过设置check_repl_delay=0,MHA触发切换在选择一个新的master的时候将会忽略复制延时,这个参数对于设置了candidate_master=1的主机非常有用,
因为这个候选主在切换的过程中一定是新的master 算法二: 自动判读所有从库的日志量,将最接近的主库数据的从库作为新主 算法三: 按照配置文件先后顺序的进行选新主
官网参考地址:https://code.google.com/archive/p/mysql-master-ha/
标签:主机 数据库 恢复 通过 提升 应用 机制 节点 mamicode
原文地址:https://www.cnblogs.com/zmc60/p/14883879.html