标签:red ret 柱状图 数据清洗 error string some 出版 requests
选题的背景
为什么要选择此选题?要达到的数据分析的预期目标是什么?
小说是文化的一种载体,在古今中外的历史中都占据着重要的地位。人蒙对小说的需求也并不相同,如何在大量的小说里选取自己喜欢的小说,成为了问题,基于Python的数据爬虫技术是目前使用最广泛的方法之一,它能够以最快捷的方式展示用户体验数据,帮助读者进行小说选择。通过豆瓣小说爬取各种分类的小说。
数据来源:www.douban.com/tag/
Htmls 页面解析:
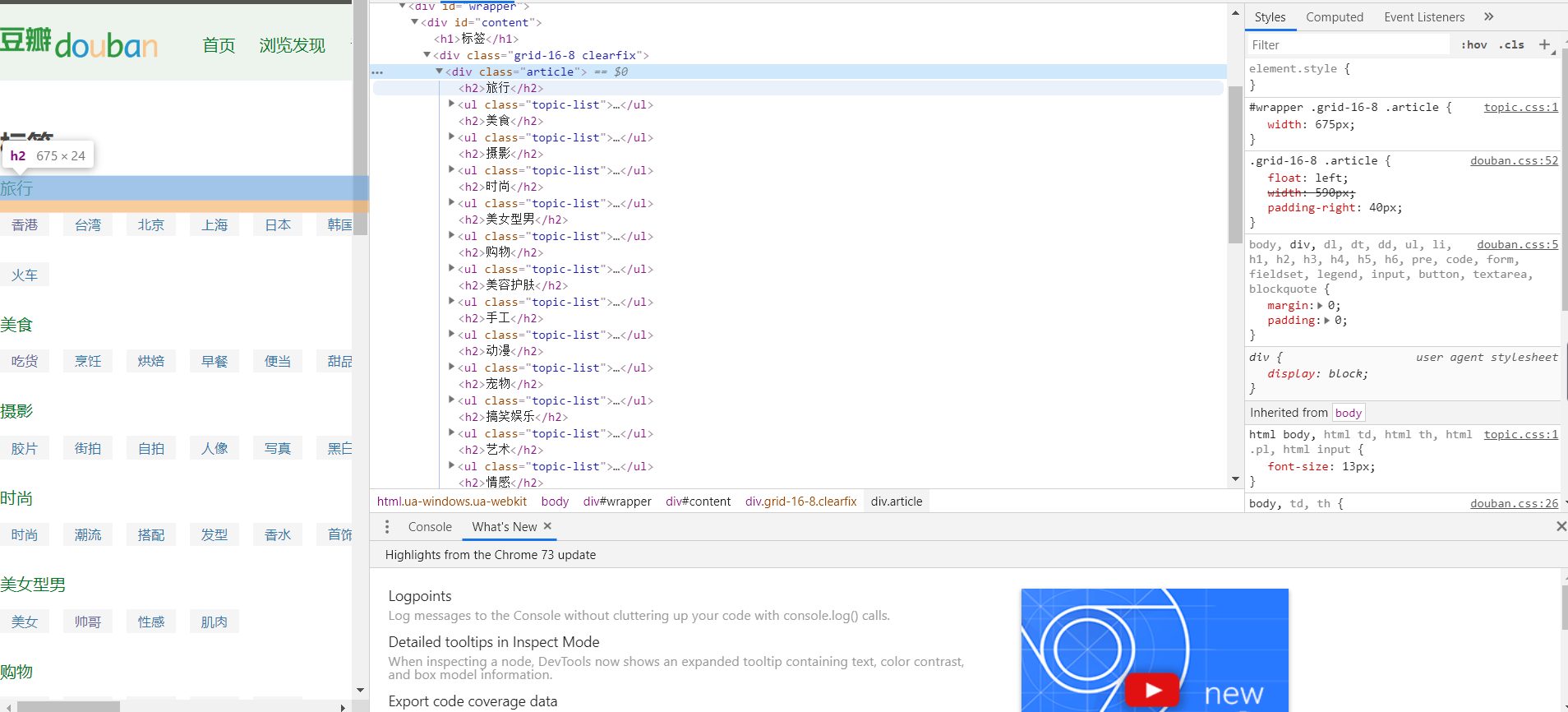
数据爬取与采集:
import importlib
import sys
import time
import urllib
from urllib.request import Request
import numpy as np
from bs4 import BeautifulSoup
from openpyxl import Workbook
importlib.reload(sys)
#sys.setdefaultencoding(‘utf8‘)
#Some User Agents
hds=[{‘User-Agent‘:‘Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6‘},\
{‘User-Agent‘:‘Mozilla/5.0 (Windows NT 6.2) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.12 Safari/535.11‘},\
{‘User-Agent‘: ‘Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Trident/6.0)‘}]
def book_spider(book_tag):
page_num=0;
book_list=[]
try_times=0
while(1):
#url=‘http://www.douban.com/tag/%E5%B0%8F%E8%AF%B4/book?start=0‘ # For Test
url=‘http://www.douban.com/tag/‘+urllib.parse.quote(book_tag)+‘/book?start=‘+str(page_num*15)
time.sleep(np.random.rand()*5)
#Last Version
try:
req = Request(url, headers=hds[page_num%len(hds)])
source_code = urllib.request.urlopen(req).read()
plain_text=str(source_code,‘utf-8‘)
except (urllib.request.HTTPError, urllib.request.URLError) as e:
print (e)
continue
##Previous Version, IP is easy to be Forbidden
#source_code = requests.get(url)
#plain_text = source_code.text
soup = BeautifulSoup(plain_text)
list_soup = soup.find(‘div‘, {‘class‘: ‘mod book-list‘})
try_times+=1;
if list_soup==None and try_times<200:
continue
elif list_soup==None or len(list_soup)<=1:
break # Break when no informatoin got after 200 times requesting
for book_info in list_soup.findAll(‘dd‘):
title = book_info.find(‘a‘, {‘class‘:‘title‘}).string.strip()
desc = book_info.find(‘div‘, {‘class‘:‘desc‘}).string.strip()
desc_list = desc.split(‘/‘)
book_url = book_info.find(‘a‘, {‘class‘:‘title‘}).get(‘href‘)
try:
author_info = ‘作者/译者: ‘ + ‘/‘.join(desc_list[0:-3])
except:
author_info =‘作者/译者: 暂无‘
try:
pub_info = ‘出版信息: ‘ + ‘/‘.join(desc_list[-3:])
except:
pub_info = ‘出版信息: 暂无‘
try:
rating = book_info.find(‘span‘, {‘class‘:‘rating_nums‘}).string.strip()
except:
rating=‘0.0‘
try:
#people_num = book_info.findAll(‘span‘)[2].string.strip()
people_num = get_people_num(book_url)
people_num = people_num.strip(‘人评价‘)
except:
people_num =‘0‘
book_list.append([title,rating,people_num,author_info,pub_info])
try_times=0 #set 0 when got valid information
page_num+=1
print (‘Downloading Information From Page %d‘ % page_num)
return book_list
def get_people_num(url):
#url=‘http://book.douban.com/subject/6082808/?from=tag_all‘ # For Test
try:
req = urllib.Request(url, headers=hds[np.random.randint(0,len(hds))])
source_code = urllib.request.urlopen(req).read()
plain_text=str(source_code)
except (urllib.request.HTTPError, urllib.request.HTTPError) as e:
print (e)
soup = BeautifulSoup(plain_text)
people_num=soup.find(‘div‘,{‘class‘:‘rating_sum‘}).findAll(‘span‘)[1].string.strip()
return people_num
def do_spider(book_tag_lists):
book_lists=[]
for book_tag in book_tag_lists:
book_list=book_spider(book_tag)
book_list=sorted(book_list,key=lambda x:x[1],reverse=True)
book_lists.append(book_list)
return book_lists
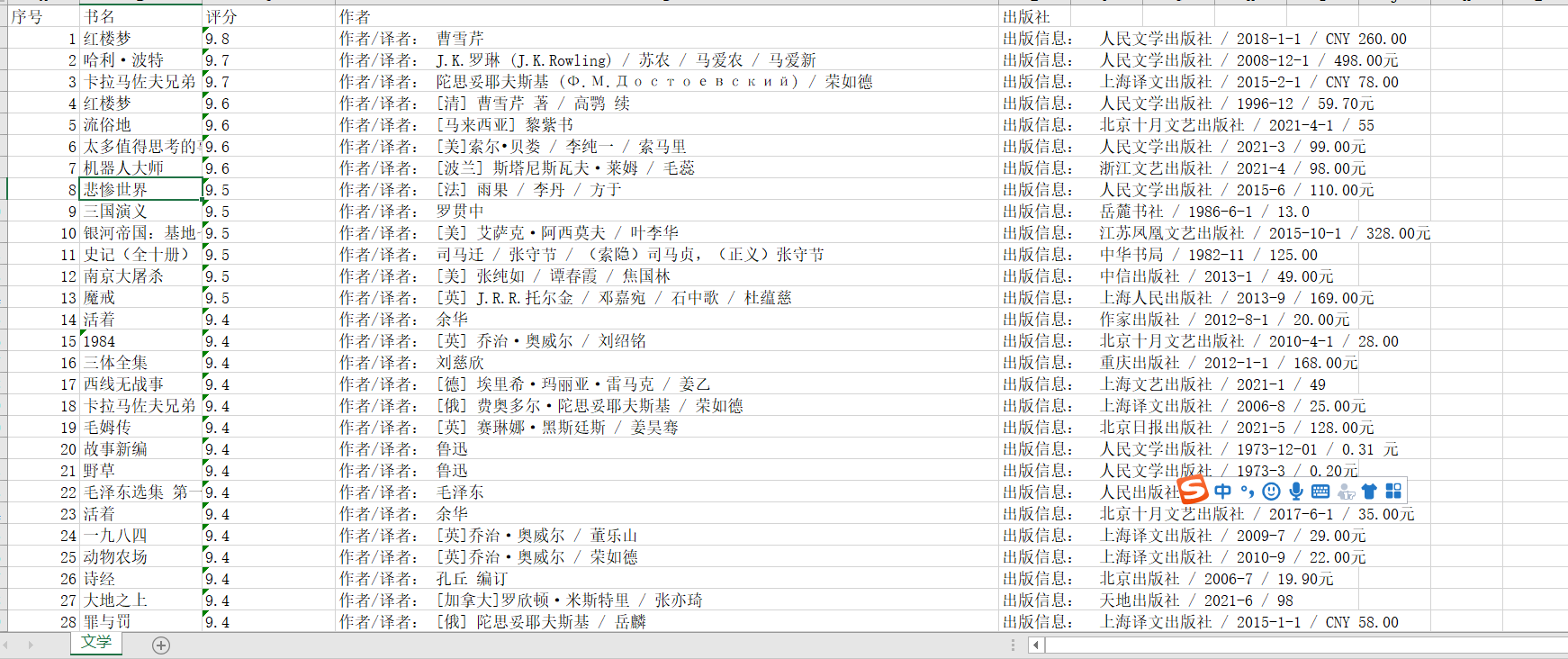
数据清洗:
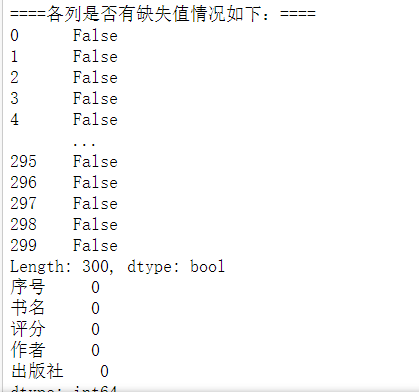
import pandas as pd df = pd.DataFrame(pd.read_excel(r‘C:\Users\86591\book_list-文学.xlsx‘)) print(‘\n====各列是否有缺失值情况如下:====‘) #重复值处理 print(df.duplicated()) #统计空值 print(df.isnull().sum()) #返回0则没有空值 #缺失值处理 print(df[df.isnull().values==True]) #返回无缺失值 #用describe()命令显示描述性统计指标 print(df.describe())
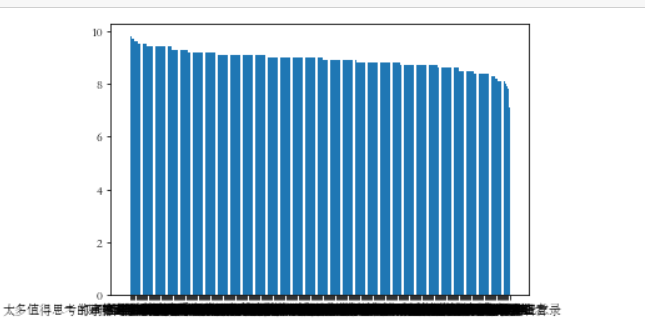
柱状图:
plt.rcParams[‘axes.unicode_minus‘]=False #用来正常显示负号 plt.bar(df.书名, df.评分, label="书名与评分柱状图") plt.show()
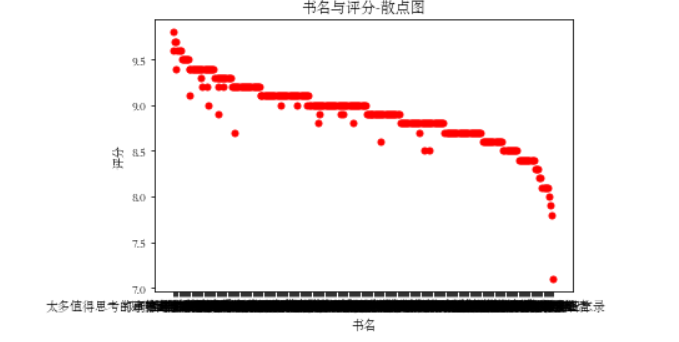
散点图:
def Scatter_point(): plt.scatter(df.书名, df.评分, color=‘red‘, s=25, marker="o") plt.xlabel("书名") plt.ylabel("评分") plt.title("书名与评分-散点图") plt.show() Scatter_point() #散点图
完整代码:
import importlib import sys import time import urllib from urllib.request import Request import numpy as np from bs4 import BeautifulSoup from openpyxl import Workbook importlib.reload(sys) #sys.setdefaultencoding(‘utf8‘) #Some User Agents hds=[{‘User-Agent‘:‘Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6‘},{‘User-Agent‘:‘Mozilla/5.0 (Windows NT 6.2) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.12 Safari/535.11‘},{‘User-Agent‘: ‘Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Trident/6.0)‘}] def book_spider(book_tag): page_num=0; book_list=[] try_times=0 while(1): #url=‘http://www.douban.com/tag/%E5%B0%8F%E8%AF%B4/book?start=0‘ # For Test url=‘http://www.douban.com/tag/‘+urllib.parse.quote(book_tag)+‘/book?start=‘+str(page_num*15) time.sleep(np.random.rand()*5) #Last Version try: req = Request(url, headers=hds[page_num%len(hds)]) source_code = urllib.request.urlopen(req).read() plain_text=str(source_code,‘utf-8‘) except (urllib.request.HTTPError, urllib.request.URLError) as e: print (e) continue ##Previous Version, IP is easy to be Forbidden #source_code = requests.get(url) #plain_text = source_code.text soup = BeautifulSoup(plain_text) list_soup = soup.find(‘div‘, {‘class‘: ‘mod book-list‘}) try_times+=1; if list_soup==None and try_times<200: continue elif list_soup==None or len(list_soup)<=1: break # Break when no informatoin got after 200 times requesting for book_info in list_soup.findAll(‘dd‘): title = book_info.find(‘a‘, {‘class‘:‘title‘}).string.strip() desc = book_info.find(‘div‘, {‘class‘:‘desc‘}).string.strip() desc_list = desc.split(‘/‘) book_url = book_info.find(‘a‘, {‘class‘:‘title‘}).get(‘href‘) try: author_info = ‘作者/译者: ‘ + ‘/‘.join(desc_list[0:-3]) except: author_info =‘作者/译者: 暂无‘ try: pub_info = ‘出版信息: ‘ + ‘/‘.join(desc_list[-3:]) except: pub_info = ‘出版信息: 暂无‘ try: rating = book_info.find(‘span‘, {‘class‘:‘rating_nums‘}).string.strip() except: rating=‘0.0‘ try: #people_num = book_info.findAll(‘span‘)[2].string.strip() people_num = get_people_num(book_url) people_num = people_num.strip(‘人评价‘) except: people_num =‘0‘ book_list.append([title,rating,people_num,author_info,pub_info]) try_times=0 #set 0 when got valid information page_num+=1 print (‘Downloading Information From Page %d‘ % page_num) return book_list def get_people_num(url): #url=‘http://book.douban.com/subject/6082808/?from=tag_all‘ # For Test try: req = urllib.Request(url, headers=hds[np.random.randint(0,len(hds))]) source_code = urllib.request.urlopen(req).read() plain_text=str(source_code) except (urllib.request.HTTPError, urllib.request.HTTPError) as e: print (e) soup = BeautifulSoup(plain_text) people_num=soup.find(‘div‘,{‘class‘:‘rating_sum‘}).findAll(‘span‘)[1].string.strip() return people_num def do_spider(book_tag_lists): book_lists=[] for book_tag in book_tag_lists: book_list=book_spider(book_tag) book_list=sorted(book_list,key=lambda x:x[1],reverse=True) book_lists.append(book_list) return book_lists def print_book_lists_excel(book_lists,book_tag_lists): wb=Workbook(write_only =True) ws=[] for i in range(len(book_tag_lists)): ws.append(wb.create_sheet(title=book_tag_lists[i].encode().decode(‘utf-8‘))) #utf8->unicode for i in range(len(book_tag_lists)): ws[i].append([‘序号‘,‘书名‘,‘评分‘,‘作者‘,‘出版社‘]) count=1 for bl in book_lists[i]: ws[i].append([count, bl[0],(bl[1]),bl[3],bl[4]]) count+=1 save_path=‘book_list‘ for i in range(len(book_tag_lists)): save_path+=(‘-‘+book_tag_lists[i].encode().decode(‘utf-8‘)) save_path+=‘.xlsx‘ wb.save(save_path) if __name__==‘__main__‘: book_tag_lists = [‘文学‘] book_lists=do_spider(book_tag_lists) print_book_lists_excel(book_lists,book_tag_lists)
小说使我们当前最普遍的娱乐方式之一,通过此课程设计完成通过小说标签对小说进行爬取,可以使人更容易找到自己感兴趣的小说。通过对·python的学习,可以让生活中的一些事情做起来变得更加轻松,这就是我们学习高级语言的原因,通过对python的学习,更加丰富了自己的知识。
标签:red ret 柱状图 数据清洗 error string some 出版 requests
原文地址:https://www.cnblogs.com/liuzhijie1/p/14905224.html