标签:次方 使用 long 机器 更改 机制 出现 unicode 优化
问题抛出:静态常量(static final)可以再编译器确定字面量,但常量(final或者String a = “a”或者Integer的 -128-127)并不一定在编译期就确定了, 也可以在运行时确定.所以Java针对某些情况制定了常量优化机制。
拓展:
为啥Integer是-128-12

如果对assert感兴趣可以查看:https://www.cnblogs.com/jpfss/p/10973837.html
常量优化机制:给一个变量赋值,如果等于号的右边是常量的表达式并且没有一个变量,那么就会在编译阶段计算该表达式的结果,然后判断该表达式的结果是否在左边类型所表示范围内,如果在,那么就赋值成功,如果不在,那么就赋值失败。但是注意如果一旦有变量参与表达式,那么就不会有编译期间的常量优化机制
结合问题,我们就可以大致猜出,如果常量能在编译期确定就会有优化,不能的话就不存在。
下面我们来详细讲解一下这个机制,Java中的常量池常量优化机制主要是两方面
byte:8位,最大存储数据量是255,存放的数据范围是-128~127之间。
short:16位,最大数据存储量是65536,数据范围是-32768~32767之间。
int:32位,最大数据存储容量是2的32次方减1,数据范围是负的2的31次方到正的2的31次方减1。
long:64位,最大数据存储容量是2的64次方减1,数据范围为负的2的63次方到正的2的63次方减1。
float:32位,数据范围在3.4e-45~1.4e38,直接赋值时必须在数字后加上f或F。
double:64位,数据范围在4.9e-324~1.8e308,赋值时可以加d或D也可以不加。
boolean:只有true和false两个取值。
char:16位,存储Unicode码,用单引号赋值。
Java决定了每种简单类型的大小。这些大小并不随着机器结构的变化而变化。这种大小的不可更改正是Java程序具有很强移植能力的原因之一。下表列出了Java中定义的简单类型、占用二进制位数及对应的封装器类。

1.以下面这个程序为例
byte b1 = 1 + 2; System.out.println(b1); // 输出结果 3
运行结果解释:1和2都是常量,Java有常量优化机制,就是可以编译时可以明显确定常量结果,所以直接把1和2的结果赋值给b1了。(和直接赋值3是一个意思)
2.换一种情况看看,把右边常量改成变量
byte b1 = 3; byte b2 = 4; byte b3 = b1 + b2; System.out.println(b3); // 程序报错
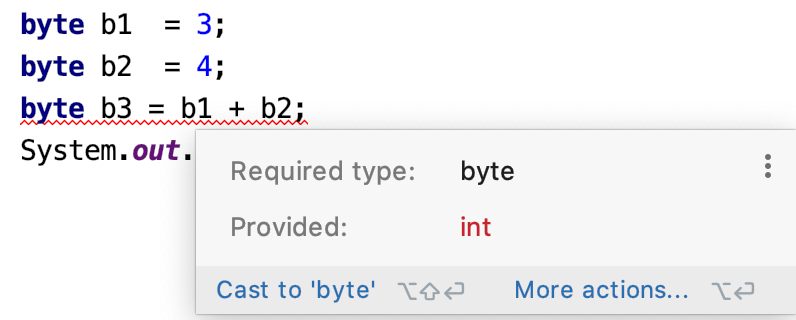
程序报错了,意思说类型不匹配:无法从int转换为byte
解释原因,从两个方面:
这就是为什么一旦有变量参与表达式,那么就不会有编译期间的常量优化机制
3.在这里我们试着把变量添加final改回常量,看看又有什么结果
final byte b1 = 1; final byte b2 = 2; byte b3 = b1 + b2; System.out.println(b3);//3
输出的结果是3,因为b1和b2都是final修饰的,所以是常量,所以b3的时候就是常量相加不会出现编译的问题。
4、接下来我们再看另外一个程序
byte b1 = 127 + 2; System.out.println(b4);
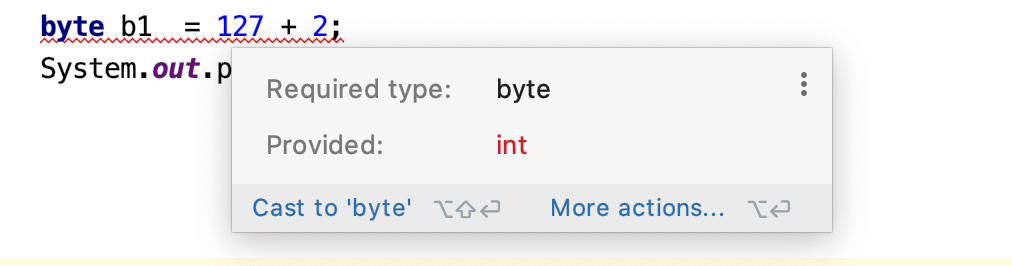
会出现编译报错,因为是常量在做相加,而且byte的取值范围是-128~127,很明显右边表达式的结果是不在左边类型所表示范围,这个就是导致此错误出现的原因。
5.某些场景下,取值范围大的数据类型(int)可以直接赋值给取值范围小的(byte、short、char),而且只能特定int赋值给byte/short/char,其他基本数据类型不行,如下图。
int num1 = 10; final int num2 = 10; byte var1 = num1 + 20; // 存在变量,编译报错 byte var2 = num2 + 20; // 编译通过
所以我们这里总结一下byte/short/char三种类型的常量优化机制
//额外例子说明
char d = 65;
char a = 11;
System.out.println(d);//打印是A
System.out.println(a);//打印是空的
为啥a打印的是空,d打印是A,因为a打印的时候在ASCII等字符编码表中有对应的数值
char类型是可以运算的因为char在ASCII等字符编码表中有对应的数值
拓展一下(易错点):
byte var = 10; var = var + 20; // 编译报错,运算中存在变量 var += 20; // 等效于: var = (short) (var + 20); 没有走常量优化机制,而是进行了类型转换
标签:次方 使用 long 机器 更改 机制 出现 unicode 优化
原文地址:https://www.cnblogs.com/lhicp/p/14909492.html