标签:关注 输出 大量 nal 也会 基于 intel end 另一个
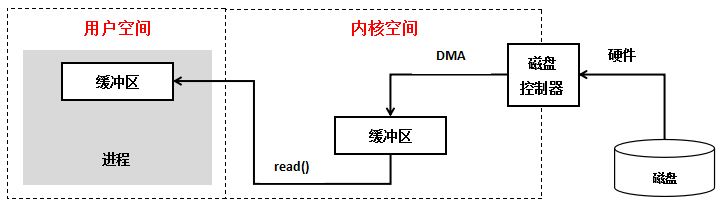
每一个文件描述符会与一个打开文件相对应,同时,不同的文件描述符也会指向同一个文件。相同的文件可以被不同的进程打开也可以在同一个进程中被多次打开。系统为每一个进程维护了一个文件描述符表,该表的值都是从0开始的,所以在不同的进程中你会看到相同的文件描述符,这种情况下相同文件描述符有可能指向同一个文件,也有可能指向不同的文件。
具体概况,需要查看由内核维护的3个数据结构:
1.进程级的文件描述符表;
2.系统级的打开文件描述符表;
3.文件系统的i-node表。
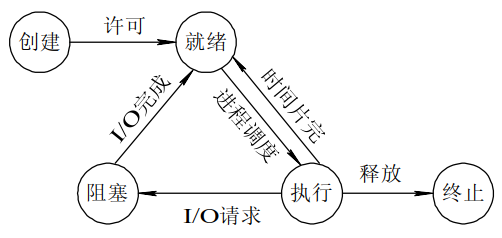
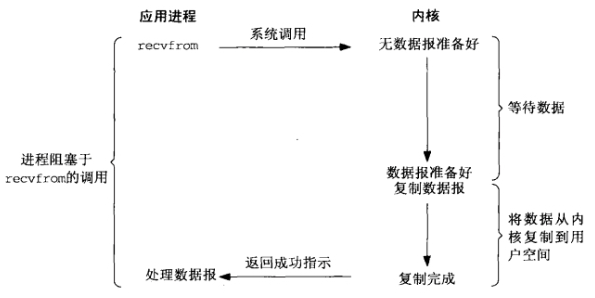
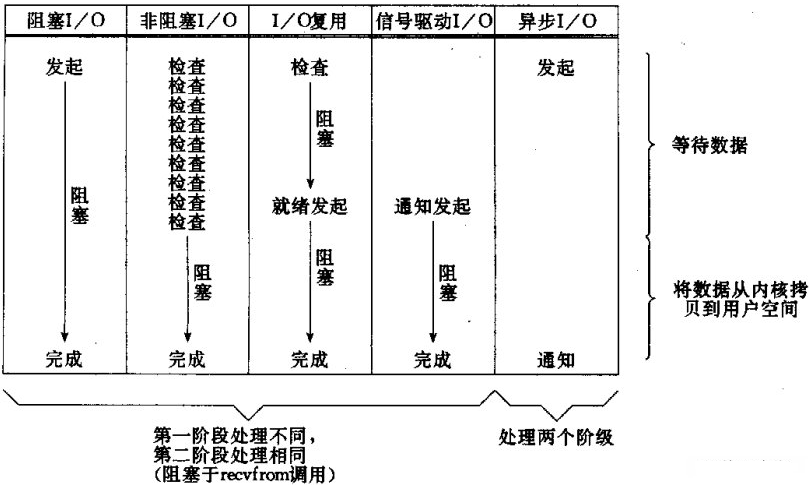
进程阻塞挂起不消耗CPU资源、及时响应每个操作。
实现难度低、开发应用较容易。
适用并发量小的网络应用开发。
不适用并发量大的应用、因为一个请求10会阻塞进程、所以、得为每请求分配一个处理进程(线程)以及时响应、系统开销大。
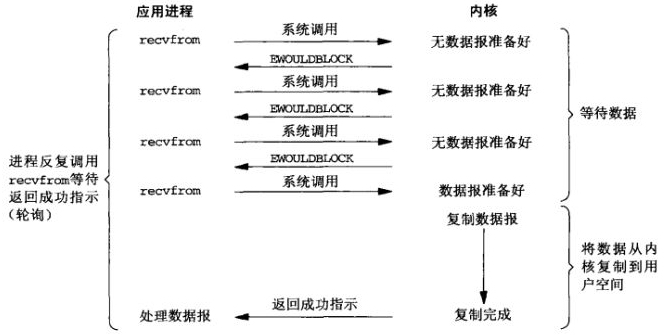
进程轮询(重复)调用、消耗CPU的资源。
实现难度低、开发应用相对阻塞IO模式较难。
适用并发量较小、且不需要及时响应的网络应用开发。
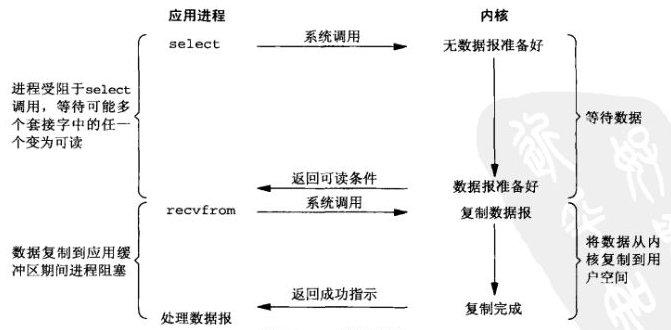
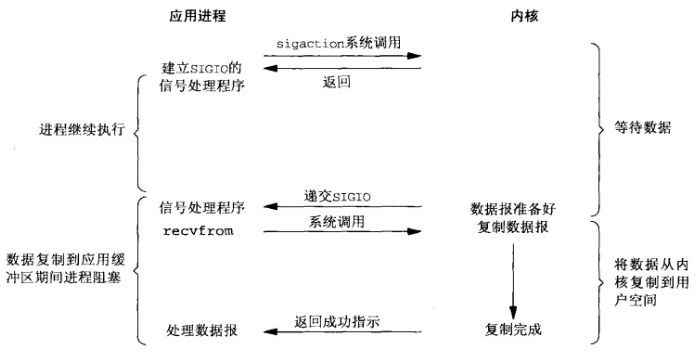
专一解决多个进程IO的阻塞问题、性能好、Reactor模式。
实现、开发应用难度较大。
适用高并发服务应用开发、一个进程/线程响应多个请求。
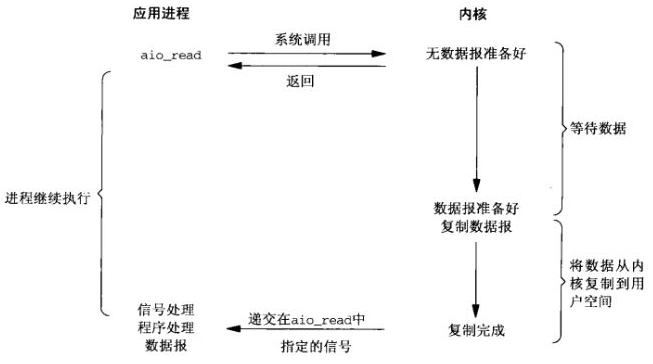
不阻塞、数据一步到位、Proactor模式
需要操作系统的底层支持、LINUX 2.5版本内核首现、2.6版本产品的内核标准特性
回调机制、实现、开发应用难度大
非常适合高性能高并发应用
# #
标签:关注 输出 大量 nal 也会 基于 intel end 另一个
原文地址:https://www.cnblogs.com/maiblogs/p/14890084.html