标签:状态保持 tar 工作 平滑 path 元数据 block size actual
摘要:CarbonData 在 Apache Spark 和存储系统之间起到中介服务的作用,为 Spark 提供的4个重要功能。
本文分享自华为云社区《Make Apache Spark better with CarbonData》,原文作者:大数据修行者 。
Spark 无疑是一个强大的处理引擎和一个用于更快处理的分布式集群计算框架。不幸的是,Spark在一些方面也存在不足。如果我们将 Apache Spark 与 Apache CarbonData 结合使用,它可以克服这些不足:
1. 不支持 ACID transaction
2. 没有quality enforcement
3. 小文件问题
4. 低效的data skipping
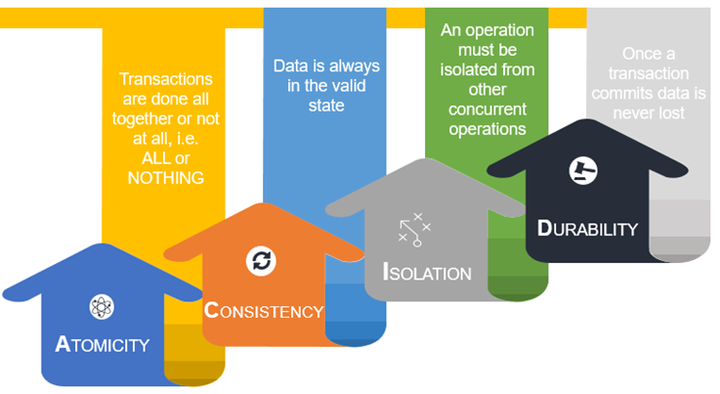
ACID 中的 A 代表原子性。基本上,这意味着要么全部成功要么全部失败。因此,当您使用 spark data frame writer API时,它应该写入完整数据或不写入任何数据。让我们快速查看 Spark 文档。根据 Spark 文档:“It is important to realize that these save mode (overwrite) do not utilize any locking and are not atomic. Additionally, when performing an Overwrite, the data will be deleted before writing out the new data.”
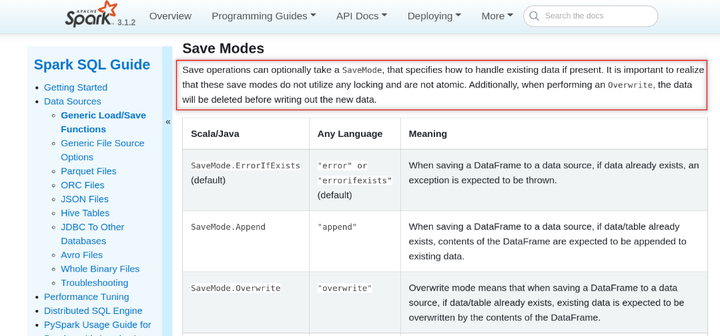
虽然整个情况看起来有点可怕,但实际上并没有那么糟糕。 Spark dataframe API在内部执行作业级提交,这有助于实现一定程度的原子性,这与使用 Hadoop 的 FileOutputCommitter 的“append”模式一起工作。但是,默认实现会带来性能开销,尤其是在使用云存储 [S3/OBS] 而不是 HDFS 时。
我们现在可以运行以下代码来证明 Spark overwrite 不是原子的,它可能导致数据损坏或数据丢失。代码的第一部分模仿作业 1,它创建 100 条记录并将其保存到 ACIDpath 目录中。代码的第二部分模仿作业 2,它试图覆盖现有数据,但在操作过程中引发异常。这两项工作的结果是数据丢失。最后,我们丢失了第一个作业创建的数据。
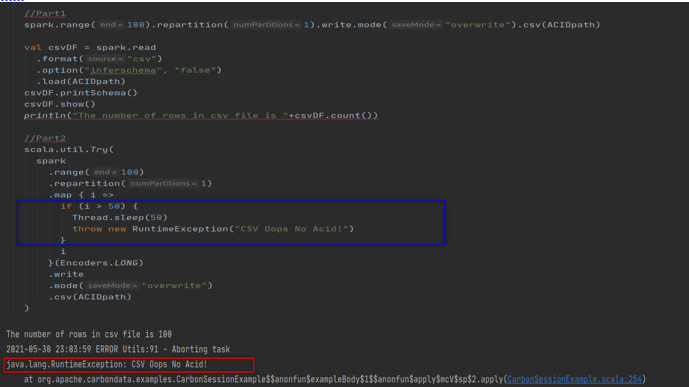
由于异常,作业级提交不会发生,因此不会保存新文件。由于 Spark 删除了旧文件,我们丢失了现有数据。 Spark data frame writer API 不是原子的,但它的行为类似于追加操作的原子操作。
分布式系统通常建立在可用性较低的机器之上。一致性是高可用性系统中的一个关键问题。如果所有节点同时看到并返回相同的数据,则系统是一致的。有几种一致性模型,分布式系统中最常用的一种是强一致性、弱一致性和最终一致性。我们了解到,Spark writer API 的覆盖模式会先删除旧文件,然后再放置新文件。因此,在这两种状态之间,会有一段时间没有数据可用。如果我们的工作失败,那么我们将丢失数据。这意味着这两个操作之间没有平滑的事务。这是 Spark 覆盖操作的典型原子性问题。而这个问题也破坏了数据的一致性。 Spark API 缺乏一致性。因此,Spark 写模式不支持一致性。
隔离意味着分离。与任何其他并发操作分离。假设我们正在写入尚未提交的数据集,并且有另一个并发进程正在读取/写入同一数据集。根据隔离特性,在这种情况下,不应影响他人。典型的数据库会提供不同的隔离级别,例如已提交读和可序列化。虽然 Spark 有任务级提交和作业级提交,但由于写操作缺乏原子性,Spark 无法提供适当的隔离。
最后,Durability 是系统保存的已提交状态/数据,这样即使在出现故障和系统重启的情况下,数据也能以正确的状态使用。持久性由存储层提供,在 Spark 应用程序的情况下,它是 HDFS 和 S3/OBS 的作用。然而,当 Spark 由于缺乏原子性而没有提供适当的提交时,如果没有适当的提交,我们就不能指望持久性。
如果我们仔细观察,所有这些 ACID 属性都是相互关联的。由于缺乏原子性,我们失去了一致性和隔离性,由于缺乏隔离性,我们失去了持久性。
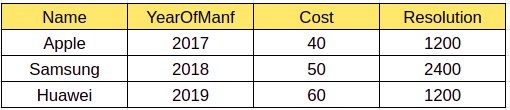
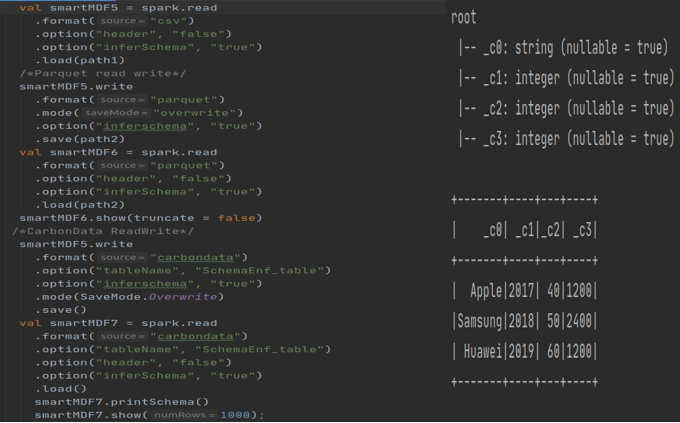
我们知道 Spark 在读取时意味着 Schema。因此,当我们写入任何数据时,如果有任何模式不匹配,它不会抛出异常。让我们试着用一个例子来理解这一点。让我们有一个包含以下记录的输入数组。下面的程序将读取 csv 并转换为 DF
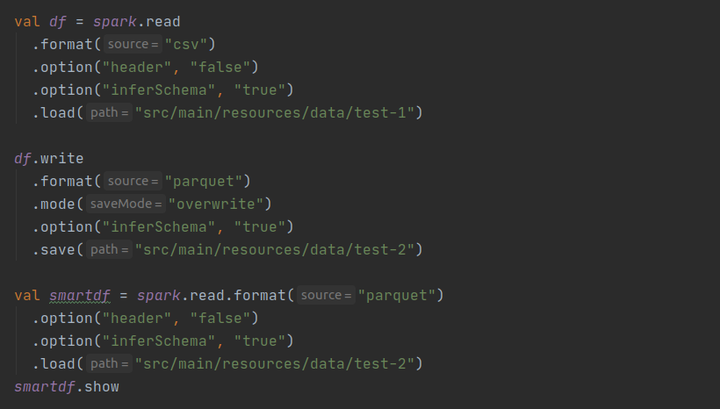
该程序从 CSV 文件中读取,以镶木地板格式写回并显示数据。输出如下
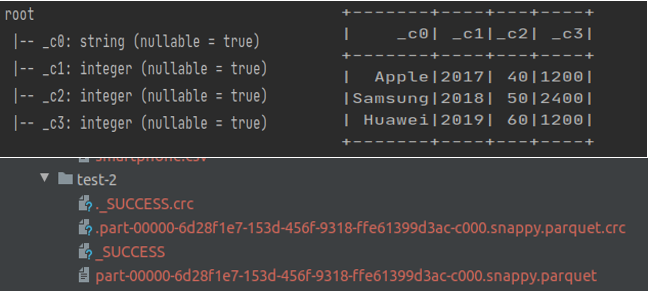
让我们读取另一个输入 CSV 文件,其中“Cost”列具有十进制值而不是整数(如下所示),并对上述文件执行追加操作
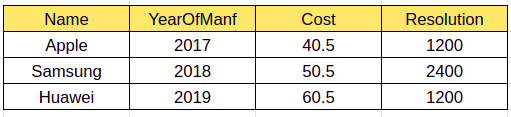
在这种情况下,我们的程序将读取 CSV,毫无例外地写入 Parquet 格式。当我们想要显示/显示数据帧时,我们的程序将抛出错误
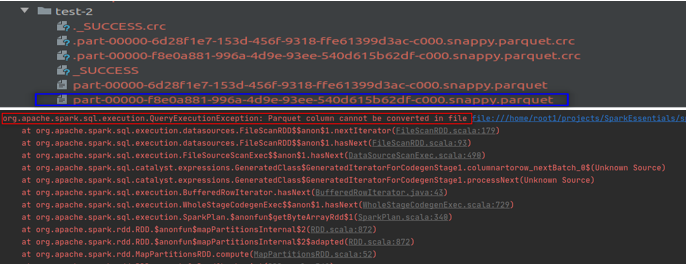
这是因为 Spark 在写操作期间从不验证模式。 “Cost”列的模式在第一次加载期间被推断为整数,在第二次写入期间,它会毫无问题地附加双精度型数据。当我们读取附加数据并调用操作时,由于模式不兼容,它会引发错误。
如果我们使用 Apache Spark 将 CarbonData 作为存储解决方案的附加层插入,则可以管理上述问题。
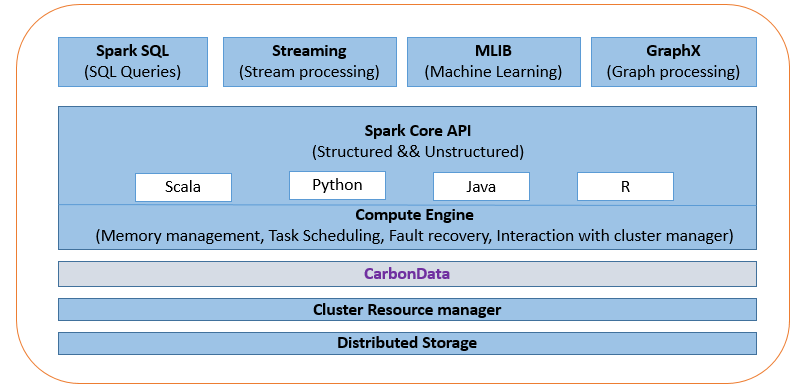
由于 Hadoop 分布式文件系统 (HDFS) 和对象存储类似于文件系统,因此它们不是为提供事务支持而设计的。在分布式处理环境中实现事务是一个具有挑战性的问题。例如,实施通常必须考虑锁定对存储系统的访问,这是以整体吞吐量性能为代价的。 Apache CarbonData 等存储解决方案通过将这些事务语义和规则推送到文件格式本身或元数据和文件格式组合中,有效地解决了数据湖的这些 ACID 要求。 CarbonData 在 Apache Spark 和存储系统之间起到中介服务的作用。现在,遵守 ACID 的责任由 CarbonData 负责。底层存储系统可以是 HDFS、华为 OBS、Amazon S3 或 Azure Blob Storage 之类的任何东西。 CarbonData 为 Spark 提供的几个重要功能是:
1. ACID transactions.
2. Schema enforcement/Schema validation.
3. Enables Updates, Deletes and Merge.
4. Automatic data indexing.
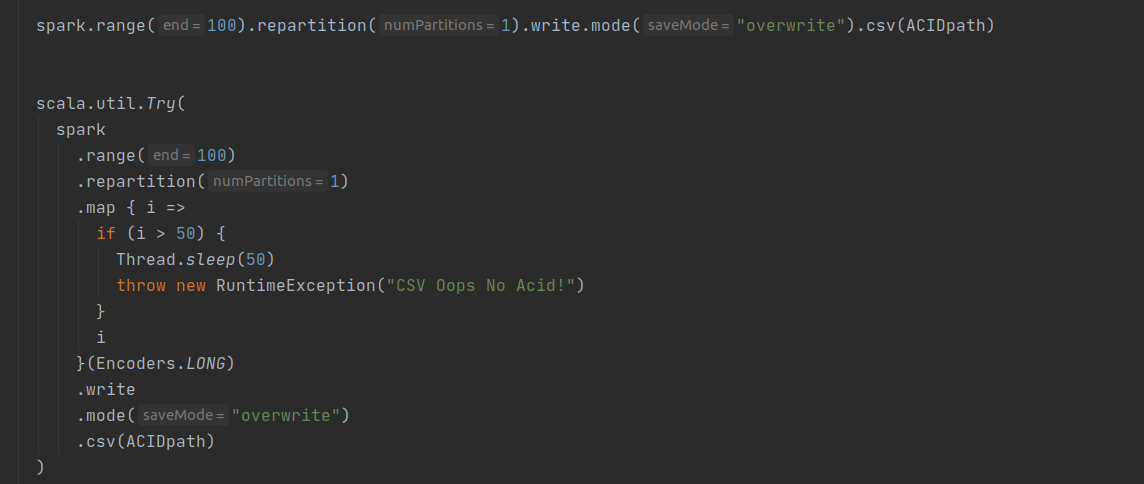
在上面的代码片段中,代码的第一部分模仿了 job-1,创建了 100 条记录并将其保存到 ACIDpath 目录中。代码的第二部分模仿 job-2,它试图覆盖现有数据但在操作过程中抛出异常。
这两项工作的结果是数据丢失。最后,我们丢失了第一个作业创建的数据。现在让我们更改如下所示的代码以使用 CarbonData。
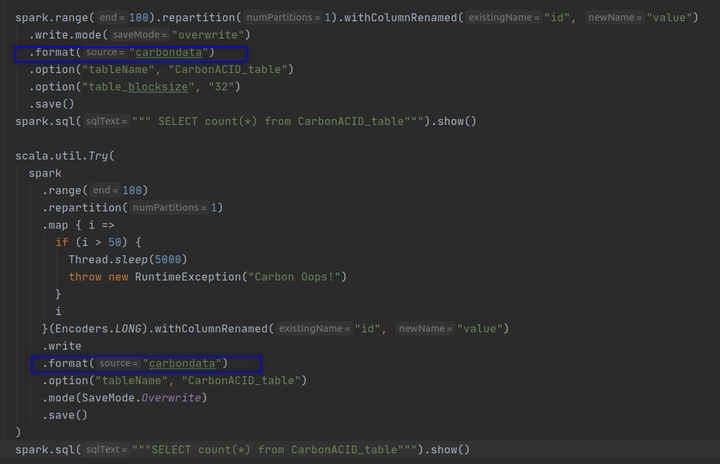
执行第一个作业并计算行数。正如预期的那样,您将获得 100 行。
如果您检查数据目录,您将看到一个snappy compressed CarbonData 文件。该数据文件以列式编码格式保存 100 行。您还将看到一个包含 tablestatus 文件的元数据目录。现在执行第二个作业。你对第二份工作有什么期望?如前所述,这项工作应该尝试做以下事情。
1. 删除之前的文件。
2. 创建一个新文件并开始写入记录。
3. 在作业中间抛出运行时异常。
由于异常,作业级别提交不会发生,我们丢失了上述观察到的现有数据在没有使用 CarbonData 的情况下。
但是现在如果你执行第二个作业,你仍然会得到一个异常。然后,计算行数。您得到的输出为 100,并且不会丢失旧记录。看起来 CarbonData 已经使 Overwrite 原子化了。我们看一下数据目录,你会发现两个 CarbonData 文件。
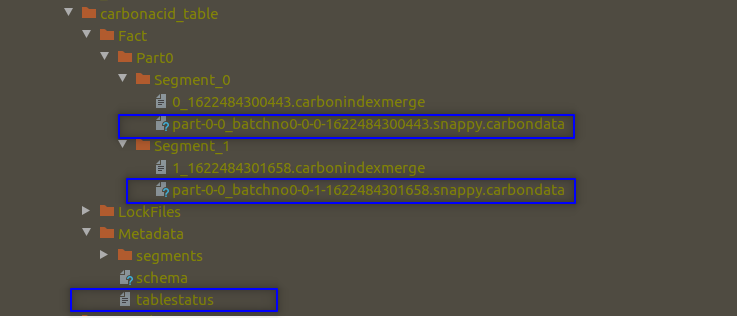
一个文件由第一个作业创建,另一个文件由作业 2 创建。作业 2 没有删除旧文件,而是直接创建了一个新文件并开始向新文件写入数据。这种方法使旧数据状态保持不变。这就是为什么我们没有丢失旧数据的原因,因为旧文件保持不变。新的不完整文件也在那里,但不读取新的不完整文件中的数据。该逻辑隐藏在元数据目录中,并使用 tablestatus 文件进行管理。第二个作业无法在 tablestatus 文件中创建成功的条目,因为它在中间失败了。读取 API 不会读取 tablestatus 文件中的条目被标记为删除的文件。

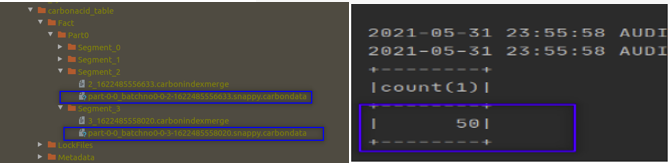
这一次,让我们无一例外地编写代码逻辑,用50条记录覆盖旧的100条记录。
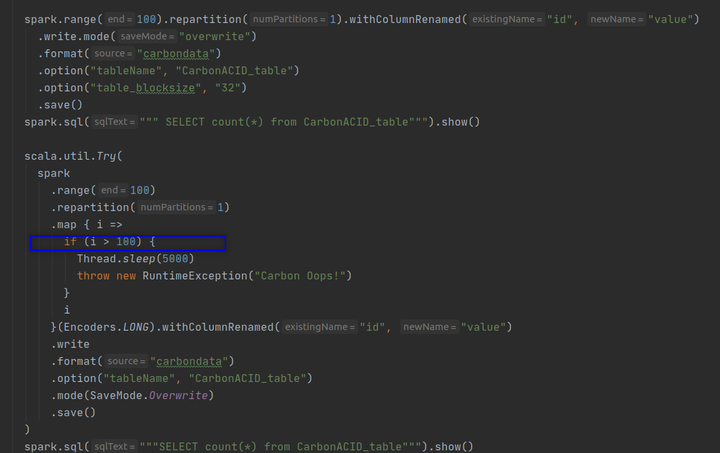
Now the record count shows 50. As expected. So, you have overwritten the older data set of 100 rows with a new data set of 50 rows.
CarbonData 将元数据管理引入 Apache Spark 并使 Spark 数据编写器 API 具有原子性,从而解决了数据一致性问题。一旦一致性问题得到解决,CarbonData 将能够提供更新和删除功能。
让我们考虑一个简单的用户场景,其中数据分多批到达以进行转换。这里为了简单起见,让我们假设只有 2 批数据,第二批数据携带一些与第一批数据不同类型的列数据。

为了开始实验,让我们从表 1 中读取数据,并使用和不使用 CarbonData 写入数据。我们能够使用“Overwrite”模式在有和没有 CarbonData 的情况下写入数据。
现在让我们读取具有成本列类型的双类型数据的第二个表,然后将数据帧写入 Parquet 和 CarbonTables(注意:_c2 是整数类型,我们正在尝试附加双类型数据)。使用 parquet 附加模式不匹配的数据没有问题,但是当程序尝试将相同的数据附加到 CarbonData 表时,它会抛出错误:
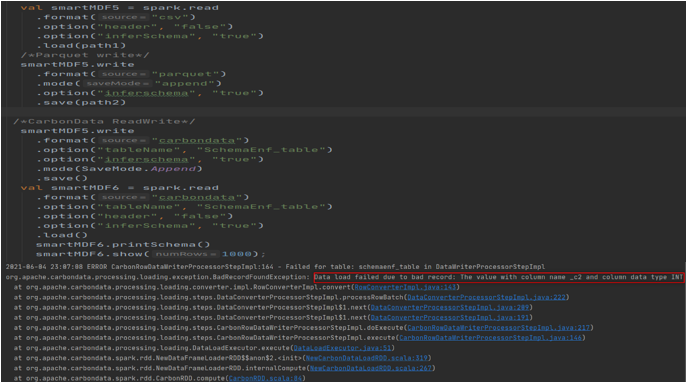
因此,基于上述实验,我们可以看到 CarbonData 在写入底层存储之前验证模式,这意味着 CarbonData 在写入时使用模式验证。如果类型不兼容,则 CarbonData 将取消交易。这将有助于在开始时跟踪问题,而不是与好的数据混淆,然后尝试找出根本原因。
英文链接:https://brijoobopanna.medium.com/making-apache-spark-better-with-carbondata-d37f98d235de
作者: Brijoobopanna
看CarbonData如何用四招助力Apache Spark
标签:状态保持 tar 工作 平滑 path 元数据 block size actual
原文地址:https://www.cnblogs.com/huaweiyun/p/14954977.html