标签:des winform style blog http io ar color os
一 本系列随笔概览及产生的背景
本系列开篇受到大家的热烈欢迎,这对博主是莫大的鼓励,此为本系列第三篇,希望大家继续支持,为我继续写作提供动力。
自己开发的豆约翰博客备份专家软件工具问世3年多以来,深受广大博客写作和阅读爱好者的喜爱。同时也不乏一些技术爱好者咨询我,这个软件里面各种实用的功能是如何实现的。
该软件使用.NET技术开发,为回馈社区,现将该软件中用到的核心技术,开辟一个专栏,写一个系列文章,以飨广大技术爱好者。
本系列文章除了讲解网络采编发用到的各种重要技术之外,也提供了不少问题的解决思路和界面开发的编程经验,非常适合.NET开发的初级,中级读者,希望大家多多支持。
很多初学者常有此类困惑,“为什么我书也看了,C#相关的各个方面的知识都有所了解,但就是没法写出一个像样的应用呢?”
这其实还是没有学会综合运用所学知识,锻炼出编程思维,建立起学习兴趣,我想该系列文章也许会帮到您,但愿如此。
开发环境:VS2008
本节源码位置:https://github.com/songboriceboy/GetWebAllPics
源码下载办法:安装SVN客户端(本文最后提供下载地址),然后checkout以下的地址:https://github.com/songboriceboy/GetWebAllPics.git
系列文章提纲拟定如下:
二 第三节主要内容简介(如何使用C#语言下载博文中的全部图片到本地并可以离线浏览)
网页的抓取主要分为3步:
1.通过分页链接抓取到全部文章链接集合(第一节内容)
2.通过每一个文章链接获取到文章的标题及正文(第二节内容)
3.从文章正文中解析出全部图片链接,并将文章的全部图片下载到本地(本节内容)
这3步有了,之后你就想怎么折腾就怎么折腾了,各种加工处理,生成pdf,chm,静态站点,远程发布到其他站点等等。
如何使用C#语言下载博文中的全部图片到本地并可以离线浏览的解决方案演示demo如下图所示:可执行文件下载
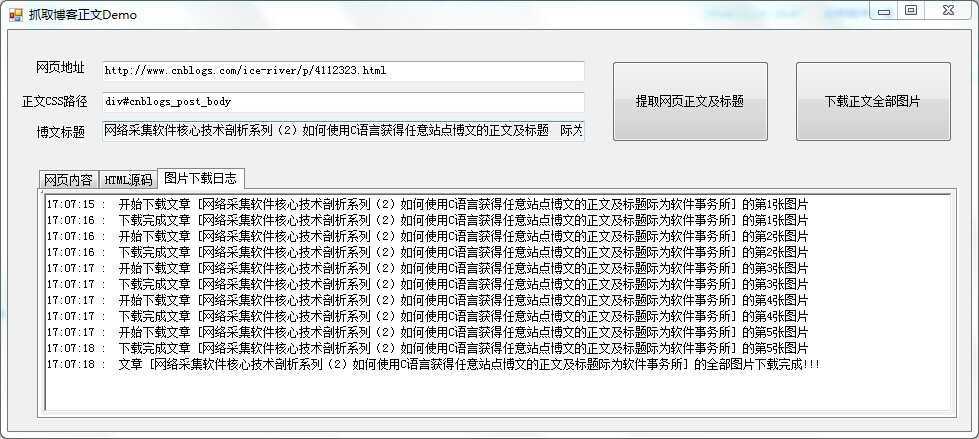
点击下载正文全部图片按钮后,会在可执行程序所在目录生成一个文件夹(文字为该网页的标题),文件夹中包含一个html文件(网页正文)以及网页正文中的全部图片。该html文件对最初正文html文件进行了处理,其中的图片链接均修改成了本地图片文件。
三 基本原理
下载博文中的全部图片可以分解成3步:
1.下载网页正文,找出其中的全部图片链接地址;
2.对于每一个图片链接地址,下载该图片到本地(起一个文件名),同时替换原来的图片地址为我们刚刚起的文件名;
3.第二步全部图片下载完成后,将所有图片链接替换后的网页正文保存为一个新的html文件(index.html)。
接下来我们就一步一步来看一下如何做:
1.下载网页正文,找出其中的全部图片链接地址;
如何下载网页正文请参考第二节内容,下面咱们看一下如何来获取网页正文中的全部图片链接:
private void GetSrcLinks() { HtmlNodeCollection atts = m_Doc.DocumentNode.SelectNodes("//*[@src]"); if (Equals(atts, null)) { return; } Links = atts. SelectMany(n => new[] { ParseLink(n, "src"), }). Distinct(). ToArray(); }
通过HtmlAgilityPack中的HtmlDocument类找出全部src属性的节点,再通过linq提取出其中的网页地址。
2.对于每一个图片链接地址,下载该图片到本地,如下代码所示:
DocumentWithLinks links = htmlDoc.GetSrcLinks(); int i = 1; string baseUrl = new Uri(strLink).GetLeftPart(UriPartial.Authority); foreach (string strPicLink in links.Links) { if (string.IsNullOrEmpty(strPicLink)) { continue; } try { string strExtension = System.IO.Path.GetExtension(strPicLink); if (strExtension == ".js" || strExtension == ".swf") continue; if (strExtension == "") { strExtension = ".jpg"; } string normalizedPicLink = GetNormalizedLink(baseUrl, strPicLink); strNewPage = DownLoadPicInternal(wc, strNewPage, strPageTitle, strPicLink, normalizedPicLink, strExtension, ref i); } catch (Exception ex) { } //end try }
其中 DownLoadPicInternal的实现代码如下:
protected string DownLoadPicInternal(WebClient wc, string strNewPage, string strPageTitle, string strPicLink , string strTureLink, string strExtension, ref int i) { strPageTitle = strPageTitle.Replace("\\", "").Replace("/", "").Replace(":", "").Replace("*", "").Replace("?", "") .Replace("\"", "").Replace("<", "").Replace(">", "").Replace("|", ""); strPageTitle = Regex.Replace(strPageTitle, @"[|•/\;.‘:*?<>-]", "").ToString(); strPageTitle = Regex.Replace(strPageTitle, "[\"]", "").ToString(); strPageTitle = Regex.Replace(strPageTitle, @"\s", ""); if (!Directory.Exists(Application.StartupPath + "\\" + strPageTitle))//判断是否存在 { Directory.CreateDirectory(Application.StartupPath + "\\" + strPageTitle);//创建新路径 } int[] nArrayOffset = new int[2]; nArrayOffset = m_bf.getOffset(strPicLink); strNewPage = strNewPage.Replace(strPicLink, nArrayOffset[0].ToString() + nArrayOffset[1].ToString() + strExtension); string strSavedPicPath = Path.Combine(strPageTitle, nArrayOffset[0].ToString() + nArrayOffset[1].ToString() + strExtension); PrintLog(" 开始下载文章 [" + strPageTitle + "] 的第" + i.ToString() + "张图片\n"); strTureLink = HttpUtility.UrlDecode(strTureLink); wc.DownloadFile(strTureLink, Application.StartupPath + "\\" + strSavedPicPath); PrintLog(" 下载完成文章 [" + strPageTitle + "] 的第" + i.ToString() + "张图片\n"); System.Threading.Thread.Sleep(300); i++; return strNewPage; }
其中粉色代码部分m_bf变量是BloomFilter类型的一个对象,BloomFilter是一个网页去重的强大工具,这里是为了将图片链接转化为一个独一无二的文件名。
strNewPage = strNewPage.Replace(strPicLink, nArrayOffset[0].ToString() + nArrayOffset[1].ToString() + strExtension);
此行代码是用新的图片文件名替换原网页中的图片链接。其他部分的代码之前章节均有解释,请自行参考。
3.第二步全部图片下载完成后,将所有图片链接替换后的网页正文保存为一个新的html文件(index.html),主要代码如下:
strPageTitle = strPageTitle.Replace("\\", "").Replace("/", "").Replace(":", "").Replace("*", "").Replace("?", "") .Replace("\"", "").Replace("<", "").Replace(">", "").Replace("|", ""); strPageTitle = Regex.Replace(strPageTitle, @"[|•/\;.‘:*?<>-]", "").ToString(); strPageTitle = Regex.Replace(strPageTitle, "[\"]", "").ToString(); strPageTitle = Regex.Replace(strPageTitle, @"\s", ""); File.WriteAllText(Path.Combine(strPageTitle, "index.html"), strNewPage, Encoding.UTF8);
上面的一堆替换是因为windows对文件夹名有要求---不能包含一些特殊字符,这里我们通过正则替换去掉这些特殊字符。
到此为止,我们就实现了将任意网页中的正文中的图片下载到本地的功能,并同时修改了原来网页正文中的图片链接,以达到可以离线浏览的目的。
以后的生成pdf,chm均以此为基础,这一节是重中之重,有兴趣的同学可以扩展我提供的代码,将它改造成某个站点的图片采集器应该也是一件简单的事情。
四 下节预告
使用C#语言如何将html网页转换成pdf(html2pdf)。
网络采集软件核心技术剖析系列(3)---如何使用C#语言下载博文中的全部图片到本地并可以离线浏览
标签:des winform style blog http io ar color os
原文地址:http://www.cnblogs.com/ice-river/p/4119095.html