标签:style blog http io ar color os 使用 sp
前言:
上一篇简单的讲解了下Hibernate的基础知识。这里对Hibernate比较重要的一些知识点,进行总结和归纳。
手码不易,转载请注明!——xingoo
总结的知识点:
1 关于hibernate映射的实体类标识符访问权限
2 关于对象描述标识符OID及其生成策略
3 Session缓存——清理缓存
4 Session中的状态变更
5 Session中的常用方法
首先简单的看下整理的思维导图,还没有整理完,所以仅仅是一部分而已。
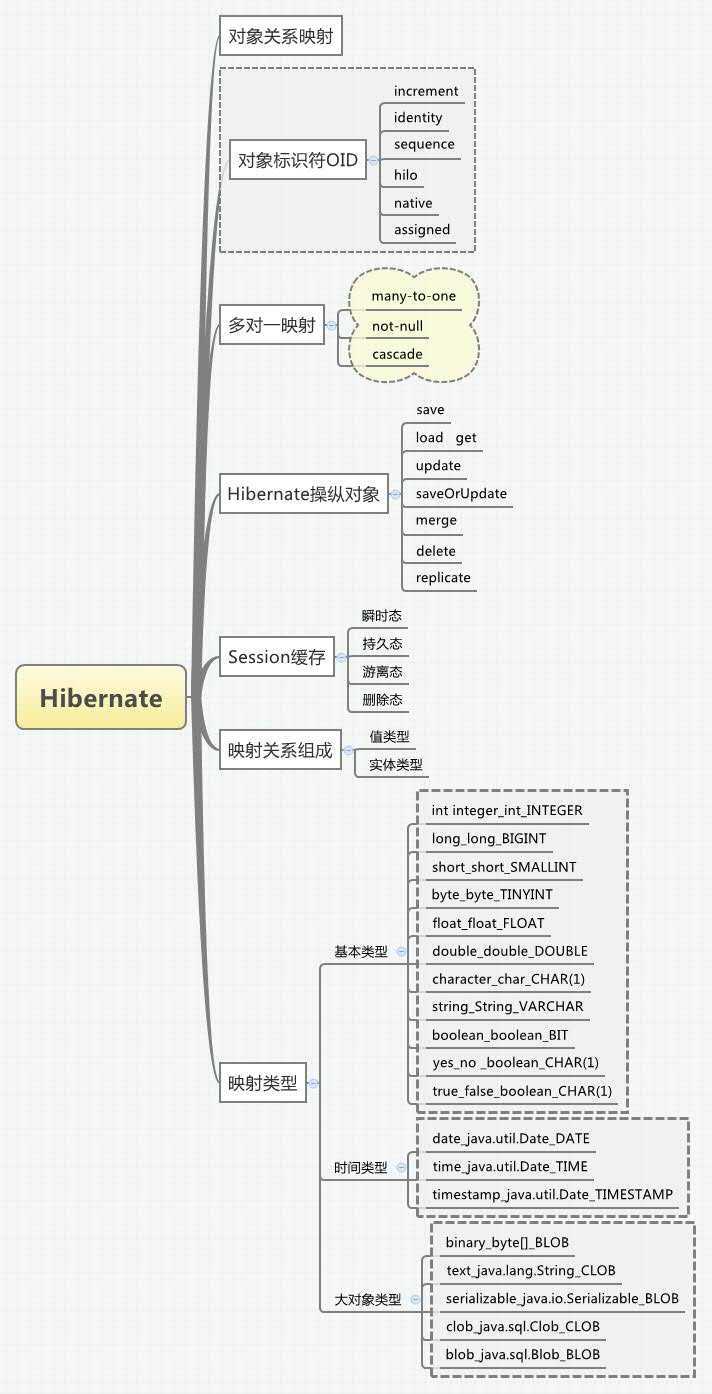
关于Hibernate的映射要说明的一点就是关于ID的访问权限,property以及field的区别。以前使用的时候根本没有注意过这个问题,这里简单的强调一下。
表的主键在内存中对应一个OID对象描述标识符,需要在xml的配置文件中要指定对象标识符的生成方式。
assinged是自然主键的方式,这种策略需要用户指定ID才可以,在这个知识点里先忽略。
其他的方式比如sequence通过序列生成主键。identity,increment等是自动增长。这种方式生成的主键一般是由hibernate完成的,所以我们在编写实体对象的时候,id的get和set方法权限应该注意:
class XXX{ private long id; public long getId(); private void setId(); }
这里应该设置get的访问权限是public的,set的访问权限是private的。由于hibernate在访问实体模型时,是不考虑权限的,因此这样就避免了用户指定主键。
另外一个知识点就是,如果不通过property指定一个列,而使用field。那么hibernate就会直接访问属性,而不会通过get set访问属性。
这一块相对来说也是hibernate的重点,什么是OID?如何指定OID?OID与主键是什么关系?
什么是OID?
OID 全拼是object identifier,也就是对象标识符。因为数据库表中一般都通过主键来识别一个表中的不同行,而JVM中一般使用地址来识别不同的对象。在Session缓存中,当然也需要一个标识符来表示不同的缓存对象。因此,OID也就排上了用场。
由于涉及到缓存的概念,就先说一下缓存!
上节说过,SessionFactory是重量级的缓存,里面包含了数据库的连接,预定义的SQL等等。而Session的缓存是轻量级的,里面包含一些增删改查的对象。
如果同一个JVM中的对象,加入到不同的session中,也是不同的缓存对象。而不同的对象加入到同一个Session中,也需要保证OID不同。因为Session不管你存的是什么,都需要通过对象标识符来检索对象。
如何指定OID?
通常分为两种:
1 自然主键,也就是带有业务含义的,比如学生的学号,工作的编号,通常包含了年份,部门或者班级,专业等等业务上的意义,因此需要手动的合成或者拼接指定。这种情况下就需要使用assinged方式,这种方式如果不指定主键就提交缓存进行更新,会报错!
2 代理主键,也就是没有业务含义的,通常是通过编码自动生成的。
increment:不依赖于底层数据库,适合单个数据库场合不适合集群,必须为long int short类型。插入式,先选择最大的id值,再加1
identity:依赖底层数据库系统。支持自动增长字段: OID 为long,int,short
sequence:MYSQL不支持序列。依赖底层,必须支持序列。Oracle db2 sap db postgresql
hilo:计算公式hi*(max_lo+1)+lo 不依赖底层数据库系统,Long,int,short,只能在一个数据库中保持唯一
native:跨平台,自动选择使用哪个策略。
由于上面的identity,sequence都需要依赖于底层数据库,不同的数据库可能不支持这种方式。那么一般推荐使用native,自动进行选择。
OID与主键是什么关系?
一般来说,OID就是一个对象持久化之前是null,持久化的时候hibernate或者我们手动指定一个id,这个ID被插入到数据库当做主键,在session中当做索引。也因为这个原因,需要保证OID与主键的一致性,比如类型啊,长度之类的。
缓存的概念,一般学过基础理论的都应该理解,就是为了缓冲数据,减少与真实数据库的频繁交互。与计算机的缓存类似,经常访问硬盘效率太低,IO太慢,就把内存当做缓存,CPU每次与内存直接交互,内存中找不到的数据再去读硬盘。内存又觉得慢了,就弄个Cahce当做缓存,经常访问的数据再放到这里,更加快了速度。
Session缓存也是如此,与Web中的Session也类似。在网页中,也有Session这样一种概念,比如我们登陆淘宝,会记录我们的用户信息,当浏览器关闭或者退出时,Session关闭。这期间就完全通过Session来识别用户的身份,无需每次登陆进行校验。Hibernate中也是如此,我们从SessionFactory中开启这个Session,持久化一个对象,然后提交事务,增删改查,最后关闭Session,就像一个对话一样。
那么Session缓存具体有什么作用呢?
比如我们通过Session.get(xxx.class,new Long(1));来获取Session中OID为1的对象,它会首先到缓存中查找,如果找到了就直接用。如果找不到就去读取数据库,然后存储到缓存中!第二次,就可以直接从缓存中获取数据了!
这样就减少了访问数据库的频率!
另外,我们频繁的修改一个对象,如果这个对象放在缓存中,而且还是用了事务,那么只有事务在commit的时候,才会执行真正的SQL语句!
这样就对对象与数据库的表进行了动态的映射!
Session缓存又是什么时候提交清理的呢?
1 当使用事务时,transaction.commit()会触发缓存的清理。
2 直接调用Session.flush()也会触发缓存的清理。
3 如果使用的是native,那么在持久化的时候也会清理缓存,也就是session.save()时。
4 执行查询时。
这里就不得不提一下commit与Session的flush的区别了:
当使用flush时,并没有提交事务,只是清理缓存而已。
而commit的时候,是先调用flush再提交事务。
这又是Hibernate的一大块重点!
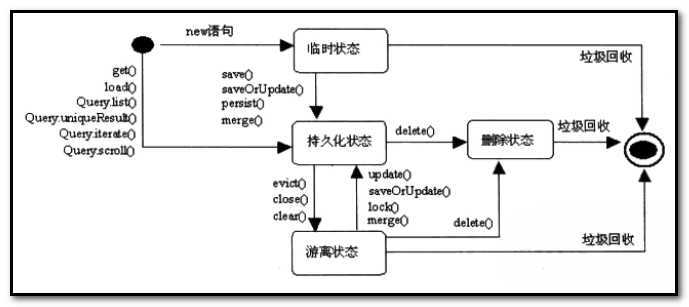
save()
Session调用save时,一般都是创建或者获取到了一个瞬时态的对象,这时对象的OID有可能是空的,session需要指定生成一个OID。再计划生成一条insert语句,这条语句只是简单的缓存起来,当事务提交时才执行。而持久化的对象,OID是不能随便更改的,这也是为什么前面的setId推荐设置成private的访问权限。
load()和get()
他们都是加载一个对象,或者从缓存中查找。区别在于,如果使用load,如果数据库中不存在该对象对应的数据,会抛出异常。而get会得到null。
update()
这个方法是把一个游离态的对象持久化,比如一个对象如果session清理了,那么session中就找不到这个对象了,但是数据库中仍然存在。我们通过这个对象的引用,可以通过update在Session中创建它的实例。这样,会生成一条update语句。如果此后在修改无论多少次,都只会生成一条update语句。总结起来就是,update方法,会生成一条对应的update语句来同步缓存与数据库中的对象。
如果数据库中对应的表设置了触发器,那么就蛋疼了、!因为无论你是否修改了数据,都会生成一条update语句,这样就会导致触发了大量无效的触发器。不要担心,可以通过设置select-before-update属性,一看名字就能猜到,是在update前,进行一次select,如果数据一致,就必须要update了,如果数据不一致,才update。
saveOrUpdate()
这个方法就给力了,它会自动判断传入的参数是什么类型的,然后采取什么措施!完全的自动化,最喜欢这样的了!跟native一个套路。
merge()
对象的复制,它首先获取到OID,然后去session中查找是否存在这样的对象,如果存在直接修改或者使用;如果不存在,就复制这个对象的属性。
delete()
如果删除的对象时一个游离态的对象,那么需要先进行持久化,在删除。
replicate()
这个方法可以跨Sessionfactory拷贝对象。
这次的总结,大致就是以上内容。后续还会继续总结常用的知识点。
【Hibernate那点事儿】—— Hibernate知识总结
标签:style blog http io ar color os 使用 sp
原文地址:http://www.cnblogs.com/xing901022/p/4151875.html