标签:style blog c code tar http
本来要自己翻译的,随手搜索了一下,发现五天前已经有人翻译了,我就不重复发明轮子了。
转自:http://blog.csdn.net/yutianzuijin/article/details/26289257
前不久在微博上看到一篇很好的短文讲如何对C/C++进行性能优化,虽然其面向的领域是图形学中的光线跟踪,但是还是具有普遍的意义,将其翻译成中文,希望对大家写高质量代码有帮助。
1. 牢记阿姆达尔定律:
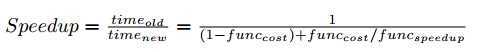
- 其中
 表示函数func运行时间占总时间的百分比,
表示函数func运行时间占总时间的百分比, 表示对该函数加速获得的加速比。
表示对该函数加速获得的加速比。
- 例如,你优化一个函数TriangleIntersect(),该函数的运行时间占总时间的40%,优化之后运行时间缩短一半,则整个代码会获得25%的性能提升
 。
。
- 这个公式告诉我们不常用的代码(例如场景加载程序)没有必要优化(或者完全不用优化)。
- 一句话总结“使常用代码更快,不常用代码正确”。
2. 在保证正确性的前提下去优化代码!
- 但是这不意味着你需要首先耗费8周的时间去实现一个完整的光线跟踪代码,然后再花费另外的8周去优化!
- 代码优化要分成多个步骤。
- 首先编写正确的代码,然后寻找被经常调用的函数,对其进行优化。
- 最后寻找整个代码的瓶颈,通过优化或者修改算法去除瓶颈。通常算法的改进可能会使代码的瓶颈转移—甚至会转移到你意想不到的函数中。由于这个原因的存在,我们需要对经常访问的所有函数进行显式优化。
3. 我认识的代码高手都自称他们优化代码的时间是写代码时间的两倍。
4. 跳转/分支操作很耗时。如果可能尽可能的少用它们。
- 函数调用除了栈上内存的操作之外,还包括两个跳转操作。
- 尽量用迭代而不是递归。
- 对代码长度较短的函数要将其设置为内联函数以减小函数调用的开销。
- 将循环放在函数内部(例如,代码:for(i=0;i<100;i++)DoSomething();
可以修改为DoSomething(){for(i=0;i<100;i++){…}},以此可以减少函数调用的次数)。
- 具有很长if…else if…else if…else
if…链的代码在判断后面的条件时需要非常多的跳转操作。如果可能,将其改为switch代码结构,因为switch通过查询一个跳转表实现了单步跳转。如果不能改为switch结构,要将最可能被访问的判断条件放在条件链的最前面。
5. 仔细考虑数组下标的顺序。
- 二维或者更高维的数组在内存中实际上还是一维形式的存在。这就说明(针对C/C++数组)元素array[i][j]和array[i][j+1]在内存中位置相邻,但是元素array[i][j]和array[i+1][j]却可以相差任意个位置。
- 如果我们在访问内存中数组的时候是以一种近似线性的顺序实现的,代码通常会获得非常明显的加速(有时会达到一个数量级,甚至更高)!
- 现在的CPU在从内存加载数据到缓存时,它不会只加载要访问的一个数据,而是会将一块内存(cache
line)都加载到缓存中。这意味着当元素array[i][j]在缓存中时,array[i][j+1]也很有可能在缓存中,但是array[i+1][j]却依旧在内存中。
6. 考虑指令级并行。
- 尽管目前还有很多程序是单线程执行的,但是现在的CPU早就在单核上实现了并行。这就意味着在单核上可能会同时执行4个浮点乘法,等待4个内存请求和即将到来的分支操作。
- 为了充分利用指令级并行,代码块(跳转指令之间)需要有充足的独立指令(指令之间没有相关性:数据相关、控制相关和名字相关)。
- 可以考虑循环展开。
- 考虑内联函数。
7. 避免使用或者减少局部变量的数量。
- 局部变量通常放在栈空间中。但是如果局部变量的个数足够少,它们可以被放在寄存器中。在这种情况下,函数可以获得比内存快得多的访问速度,同时也避免了栈空间的布局。
- 但是,也不要为了减少局部变量的个数将它们全都变为全局变量。
8. 减少函数的参数。
9. 结构体按照引用而不是按照值传递。
- 据我所知,光线跟踪代码中没有什么结构体需要按值传递(即使简单的向量,点和颜色等结构)。
10. 如果函数不需要返回值,就不要定义返回值。
11. 尽可能地避免类型强转。
- 整型和浮点型指令操作通常在不同的寄存器中,所以类型强转意味着数据的复制。
- 短整型(char和short)仍然需要一个完整的寄存器来存储。在存到内存中时,才再次转换成字节存储(不过是否需要强转还需要考虑空间耗费的因素,强转节省空间但是费时)。
12. 声明C++对象变量的时候要各位仔细。
- 使用对象的初始化而不是赋值操作(Color c(black);比Color c;
c=black;要快)。
13. 将类的默认构造函数设计得尽量小。
- 特别是那些很小但是经常被使用的类(如color,vector,point等)。
- 默认构造函数经常会在你想不到的时候调用。
- 使用构造函数初始化列表(使用Color::Color():r(0),g(0),b(0){},而不是Color::Color(){r=g=b=0;})。
14. 尽可能使用移位操作>>和<<代替整数的乘除法。
15. 在使用查表函数时要谨慎(光线跟踪专用)。
- 很多人都建议查表使用预先计算的值来代替复杂的函数(例如三角函数)。但是在光线跟踪中,这通常没有必要。内存查找很耗时,这会抵消重新计算三角函数的时间(尤其是考虑到查表会破坏CPU的缓存结构时)。
- 在其他场合下,查表通常会很有帮助。在GPU编程中,查表替代复杂操作是允许的。
16. 对大多数类操作,使用+= ,-= , *= , and /=而不是+ , - , * , and
/。
- 简单操作是用来创建未命名或者临时中间对象的。
- 例如:Vector v = Vector(1,0,0) +Vector(0,1,0) +
Vector(0,0,1);创建了5个未命名、临时向量:Vector(1,0,0), Vector(0,1,0),
Vector(0,0,1), Vector(1,0,0) +Vector(0,1,0), 和Vector(1,0,0)
+Vector(0,1,0)+ Vector(0,0,1)。
- 稍微长一点的代码:Vector v(1,0,0); v+=Vector(0,1,0); v+=
Vector(0,0,1);仅创建了两个临时变量:Vector(0,1,0)
andVector(0,0,1)。这会节约6次函数调用(3次构造函数和3次析构函数)。
17. 对于基本数据类型采用+ ,- , *,/而不是+= , -= , *= , and /=。
18. 推迟局部变量的声明。
- 声明一个类对象需要一次函数调用(对构造函数的调用)。
- 如果一个变量只在某个条件下使用,则只在真正需要的地方声明该变量。
19.
对于对象(基本变量已被优化),使用前缀操作(++obj)代替后缀操作(obj++)。
- 在光线跟踪中这不是一个问题。
- 后缀操作会带来一次对象的复制(这需要额外调用一次构造函数和析构函数),但是前缀操作不需要临时的复制。
20. 使用模板的时候要小心。
- 不同实例化的优化方法不同!
- 标准模板类已经被优化得很彻底,但是还是避免使用它。
- 为什么不用?这是因为如果我们自己实现某个算法,我们就会知道算法细节以及优化方式。
- 更重要的是,我的经验告诉我在debug模式下编译包含STL的代码通常会很缓慢。这一般不是一个问题,除非你使用debug版本进行性能分析。你将会发现STL构造器,迭代器等会占用15%以上的运行时间,这将导致性能输出结果令人迷惑。
21. 在计算的过程中避免动态内存分配。
- 动态内存分配适合于存储场景和计算过程中不变的数据。
- 然而,在大多数系统中,动态内存分配需要利用锁来控制分配器的访问。对于多线程应用,增加额外的处理器也可能会使性能下降,因为使用动态内存分配会导致线程不停地等待内存的分配和释放。
- 即使是对单线程应用,在堆上分配内存也比在栈上分配内存更耗时。因为操作系统需要做一些计算来寻找合适大小的内存块。
22. 寻找和利用可以优化系统缓存访问的一切信息。
- 如果一个数据结构可以存放于单个cache line,则单次内存访问就可以将整个类加载到缓存中。
- 确保你的数据结构对齐到cache line的边界(如果你的数据结构和cacheline都是128字节,但是结构体的第1个字节在第一个cache
line中,剩余的127字节在第二个cache line中,那么性能还是会非常差)。
23. 避免不必要的数据初始化。
- 如果你需要初始化大块内存,请使用memset()。
24. 尝试循环的提前终止和函数的提前返回。
- 考虑一条光线和一个三角形的交。合理的情况是光线通不过三角形。这就是需要优化的地方。
- 如果你需要确定光线和三角平面的交,当光线-平面交的t值为负时你可以离开返回。这使你避免了求交过程中大约一半的质心计算。
25. 在纸上简化方程。
- 在很多方程中,其实有些项在某些情况下可以被约去。
- 编译器不能发现方程的简化,但是你行。有时只是消除内部循环的一些耗时操作就可以抵上你在其他地方工作好几天的成果。
26. 整数、浮点数在数学上的差异可能没有想象中大。
- 在现代CPU中,浮点运算具有和整数运算相同的吞吐量。像光线跟踪这样的计算密集型应用,浮点操作和整数操作的差异非常小。所以,没有必要想方设法将操作转成整数操作。
- 双精度浮点数操作可能比单精度慢,特别是在64位机器上。但是也可能会反过来。
27. 考虑将运算表达式变形以减少耗时操作。
- sqrt()操作应该尽量被避免,特别是通过平方操作也可以获得同样结果时。
- 如果你需要频繁的进行除以x的操作,可以考虑首先计算,然后将结果乘以
 。这在向量归一化(3次除法)中会带来较大收益。但是最近我发现情况变得有点难以判断。不过,如果除法次数超过3次时,这种优化方法还是会带来较大的性能提升。
。这在向量归一化(3次除法)中会带来较大收益。但是最近我发现情况变得有点难以判断。不过,如果除法次数超过3次时,这种优化方法还是会带来较大的性能提升。
- 如果你在执行一个循环,请把计算结果保持不变的运算提到循环外面完成。
- 考虑是否可以增量计算一个变量(而不是每次都从头开始计算该变量)。
(转)Tips for Optimizing C/C++ Code,布布扣,bubuko.com
(转)Tips for Optimizing C/C++ Code
标签:style blog c code tar http
原文地址:http://www.cnblogs.com/xubenben/p/3750064.html