标签:
这次 我们以指定executor-memory参数的方式来启动spark-shell:

启动成功了
在命令行中我们指定了spark-shell运行暂用的每个机器上的executor的内存为1g大小,启动成功后参看web页面:

从hdfs上读取文件:
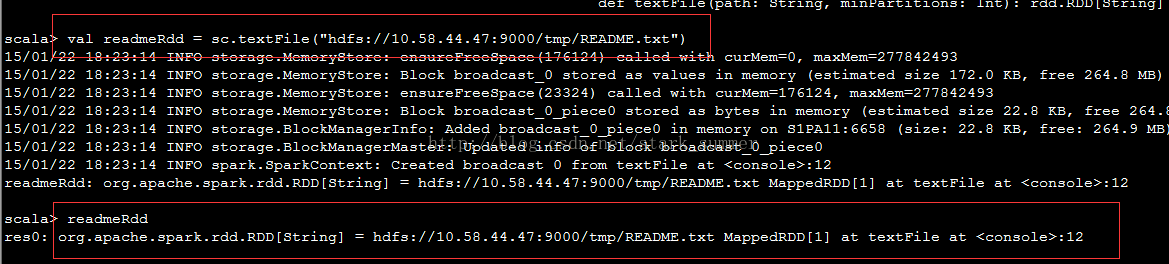
在命令行中返回的MappedRDD,使用toDebugString,可以查看其lineage的关系:

可以看出MappedRDD是从HadoopRDD转换而来的
再看下textFile的源代码:

hadoopFile这个方法返回的是一个HadoopRDD,源码如下所示:


而map方法产生的是一个MappedRDD:

下面进行一个简单的wordcount操作:

执行结果:

再次使用toDebugString,查看下依赖关系:

HadoopRDD -> MappedRDD -> FlatMappedRDD -> MappedRDD -> ShuffledRDD
Spark API编程动手实战-05-spark文件操作和debug
标签:
原文地址:http://my.oschina.net/u/230960/blog/374569