标签:
首先创建SparkContext上下文:

接着引入隐身转换,用于把RDD转成SchemaRDD:

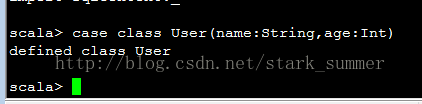
接下来定义一个case class 来用于描述和存储SQL表中的每一行数据:
接下来要加载数据,这里的测试数据是user.txt文件:
我们创建好use.txt增加内容并上传到hdfs中:

web控制台查询:

hdfs命令查询:

加载数据:

验证数据是否加载成功:

注册成为user的table:

此刻user还是一个MappedRDD:

执行age 大于13 小于19的SQL查询:
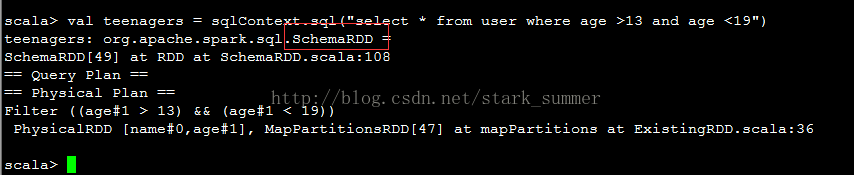
此刻的teenagers已经隐身转换成SchemaRDD
通过collect操作触发job的提交和执行:

结果:

DSL是Domain Specific Language的缩写,使用DSL我们可以直接基于读取的RDD数据进行SQL操作,无需注册成Table。
我们重新启动下spark-shell:
同样使用"user.txt"的数据:

验证user:
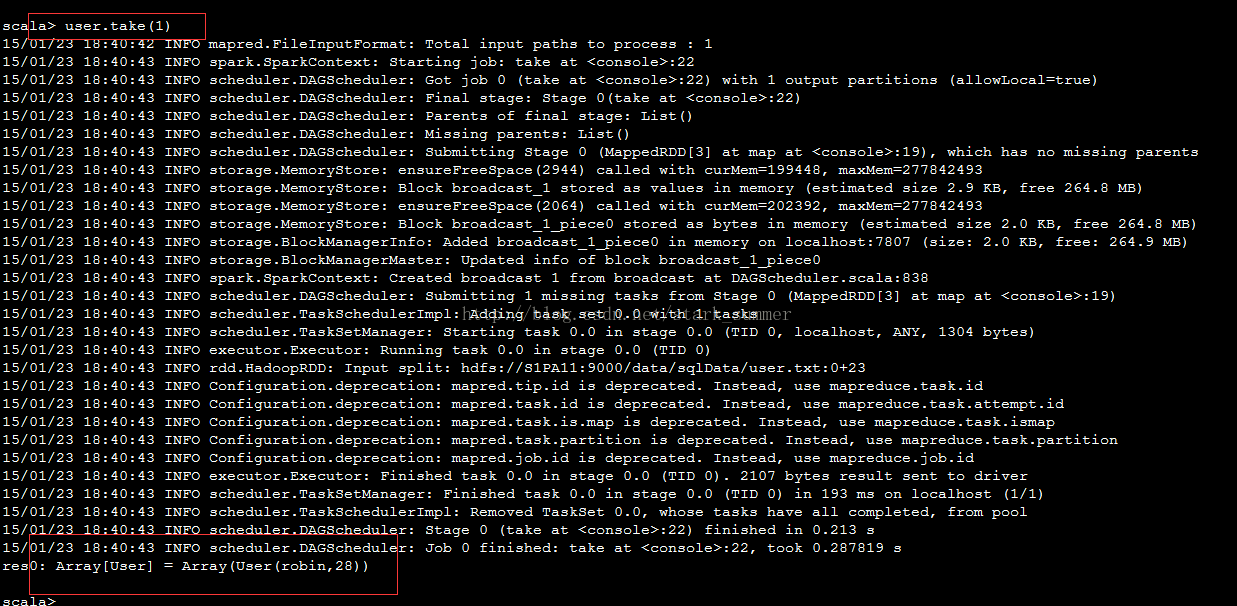
我们这次直接使用SQL查询操作:

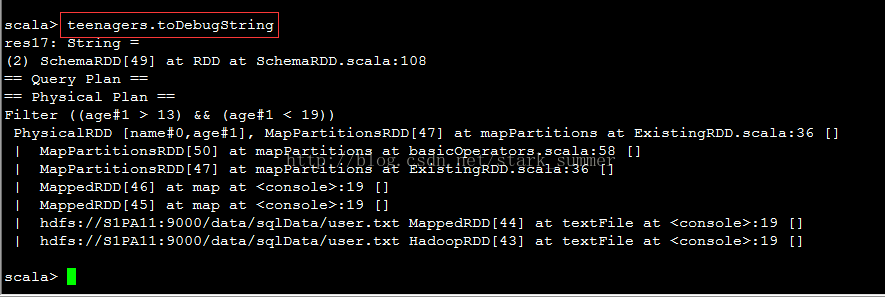
使用toDebugString查看下结果:
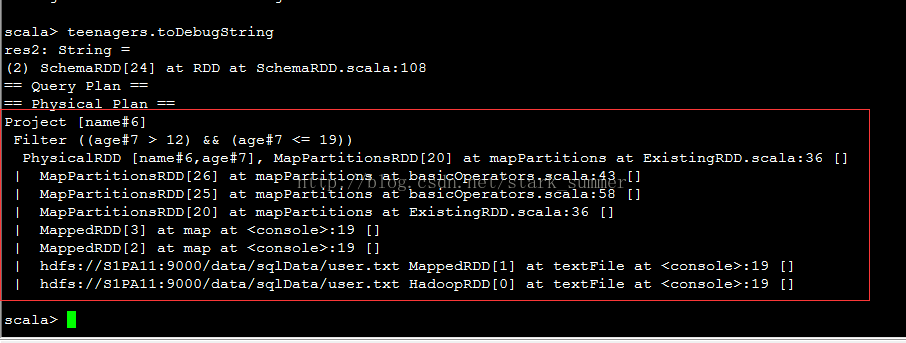
可以发现使用DSL的使用teenagers在内部已经被隐身转换了SchemaRDD的实例
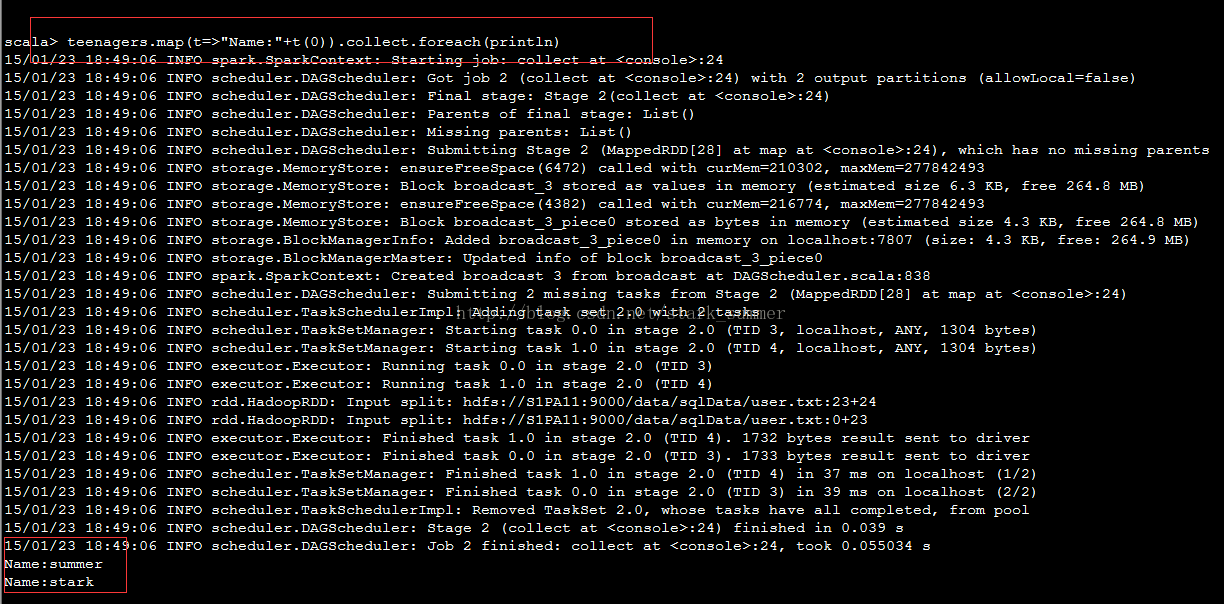
可以发现与前面那张注册Table方式的结果是一样的
标签:
原文地址:http://my.oschina.net/u/230960/blog/381397