标签:java并发容器
早期同步容器问题
Java库本身就有多种线程安全的容器和同步工具,其中同步容器包括两部分:一个是Vector和Hashtable。另外还有JDK1.2中加入的同步包装类,这些类都是由Collections.synchronizedXXX工厂方法。同步容器都是线程安全的,但是对于复合操作,还有些缺点:
① 迭代:在查觉到容器在迭代开始以后被修改,会抛出一个未检查异常ConcurrentModificationException,为了避免这个异常,需要在迭代期间,持有一个容器锁。但是锁的缺点也很明显,就是对性能的影响。
② 隐藏迭代器:StringBuilder的toString方法会通过迭代容器中的每个元素,另外容器的hashCode和equals方法也会间接地调用迭代。类似地,contailAll、removeAll、retainAll方法,以及容器作为参数的构造函数,都会对容器进行迭代。
③ 缺少即加入等一些复合操作
public static Object getLast(Vector list) {
int lastIndex = list.size() - 1;
return list.get(lastIndex);
}
public static void deleteLast(Vector list) {
int lastIndex = list.size() - 1;
list.remove(lastIndex);
}getLast和deleteLast都是复合操作,由先前对原子性的分析可以判断,这依然存在线程安全问题,有可能会抛出ArrayIndexOutOfBoundsException的异常,错误产生的逻辑如下所示:
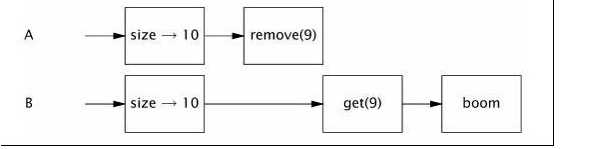
解决办法就是通过对这些复合操作加锁
正是由于同步容器类有以上问题,导致这些类成了鸡肋,于是Java 5推出了并发容器类,Map对应的有ConcurrentHashMap,List对应的有CopyOnWriteArrayList。与同步容器类相比,它有以下特性:
· 更加细化的锁机制。同步容器直接把容器对象做为锁,这样就把所有操作串行化,其实这是没必要的,过于悲观,而并发容器采用更细粒度的锁机制,名叫分离锁,保证一些不会发生并发问题的操作进行并行执行
· 附加了一些原子性的复合操作。比如putIfAbsent方法
· 迭代器的弱一致性,而非“及时失败”。它在迭代过程中不再抛出Concurrentmodificationexception异常,而是弱一致性。
· 在并发高的情况下,有可能size和isEmpty方法不准确,但真正在并发环境下这些方法也没什么作用。
· 另外,它还有一些附加的原子操作,缺少即加入、相等便移除、相等便替换。
putIfAbsent(K key, V value),缺少即加入(如果该键已经存在,则不加入) 如果指定键已经不再与某个值相关联,则将它与给定值关联。
类似于下面的操作
If(!map.containsKey(key)){
return map.put(key,value);
}else{
return map.get(key);
}remove(Object key, Object value),相等便移除 只有目前将键的条目映射到给定值时,才移除该键的条目。
类似于下面的:
if(map.containsKey(key) && map.get(key).equals(value)){
Map.remove();
return true;
}else{
return false;
}replace(K key, V oldValue, V newValue),相等便替换。 只有目前将键的条目映射到某一值时,才替换该键的条目。
上面提到的三个,都是原子的。在一些缓存应用中可以考虑代替HashMap/Hashtable。
· CopyOnWriteArrayList采用写入时复制的方式避开并发问题。这其实是通过冗余和不可变性来解决并发问题,在性能上会有比较大的代价,但如果写入的操作远远小于迭代和读操作,那么性能就差别不大了。
应用它们的场合通常在数组相对较小,并且遍历操作的数量大大超过可变操作的数量时,这种场合应用它们非常好。它们所有可变的 操作都是先取得后台数组的副本,对副本进行更改,然后替换副本,这样可以保证永远不会抛出 ConcurrentModificationException移除。
Java中的队列接口就是Queue,它有会抛出异常的add、remove方法,在队尾插入元素以及对头移除元素,还有不会抛出异常的,对应的offer、poll方法。
List实现了deque接口以及List接口,可以将它看做是这两种的任何一种。
Queue queue=new LinkedList();
queue.offer("testone");
queue.offer("testtwo");
queue.offer("testthree");
queue.offer("testfour");
System.out.println(queue.poll());一个基于优先级堆(简单的使用链表的话,可能插入的效率会比较低O(N))的无界优先级队列。优先级队列的元素按照其自然顺序进行排序,或者根据构造队列时提供的 Comparator 进行排序,具体取决于所使用的构造方法。优先级队列不允许使用 null 元素。依靠自然顺序的优先级队列还不允许插入不可比较的对象。
queue=new PriorityQueue();
queue.offer("testone");
queue.offer("testtwo");
queue.offer("testthree");
queue.offer("testfour");
System.out.println(queue.poll());基于链节点的,线程安全的队列。并发访问不需要同步。在队列的尾部添加元素,并在头部删除他们。所以只要不需要知道队列的大小,并发队列就是比较好的选择。
生产者和消费者模式,生产者不需要知道消费者的身份或者数量,甚至根本没有消费者,他们只负责把数据放入队列。类似地,消费者也不需要知道生产者是谁,以及是谁给他们安排的工作。
而Java知道大家清楚这个模式的并发复杂性,于是乎提供了阻塞队列(BlockingQueue)来满足这个模式的需求。阻塞队列说起来很简单,就是当队满的时候写线程会等待,直到队列不满的时候;当队空的时候读线程会等待,直到队不空的时候。实现这种模式的方法很多,其区别也就在于谁的消耗更低和等待的策略更优。以LinkedBlockingQueue的具体实现为例,它的put源码如下:
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
int c = -1;
final ReentrantLock putLock = this.putLock;
final AtomicInteger count = this.count;
putLock.lockInterruptibly();
try {
try {
while (count.get() == capacity)
notFull.await();
} catch (InterruptedException ie) {
notFull.signal();
// propagate to a non-interrupted thread
throw ie;
}
insert(e);
c = count.getAndIncrement();
if (c + 1 < capacity)
notFull.signal();
} finally {
putLock.unlock();
}
if (c == 0)
signalNotEmpty();
}撇开其锁的具体实现,其流程就是我们在操作系统课上学习到的标准生产者模式,看来那些枯燥的理论还是有用武之地的。其中,最核心的还是Java的锁实现,有兴趣可以再进一步深究一下。
阻塞队列Blocking queue,提供了可阻塞的put和take方法,他们与可定时的offer和poll方法是等价。Put方法简化了处理,如果是有界队列,那么当队列满的时候,生成者就会阻塞,从而改消费者更多的追赶速度。

FIFO的队列,与LinkedList(由链节点支持,无界)和ArrayList(由数组支持,有界)相似(Linked有更好的插入和移除性能,Array有更好的查找性能,考虑到阻塞队列的特性,移除头部,加入尾部,两个都区别不大),但是却拥有比同步List更好的并发性能。
另外,LinkedList永远不会等待,因为他是无界的。
BlockingQueue<String> queue=new ArrayBlockingQueue<String>(5);
Producer p=new Producer(queue);
Consumer c1=new Consumer(queue);
Consumer c2=new Consumer(queue);
new Thread(p).start();
new Thread(c1).start();
new Thread(c2).start();
/**
* 生产者
* @author Administrator
*
*/
class Producer implements Runnable {
private final BlockingQueue queue;
Producer(BlockingQueue q) { queue = q; }
public void run() {
try {
for(int i=0;i<100;i++){
queue.put(produce());
}
} catch (InterruptedException ex) {}
}
String produce() {
String temp=""+(char)(‘A‘+(int)(Math.random()*26));
System.out.println("produce"+temp);
return temp;
}
}
/**
* 消费者
* @author Administrator
*
*/
class Consumer implements Runnable {
private final BlockingQueue queue;
Consumer(BlockingQueue q) { queue = q; }
public void run() {
try {
for(int i=0;i<100;i++){
consume(queue.take());
}
} catch (InterruptedException ex) {}
}
void consume(Object x) {
System.out.println("cousume"+x.toString());
}
}
输出:
produceK
cousumeK
produceV
cousumeV
produceQ
cousumeQ
produceI
produceD
produceI
produceG
produceA
produceE
cousumeD一个按优先级堆支持的无界优先级队列,如果不希望按照FIFO的顺序进行处理,它非常有用。它可以比较元素本身的自然顺序,也可以使用一个Comparator排序。
一个优先级堆支持的,基于时间的调度队列。加入到队列中的元素必须实现新的Delayed接口(只有一个方法,Long getDelay(java.util.concurrent.TimeUnit unit)),添加可以理立即返回,但是在延迟时间过去之前,不能从队列中取出元素,如果多个元素的延迟时间已到,那么最早失效链接/失效时间最长的元素将第一个取出。
static class NanoDelay implements Delayed{
long tigger;
NanoDelay(long i){
tigger=System.nanoTime()+i;
}
public boolean equals(Object other){
return ((NanoDelay)other).tigger==tigger;
}
/**
* 返回此对象相关的剩余延迟时间,零或负值指示延迟时间已经用尽
*/
public long getDelay(TimeUnit unit) {
long n=tigger-System.nanoTime();
return unit.convert(n, TimeUnit.NANOSECONDS);
}
public long getTriggerTime(){
return tigger;
}
/**
* 相互比较,看谁的实效时间最长,谁先出去
*/
public int compareTo(Delayed o) {
long i=tigger;
long j=((NanoDelay)o).tigger;
if(i<j){
return -1;
}
if(i>j)
return 1;
return 0;
}
}
public static void main(String[] args) throws InterruptedException{
Random random=new Random();
DelayQueue<NanoDelay> queue=new DelayQueue<NanoDelay>();
for(int i=0;i<5;i++){
queue.add(new NanoDelay(random.nextInt(1000)));
}
long last=0;
for(int i=0;i<5;i++){
NanoDelay delay=(NanoDelay)(queue.take());
long tt=delay.getTriggerTime();
System.out.println("Trigger time:"+tt);
if(i!=0){
System.out.println("Data: "+(tt-last));
}
last=tt;
}
}不是一个真正的队列,因为它不会为队列元素维护任何存储空间,不过它维护一个排队的线程清单,这些线程等待把元素加入(enqueue)队列或者移出(dequeue)队列。也就是说,它非常直接的移交工作,减少了生产者和消费者之间移动数据的延迟时间,另外,也可以更快的知道反馈信息,当移交被接受时,它就知道消费者已经得到了任务。
因为SynChronousQueue没有存储的能力,所以除非另一个线程已经做好准备,否则put和take会一直阻止。它只有在消费者比较充足的时候比较合适。
JAVA6中新增了两个容器Deque和BlockingDeque,他们分别扩展了Queue和BlockingQueue。Deque它是一个双端队列,允许高效的在头和尾分别进行插入和删除,它的实现分别是ArrayDeque和LinkedBlockingQueue。
双端队列使得他们能够工作在一种称为“窃取工作”的模式上面。
1..同步的(synchronized)+HashMap,如果不存在,则计算,然后加入,该方法需要同步。
HashMap cache=new HashMap();
public synchronized V compute(A arg){
V result=cace.get(arg);
if(result==null){
result=c.compute(arg);
cache.put(result);
}
return result;
}2.用ConcurrentHashMap代替HashMap+同步.,这样的在get和set的时候也基本能保证原子性。但是会带来重复计算的问题.
Map<A,V> cache=new ConcurrentHashMap<A,V>();
public V compute(A arg){
V result=cace.get(arg);
if(result==null){
result=c.compute(arg);
cache.put(result);
}
return result;
}3.采用FutureTask代替直接存储值,这样可以在一开始创建的时候就将Task加入
Map<A,FutureTask<V>> cache=new ConcurrentHashMap<A,FutureTask<V>>();
public V compute(A arg){
FutureTask <T> f=cace.get(arg);
//检查再运行的缺陷
if(f==null){
Callable<V> evel=new Callable(){
Public V call() throws ..{
return c.compute(arg);
}
};
FutureTask <T> ft=new FutureTask<T>(evel);
f=ft;
cache.put(arg,ft;
ft.run();
}
Try{
//阻塞,直到完成
return f.get();
}cach(){
}
}4.上面还有检查再运行的缺陷,在高并发的情况下啊,双方都没发现FutureTask,并且都放入Map(后一个被前一个替代),都开始了计算。
这里的解决方案在于,当他们都要放入Map的时候,如果可以有原子方法,那么已经有了以后,后一个FutureTask就加入,并且启动。
public V compute(A arg){
FutureTask <T> f=cace.get(arg);
//检查再运行的缺陷
if(f==null){
Callable<V> evel=new Callable(){
Public V call() throws ..{
return c.compute(arg);
}
};
FutureTask <T> ft=new FutureTask<T>(evel);
f=cache.putIfAbsent(args,ft); //如果已经存在,返回存在的值,否则返回null
if(f==null){f=ft;ft.run();} //以前不存在,说明应该开始这个计算
else{ft=null;} //取消该计算
}
Try{
//阻塞,直到完成
return f.get();
}cach(){
}
}5.上面的程序上来看已经完美了,不过可能带来缓存污染的可能性。如果一个计算被取消或者失败,那么这个键以后的值永远都是失败了;一种解决方案是,发现取消或者失败的task,就移除它,如果有Exception,也移除。
6.另外,如果考虑缓存过期的问题,可以为每个结果关联一个过期时间,并周期性的扫描,清除过期的缓存。(过期时间可以用Delayed接口实现,参考DelayQueue,给他一个大于当前时间XXX的时间,,并且不断减去当前时间,直到返回负数,说明延迟时间已到了。)
java并发容器(Map、List、BlockingQueue)
标签:java并发容器
原文地址:http://zlfwmm.blog.51cto.com/5892198/1636307