标签:
今天早上起来,第一件事情就是理一理今天该做的事情,瞬间get到任务,写一个只用python字符串内建函数的爬虫,定义为v1.0,开发中的版本号定义为v0.x。数据存放?这个是一个练手的玩具,就写在txt文本里吧。其实主要的不是学习爬虫,而是依照这个需求锻炼下自己的编程能力,最重要的是要有一个清晰的思路(我在以这个目标努力着)。ok,主旨已经订好了,开始‘撸串’了。
目标网站:http://bohaishibei.com/post/category/main/(一个很有趣的网站,一段话配一个图,老有意思了~)网站形式如下:
目标:把大的目标分为几个小的目标。因为第一次干这个,所以对自己能力很清楚,所以完成顺序由简单到复杂。
1.爬取一期的内容,包括标题,和图片的url
2.把数据存在本地的txt文件中
3.想爬多少就爬就爬少
4.写一个网站,展示一下。(纯用于学习)
Let‘s 搞定它!
时间——9:14
把昨天晚上做的事情交代一下。昨天晚上写的代码实现了爬取一期里的所有标题。
第一步:
我用的是google浏览器,进入开发者模式,使用’页面内的元素选择器‘,先看一下内页中的结构,找到我们要的数据所在’标签‘。
这里我们需要的博海拾贝一期的内容全部在<article class="article-content">这个标签里面,如下图:
第一条红线是:页面内的元素选择器
第二条是:内容所在标签
第三条是:title
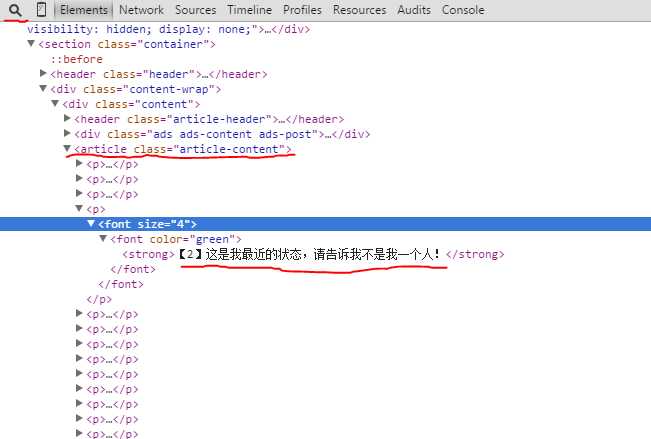
经过分析得出,我只要<article class="article-content">,这个标签的内容:所以写了下面的方法:
def content(html):
# 内容分割的标签
str = ‘<article class="article-content">‘
content = html.partition(str)[2]
str1 = ‘<div class="article-social">‘
content = content.partition(str1)[0]
return content # 得到网页的内容
这里需要说一下:在写这个爬虫之前我就打算只用字符串的内置函数来处理匹配问题,所以我就上http://www.w3cschool.cc/python/进入到字符串页面,大致看了一遍字符串的内建函数有哪些。
partition() 方法用来根据指定的分隔符将字符串进行分割。
如果字符串包含指定的分隔符,则返回一个3元的元组,第一个为分隔符左边的子串,第二个为分隔符本身,第三个为分隔符右边的子串。
partition() 方法是在2.5版中新增的。参考:http://www.w3cschool.cc/python/att-string-partition.html
这样我就得到只有内容的字符串了,干净~
第二步:
得到title的内容。title的格式如下,我只要’【2】‘后面的文字,后面的img暂时不考虑一步步的来。
<p>【2】这是我最近的状态,请告诉我不是我一个人!</p><p><img src=http://ww4.sinaimg.cn/mw690/005CfBldtw1etay8ifthnj30an0aot8w.jpg /></p><p>
我写了下面的方法:
def title(content,beg = 0):
# 思路是利用str.index()和序列的切片
try:
title_list = []
while True:
num1 = content.index(‘】‘,beg)
num2 = content.index(‘</p>‘,num1)
title_list.append(content[num1:num2])
beg = num2
except ValueError:
return title_list
这里用try....except是因为我不知道怎么跳出循环。。。。求大神有更好的方法告诉我。
我这里跳出循环用的是当抛出VlaueError异常就说明找不到了,那就返回列表。就跳出循环了。
num1是】的位置,num2是</p>的位置,然后用序列的切片,咔嚓咔嚓一下就是我想要的数据了。这里需要注意的是:切片’要头不要尾‘所以我们的得到的数据就是这个样子的:
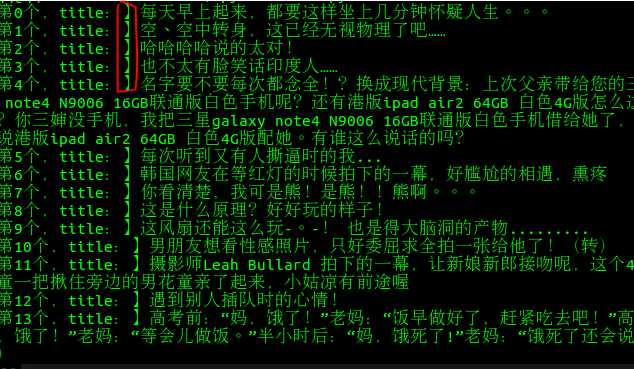
哎呀,这个是什么鬼!要头不要尾就是这个意思!
然后我就想:那就把num1加1不就完了吗?我真是太天真了。。。。
请+3,我觉得原理是这样的,这个是个中文字符!(求大神指点)
第三步:
交代清楚我昨天晚上做的事情了,记录下时间——10:01,下面我要爬图片的url了。这里要说一下,如果要把图片下下来,最重要的一步就是得到url,然后下载下来保存到本地(用文本的IO)。
我先获得url,实现原理同获取title,我在想,既然一样卸载获取title的方法里好,还是在写一个方法好。我单独写了一个方法,但是其实就是复制了一下title的方法,改了下匹配的字符串,代码如下:
def img(content,beg = 0):
# 思路是利用str.index()和序列的切片
try:
img_list = []
while True:
src1 = content.index(‘http‘,beg)
src2 = content.index(‘/></p>‘,src1)
img_list.append(content[src1:src2])
beg = src2
except ValueError:
return img_list
结果图如下:
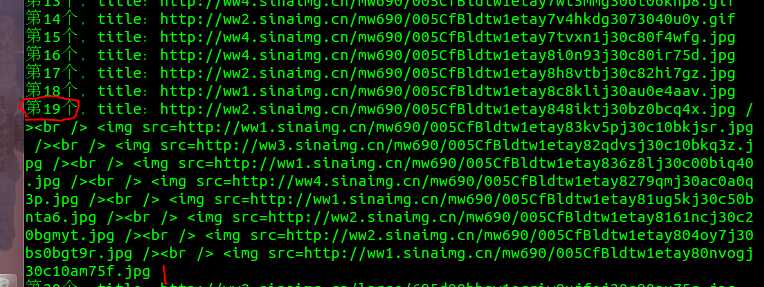
这里发现,有的时候一个title会有很多个图片。我思考之后有如下思路:
1.需要写一个方法,当一个title出现多个图片的时候,捕获url。这个需要有一个判断语句,当url长度大于一个url长度的时候,才需要调用这个函数。
2.多个图片的url怎么放?使用符号隔开存放还是嵌套放入一个数组里面?我这里打算用’|‘隔开,这样的话加一个判语句,或者先判断一下url长度,都可以进行。
这个问题先放在这里,因为当我要下载的时候这个url才需要过滤,所以先进行下一步,把数据存到本地txt文中,这里在解决这个问题也不晚。
第四步:
把数据存到本地的txt中。Python文件IO参考资料:http://www.w3cschool.cc/python/python-files-io.html
这里需要注意的是,文本写入的时候记得close,还有就是注意打开文本的模式。
时间——11:05 吃个饭先
时间——11:44 回来了
这里我考虑了一个问题,根据《编写高质量代码——改善python程序的91个建议》这本书中写道的,字符串连接时,用jion()效率高于’+‘
所以我写了如下代码:
def data_out(data):
#这里写成一个方法好处是,在写入文本的时候就在这里写
fo = open("/home/qq/foo.txt", "a+")
#for i,e in enumerate(data):
fo.write("\n".join(data));
#print ‘第%d个,title:%s‘ % (i,e)
# 关闭打开的文件
fo.close()
这样造成了一个问题,看图
造成最后一个和新的一个列表写入时在同一行。同时用with....as更好。修改后代码如下:
def data_out(data):
#写入文本
with open("/home/qq/foo.txt", "a+") as fo:
fo.write(‘\n‘)
fo.write("\n".join(data));
下面研究title和img以什么样的格式存入txt文本:
title$img
这里我有一个概念混淆了,+和join()方法的效率问题主要在连接多个字符串的时候,我这个只用连接一次,不需要考虑这个问题。
def data_out(title, img):
#写入文本
with open("/home/qq/foo.txt", "a+") as fo:
fo.write(‘\n‘)
size = 0
for size in range(0, len(title)):
fo.write(title[size]+‘$‘+img[size]+‘\n‘);
文本中的内容如下:
愿你贪吃不胖,愿你懒惰不丑,愿你深情不被辜负。$http://ww1.sinaimg.cn/mw690/005CfBldtw1etay8dl1bsj30c50cbq4m.jpg"
这是我最近的状态,请告诉我不是我一个人!$http://ww4.sinaimg.cn/mw690/005CfBldtw1etay8ifthnj30an0aot8w.jpg
引诱别人和你击拳庆祝,然后偷偷把手势变成二,就可以合体成为蜗牛cosplay……$http://ww2.sinaimg.cn/mw690/005CfBldtw1etay8fzm1sg30b40644qq.gif
原来蜗牛是酱紫吃东西的。。。。涨姿势!$http://ww4.sinaimg.cn/mw690/005CfBldtw1etay8egg8vg30bo08ax6p.gif
写入文本的最后,解决多个图片的问题:
def many_img(data,beg = 0):
#用于匹配多图中的url
try:
many_img_str = ‘‘
while True:
src1 = data.index(‘http‘,beg)
src2 = data.index(‘ /><br /> <img src=‘,src1)
many_img_str += data[src1:src2]+‘|‘ # 多个图片的url用"|"隔开
beg = src2
except ValueError:
return many_img_str
def data_out(title, img):
#写入文本
with open("/home/qq/data.txt", "a+") as fo:
fo.write(‘\n‘)
for size in range(0, len(title)):
# 判断img[size]中存在的是不是一个url
if len(img[size]) > 70:
img[size] = many_img(img[size])# 调用many_img()方法
fo.write(title[size]+‘$‘+img[size]+‘\n‘)
输出如下:
元气少女陈意涵 by @TopFashionStyle$http://ww2.sinaimg.cn/mw690/005CfBldtw1etay848iktj30bz0bcq4x.jpg|http://ww1.sinaimg.cn/mw690/005CfBldtw1etay83kv5pj30c10bkjsr.jpg|http://ww3.sinaimg.cn/mw690/005CfBldtw1etay82qdvsj30c10bkq3z.jpg|http://ww1.sinaimg.cn/mw690/005CfBldtw1etay836z8lj30c00biq40.jpg|http://ww4.sinaimg.cn/mw690/005CfBldtw1etay8279qmj30ac0a0q3p.jpg|http://ww1.sinaimg.cn/mw690/005CfBldtw1etay81ug5kj30c50bnta6.jpg|http://ww2.sinaimg.cn/mw690/005CfBldtw1etay8161ncj30c20bgmyt.jpg|http://ww2.sinaimg.cn/mw690/005CfBldtw1etay804oy7j30bs0bgt9r.jpg|
暂时功能是实现了,后面遇到问题需要修改在改吧。。。。新手走一步看一步!!!
到此为止,已经完成了前两个简单的计划:
1.爬取一期的内容,包括标题,和图片的url
2.把数据存在本地的txt文件中
全部代码如下:
#coding:utf-8
import urllib
######
#爬虫v0.1 利用urlib 和 字符串内建函数
######
def getHtml(url):
# 获取网页内容
page = urllib.urlopen(url)
html = page.read()
return html
def content(html):
# 内容分割的标签
str = ‘<article class="article-content">‘
content = html.partition(str)[2]
str1 = ‘<div class="article-social">‘
content = content.partition(str1)[0]
return content # 得到网页的内容
def title(content,beg = 0):
# 匹配title
# 思路是利用str.index()和序列的切片
try:
title_list = []
while True:
num1 = content.index(‘】‘,beg)+3
num2 = content.index(‘</p>‘,num1)
title_list.append(content[num1:num2])
beg = num2
except ValueError:
return title_list
def get_img(content,beg = 0):
# 匹配图片的url
# 思路是利用str.index()和序列的切片
try:
img_list = []
while True:
src1 = content.index(‘http‘,beg)
src2 = content.index(‘/></p>‘,src1)
img_list.append(content[src1:src2])
beg = src2
except ValueError:
return img_list
def many_img(data,beg = 0):
#用于匹配多图中的url
try:
many_img_str = ‘‘
while True:
src1 = data.index(‘http‘,beg)
src2 = data.index(‘ /><br /> <img src=‘,src1)
many_img_str += data[src1:src2]+‘|‘ # 多个图片的url用"|"隔开
beg = src2
except ValueError:
return many_img_str
def data_out(title, img):
#写入文本
with open("/home/qq/data.txt", "a+") as fo:
fo.write(‘\n‘)
for size in range(0, len(title)):
# 判断img[size]中存在的是不是一个url
if len(img[size]) > 70:
img[size] = many_img(img[size])# 调用many_img()方法
fo.write(title[size]+‘$‘+img[size]+‘\n‘)
content = content(getHtml("http://bohaishibei.com/post/10475/"))
title = title(content)
img = get_img(content)
data_out(title, img)
# 实现了爬的单个页面的title和img的url并存入文本
时间——15:14
下面要重新分析网站,我已经可以获得一期的内容了,我现在要得到,其它期的url,这样就想爬多少就爬多少了。
目标网址:http://bohaishibei.com/post/category/main/
按照上面的方法进入开发者模式分析网站结构,找出目标数据所在的标签,撸它!
在首页中需要的数据全部都在<div class="content">标签里,分隔方法如下:
def main_content(html):
# 首页内容分割的标签
str = ‘<div class="content">‘
content = html.partition(str)[2]
str1 = ‘</div>‘
content = content.partition(str1)[0]
return content # 得到网页的内容
我暂时需要的数据:每一期的名字和每一期的url。
经过我的分析:该网站的每期的url格式是这样的:"http://bohaishibei.com/post/10189/"只有数字是变化的。
后来我又发现,我想要的这两个数据都在<h2>这个标签下面,获取每期url的方法如下:
def page_url(content, beg = 0):
try:
url = []
while True:
url1 = content.index(‘<h2><a href="‘,beg)+13
url2 = content.index(‘" ‘,url1)
url.append(content[url1:url2])
beg = url2
except ValueError:
return url
title的格式,
我思考了一下,我要title其实没什么太大的意思,用户有不可能说我要看那期,只需要输入看多少期就可以了,标题没有什么实际意义(不像内容中的title是帮助理解改张图笑点的)。所以我打算在这个版本中只实现,你输入想查看要多少期,就返回多少期!
那么下面就需要一个策略了:
http://bohaishibei.com/post/category/main/ 共20期
http://bohaishibei.com/post/category/main/page/2/ 共20期
......
经查看,每页都是20期
当你要查看的期数,超过20期的时候需要,增加page的数值,进入下一页进行获取
最后一页为这个:http://bohaishibei.com/post/category/main/page/48/
实现代码,这个我要想一想怎么写,我是第一次写爬虫,不要嘲讽我啊!
时间——17:09
感觉快实现了,还在写:
def get_order(num): page = num / 20 order = num % 20 # 超出一整页的条目 for i in range(1, page+1): # 需这里需要尾巴 url = ‘http://bohaishibei.com/post/category/main/page/%d‘ % i print url if (i == page)&(order > 0): url = ‘http://bohaishibei.com/post/category/main/page/%d‘ % (i+1) print url+",%d条" % order
get_order(55)
运行结果:
http://bohaishibei.com/post/category/main/page/1
http://bohaishibei.com/post/category/main/page/2
http://bohaishibei.com/post/category/main/page/3,15条
2
~~~~~~~~~~~~
15
这里我考虑是这样的我需要重写 page_url,需要多加一个参数,如下:
未完待续@!!
标签:
原文地址:http://www.cnblogs.com/xueweihan/p/4592212.html