标签:
Sequoiadb作为一个文档型NoSQL数据既可以存储结构化数据也可以存储非结构化数据,对于非结构化数据只能使用原生的API进行查询,对结构化数据我们可以选择使用原生的API和开源SQL引擎,目前PostgresSQL,Hive,SparkSQL都可以作为Sequoiadb的SQL引擎,应用中该如何选择?
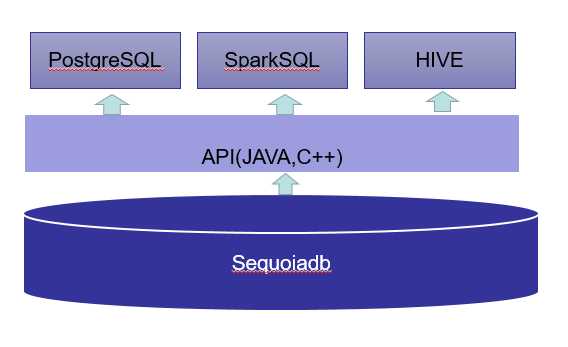
首先需要了解这些SQL引擎是怎么工作的,下图是Sequoiadb的接口图,所有的SQL查询都是通过SQL引擎把SQL解析成原生API的调用,PG依赖c++驱动,SparkSQL和HIVE依赖Java驱动
首先我们谈一谈PG,PG通过创建外部表的形式用来读写Sequoiadb中的数据,支持标准SQL和存储引擎,目前由于PG是单点,这就造成如果做多表关联,多个表的数据通过网络传输到PG所在的节点上进行关联计算,对IO和CPU的压力很大,SQL执行是很慢的,如果是对单表做操作性能是很快的,建议千万级别一下的数据使用PG做SQL引擎。
SparkSQL是构建在spark上面的一个SQL引擎,spark是一个分布式计算框架,sql通过sparksql的解析为执行任务在spark集群上执行,它没有单点的问题,充分利用数据所在节点上的计算资源,同时 sparkSQL的表数据在内存中存储不是采用原生态的JVM对象存储方式,而是采用内存列存储,该存储方式无论在空间占用量和读取吞吐率上都占有很大优势,更重要的是spark是多线程模型,Spark同节点上的任务以多线程的方式运行在一个JVM进程中,启动了thriftserver以后,一个sql对用spark的一个job,只需要在thriftserver所拥有的executor进程中生成线程来执行。
上面都是SparkSQL的优点,但是确定也有很多缺点,SparkSQL当一个SQL执行时间过长的话,后面的SQL都会卡住,这个资源问题后来虽然解决了,但是依然觉得不够完美,thriftserver --master 只能指定单个url,有单点的问题
目前项目中使用spark sql做数据的分析和查询,遇到很多问题,不过最终都解决了。
Hive把sql解析成mr任务,也是分布式计算,但是mr是进程级别的,没有sql都要启动JVM进程去执行,速度慢,在和sequoiadb对接过程中发现一个问题,在hive 0.13版本中会自行进行mapjoin .当数据量大的时候,笔者在做2kw数据和1kw数据做join时,报oom错误。所有需要set hive.auto.convert.join = false, 但是这带来一个问题就是速度非常的慢, 但是hive相对成熟,对于速度要求不高,节点内存比较小,同时机器上部署hadoop的用户可以使用hive
笔者最终选择了spark sql。
Sequoiadb该如何选择合适的SQL引擎
标签:
原文地址:http://www.cnblogs.com/gaoxing/p/4714196.html