标签:
背景
这一篇可以说是“Hive JSON数据处理的一点探索”的兄弟篇。
平台为了加速即席查询的分析效率,在我们的Hadoop集群上安装部署了Spark Server,并且与我们的Hive数据仓库共享元数据。也就是说,我们的用户即可以通过HiveServer2使用Hive SQL执行MapReduce分析数据,也可以使用SparkServer使用Spark SQL(Hive SQL)执行Spark Application分析数据。
两者除去MapReduce和Spark Application计算模式的不同之外,Spark Server的优势在于它的Container进程是常驻的,也就是说它的计算资源是预留的,接收到SQL语句之后可以立即执行,响应速度更加迅速。
既然Spark Server和HiveServer2共享元数据,我们应该能够在SQL层面最大限度地屏蔽两者之间的差异。虽然Spark官方声称兼容大多数Hive SQL语句,但实际使用当中却经常出现各种异常。
本文所要讨论的就是Spark SQL使用Hive内建函数json_tuple的异常问题。
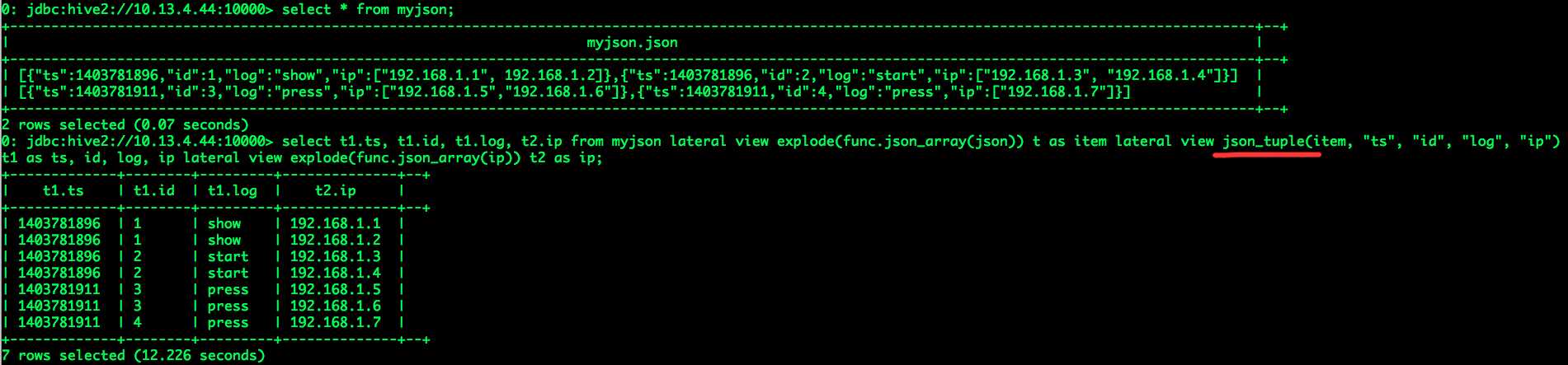
我们还是借用“Hive JSON数据处理的一点探索”中的示例数据表来说明问题。
(1)通过HiveServer2来执行Hive SQL语句;
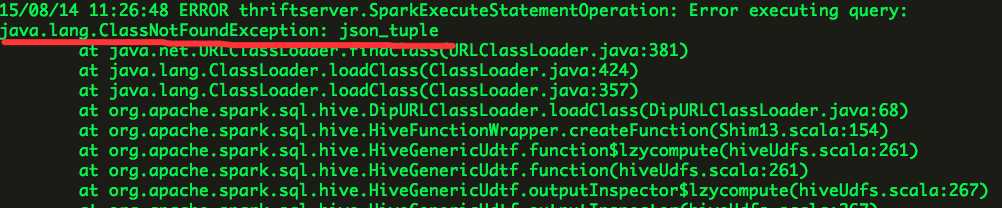
(2)通过Spark Server来执行Hive SQL语句;
终端异常信息为:Error: java.lang.ClassNotFoundException: json_tuple (state=,code=0)
Spark Server日志输出为:
怀疑的问题为找不到相应的jar包,其实实际问题是UDF解析类名错误,json_tuple为函数名称,其对应的类名应为org.apache.hadoop.hive.ql.udf.generic.GenericUDTFJSONTuple。
这个异常直接影响到我们使用Hive UDF json_tuple通过Spark Server分析JSON数据。
方案
为了达到“Hive JSON数据处理的一点探索”中数据表myjson最后的查询效果,我们需要使用Hive UDF get_json_object来实现,如下:
由get_tuple和func.json_array结合使用的方案变为get_json_object和func.json_array结合使用的方案。可以看出这种方案虽然繁杂,但可以应对实际问题。
Spark SQL JSON数据处理
标签:
原文地址:http://www.cnblogs.com/yurunmiao/p/4729702.html