标签:
现在,您已经完全地理解了物理和理论的局限性,可以开始学习不同类型的复制了。
我们可以做的第一个区分是同步复制和异步复制的区别。
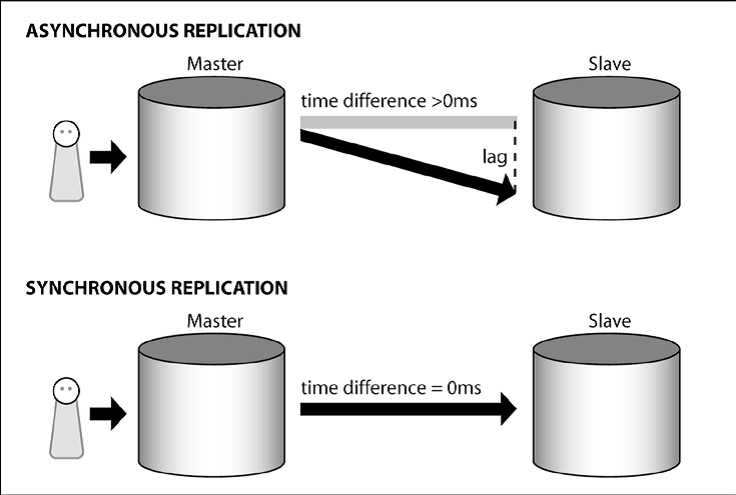
这是什么意思呢?假设我们有两台服务器,希望从一台服务器(the master)复制数据到第二台服务器(the slave)。下图说明了同步和异步复制的概念:
我们可以使用一个简单的事务如下所示:
BEGIN:
INSERT INTO foo VALUES (‘bar‘);
COMMIT;
在异步复制的情况下,事务被提交到master之后数据才可以被复制。换句话说,slave从不会超前master,就写操作而言,通常滞后于master一些。此延迟(delay)被称为滞后性(lag)。
同步复制强制执行了较高的一致性规则。如果您决定使用同步复制(如何做到这一点实际上将在第五章中讨论,建立同步流复制),系统必须确保通过事务写入的数据至少事务同时在两台服务器上提交。这意味着:slave 不滞后于master,而且终端用户在两台服务器上看到的数据是一致的。
[有些系统也将使用仲裁服务器来决定。因此,它不是总是关于只有两个或者更多的服务器。如果一个仲裁服务器被使用,超过一半的服务器必须同意集群内的行动。]
理解复制和数据丢失
当一个事务从master复制到slave,很多事情必须考虑到,尤其是当涉及到像数据丢失的事情。
假设我们正在以以下方式异步复制数据:
在异步复制的情况下,有一个窗口(滞后),在滞后窗口期间数据会丢失。滞后窗口的大小因设置类型的不同而不同。它的大小非常短(几毫秒)或非常长(几分钟,几小时,几天)。一个重要的事实是:数据可能丢失。一个小的滞后只会是数据丢失的可能性较小,但,任何大于零的滞后都容易导致数据丢失。
如果您想确保数据永远不丢失,您必须切换到同步复制。正如您在这个章节已经看到的,一个同步事务是同步的,因为如果事物提交到了两台服务器它是有效的。
考虑性能问题
正如您在关于光速和延迟章节所了解到的,通过网络发送不必要的消息的开销是昂贵的和费时的。如果一个事务采用同步的方式复制,PostgreSQL必须确保数据到达第二个节点,这样就会导致延迟问题。
在许多方面,同步复制比异步复制要昂贵很多,因此如果这种消耗确实需要和调整,人们应该三思而后行。(只在需要的时候使用同步复制)
[当真的需要的时候,才使用同步复制。]
各种复制设置的第二种分类方法是单masster复制和多master复制。
单master意味着写操作只能发送到一个服务器,该服务器分配数据到内部设置的slave上。slave只能接收读操作但是不会接收写操作。
相对于单master复制,多master复制允许写操作发送到所有集群内部的服务器。下图显示了系统如何在一个概念层面工作:
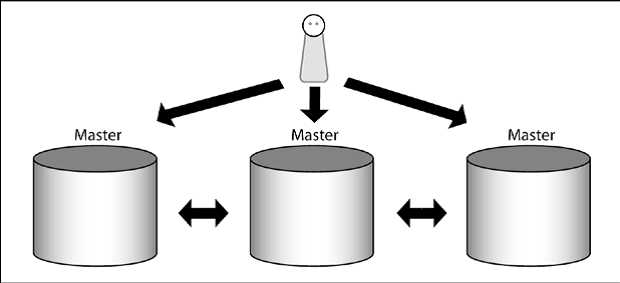
可以写到集群内部的任何节点听起来像一个优点,但它不是一个必须的优点。其原因是多master复制给系统添加了不少复杂性。在只有一个master的情况下,哪个数据是正确的,数据会流向哪个方向是非常清楚的,而且在复制过程中很少有冲突。多master复制是完全不同的,写操作可以同时被发送到多个节点,集群必须非常清楚冲突并妥善地处理它们。使用锁来解决这个问题是一个可供选择的方法,但这种方法会产生其自身的问题。
[请记住,解决冲突的需要会产生网络通信,并且这可以瞬间变成由延迟引起的可扩展性问题。]
分类复制的另一种方式是逻辑复制和物理复制之间进行的区分。
不同是细微的,但非常重要。物理复制指系统将移动数据到远程服务器。
因此,如果有东西被插入。远程服务器将获取数据的二进制格式,而不是通过SQL。
逻辑复制意味着一个变化,相当于即将到来的数据被复制。
让我们看一个例子,充分理解两者的差异:
test=# CREATE TABLE t_test (t date);
CREATE TABLE
test=# INSERT INTO t_test VALUES (now())
RETURNING *;
t
------------
2013-02-08
(1 row)
INSERT 0 1
我能看到这里执行了两个事务:第一个事务创建了一个表。一旦这个完成后,第二个事务向表里增加了一个简单的日期并提交。
在逻辑复制的情况下,改变将被以逻辑形式发送到某种队列,因此系统不发送普通的SQL,但也许是如下的东西:
test=# INSERT INTO t_test VALUES (‘2013-02-08‘);
INSERT 0 1
注意,函数调用已被替换为实际的值。如果slave重新计算now()函数,这将是一个巨大的灾难,因为在远程服务器的日期可能是一个完全不同的日期。
[有些系统把基于语句的复制作为核心技术。例如:MySQL使用一个所谓的bin-log来复制,这实际上并不是二进制,而是某种形式的逻辑复制。]
物理复制将工作在一个完全不同的方式:不是发送一些SQL(或其它),这在逻辑上是等价的,系统会发送PostgreSQL内部所做的二进制替代物。
下面是一些二进制替代物,我们的两个事务可能被触发(到目前为止,还不是一个完整的列表):
物理复制的目标是在相同的物理级别创建一个系统的副本。这意味着在所有的服务器上相同的数据将在您的表的相同的地方。在逻辑复制的情况下,但是不论内容是否在相同的地方,没有任何不同,内容应该是相同的。
何时使用物理复制
物理复制使用起来非常方便,尤其是容易建立。当目标是创建系统的相同副本(创建一个备份后,简单地扩展)时,物理复制被广泛使用。
在许多设置中,物理复制是标准的方法,该方法把尽可能最低的复杂性暴露给终端用户。它是理想的向外扩张数据的方法。
何时使用逻辑复制
通常逻辑复制的设置有点难,但它提供了更大的灵活性。当涉及到升级现有的数据库时,它也是特别地重要。物理复制完全不适合版本跳跃,因为您不能简单地依靠每个版本的PostgreSQL具有相同的磁盘布局的事实。存储格式可能会随时间而改变,因此二进制复制显然是不适合从一个版本跳跃到另一个版本的。
逻辑复制允许解耦合数据存储方式和数据传输,复制方式。通过使用中性协议,该协议并不和特定版本的PostgreSQL绑定,很容易从一个版本跳跃到另一个版本。
PostgreSQL Replication之第一章 理解复制概念(2)
标签:
原文地址:http://www.cnblogs.com/songyuejie/p/4743299.html